



现有系统是mysql版本,需要改成瀚高数据库。
使用瀚高迁移工具,将mysql的表和数据迁移到瀚高数据库中。
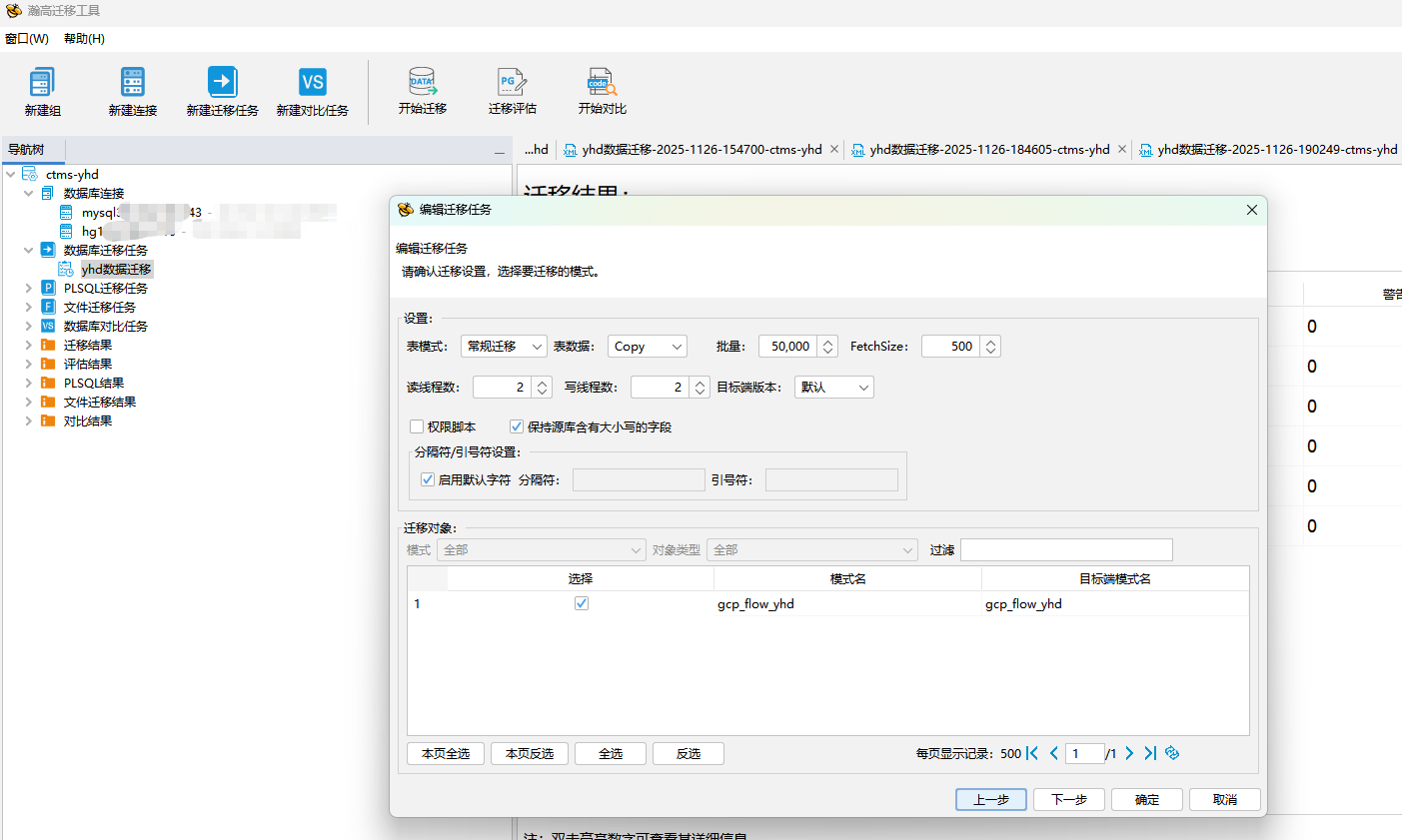
处理mysql表中自动递增id
查询mysql中的自增id
SELECT
t.TABLE_NAME AS 表名,
c.COLUMN_NAME AS 自增列名,
CONCAT('\'',t.TABLE_NAME, ':' ,c.COLUMN_NAME,'\','),
c.DATA_TYPE AS 数据类型,
t.AUTO_INCREMENT AS 当前自增起始值,
c.COLUMN_COMMENT AS 列注释
FROM
INFORMATION_SCHEMA.TABLES t
JOIN
INFORMATION_SCHEMA.COLUMNS c
ON
t.TABLE_SCHEMA = c.TABLE_SCHEMA
AND t.TABLE_NAME = c.TABLE_NAME
WHERE
t.TABLE_SCHEMA = DATABASE() -- 自动适配当前数据库
AND t.AUTO_INCREMENT IS NOT NULL
AND c.EXTRA LIKE '%auto_increment%';
在瀚高中添加存储过程seq_update,将mysql中的自增id全部列出来。
CREATE OR REPLACE PROCEDURE gcp_flow_yhd.seq_update()
LANGUAGE plpgsql
AS $procedure$
DECLARE
-- 定义需要处理的表和对应的主键字段名
-- 格式: 表名:主键字段名
tables_with_pk TEXT[] := ARRAY[
'ACT_EVT_LOG:LOG_NR_',
'ACT_HI_TSK_LOG:ID_',
'gen_table:table_id',
'gen_table_column:column_id',
'leave_application:id',
'study_queue:id',
'study_queue_patient:id',
...
'wx_project_standard:id'
];
tbl_info TEXT;
tbl_name TEXT;
pk_field TEXT;
seq_name TEXT;
start_id BIGINT;
sequence_exists BOOLEAN;
current_max_id BIGINT;
has_default BOOLEAN;
error_msg TEXT;
BEGIN
-- 记录开始时间
RAISE NOTICE '开始处理序列更新,共 % 个表', array_length(tables_with_pk, 1);
-- 遍历所有表
FOREACH tbl_info IN ARRAY tables_with_pk
LOOP
BEGIN
-- 解析表名和主键字段名
tbl_name := split_part(tbl_info, ':', 1);
pk_field := split_part(tbl_info, ':', 2);
-- 构建序列名(表名 + '_' + 主键字段名 + '_seq')
seq_name := tbl_name || '_' || pk_field || '_seq';
-- 获取表中当前最大ID
EXECUTE 'SELECT COALESCE(MAX(' || quote_ident(pk_field) || '), 0) FROM ' || quote_ident(tbl_name) INTO current_max_id;
start_id := current_max_id + 1;
-- 检查序列是否存在
SELECT EXISTS(
SELECT 1 FROM information_schema.sequences
WHERE sequence_name = seq_name
) INTO sequence_exists;
-- 检查表字段是否已经有默认值
SELECT EXISTS(
SELECT 1 FROM information_schema.columns
WHERE table_name = tbl_name
AND column_name = pk_field
AND column_default IS NOT NULL
AND column_default LIKE '%' || seq_name || '%'
) INTO has_default;
IF sequence_exists THEN
-- 序列已存在,修改起始值
EXECUTE 'ALTER SEQUENCE ' || quote_ident(seq_name) || ' RESTART WITH ' || start_id;
-- 确保默认值设置正确
IF NOT has_default THEN
EXECUTE 'ALTER TABLE ' || quote_ident(tbl_name) ||
' ALTER COLUMN ' || quote_ident(pk_field) || ' SET DEFAULT nextval(''' || seq_name || ''')';
END IF;
RAISE NOTICE '表 % 的序列已存在,起始值已修改为: %', tbl_name, start_id;
ELSE
-- 序列不存在,创建新序列
EXECUTE 'CREATE SEQUENCE ' || quote_ident(seq_name) ||
' START WITH ' || start_id || ' INCREMENT BY 1';
-- 设置表的默认值
EXECUTE 'ALTER TABLE ' || quote_ident(tbl_name) ||
' ALTER COLUMN ' || quote_ident(pk_field) || ' SET DEFAULT nextval(''' || seq_name || ''')';
RAISE NOTICE '表 % 的序列已创建,起始值: %', tbl_name, start_id;
END IF;
EXCEPTION
WHEN others THEN
-- 捕获异常并记录错误信息
GET STACKED DIAGNOSTICS error_msg = MESSAGE_TEXT;
RAISE NOTICE '处理表 % 时出错: %', tbl_name, error_msg;
-- 继续处理下一个表
CONTINUE;
END;
END LOOP;
RAISE NOTICE '序列更新处理完成';
END;
$procedure$
;
调用存储过程,更新瀚高表中的自增id字段
CALL xxx.seq_update();
项目中用到了flowable,需要处理相关表中的布尔类型字段
ALTER TABLE act_ru_execution
ALTER COLUMN is_active_ TYPE boolean USING (CASE WHEN is_active_ = 1 THEN true ELSE false END),
ALTER COLUMN is_concurrent_ TYPE boolean USING (CASE WHEN is_concurrent_ = 1 THEN true ELSE false END),
ALTER COLUMN is_scope_ TYPE boolean USING (CASE WHEN is_scope_ = 1 THEN true ELSE false END),
ALTER COLUMN is_event_scope_ TYPE boolean USING (CASE WHEN is_event_scope_ = 1 THEN true ELSE false END),
ALTER COLUMN is_mi_root_ TYPE boolean USING (CASE WHEN is_mi_root_ = 1 THEN true ELSE false END),
ALTER COLUMN is_count_enabled_ TYPE boolean USING (CASE WHEN is_count_enabled_ = 1 THEN true ELSE false END);
ALTER TABLE act_ru_task
ALTER COLUMN is_count_enabled_ TYPE boolean USING (CASE WHEN is_count_enabled_ = 1 THEN true ELSE false END);
ALTER TABLE act_ru_job
ALTER COLUMN exclusive_ TYPE boolean USING (CASE WHEN exclusive_ = 1 THEN true ELSE false END);
以上就将数据迁移到了瀚高中。
瀚高对字段类型要求严格,字符串类型的查询需要加单引号,数值类型的查询需要将字符串转为数值类型查询。

















 3450
3450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









