



 文章详细介绍了MySQL中创建、修改和删除索引的方法,强调了聚簇索引和辅助索引的概念及影响因素。建议创建时选择数字自增列为主键,并提到如何通过选择合适的数据类型、减少回表和优化查询条件来提高性能。还涵盖了查看索引信息、执行计划分析以及处理慢查询的策略。
文章详细介绍了MySQL中创建、修改和删除索引的方法,强调了聚簇索引和辅助索引的概念及影响因素。建议创建时选择数字自增列为主键,并提到如何通过选择合适的数据类型、减少回表和优化查询条件来提高性能。还涵盖了查看索引信息、执行计划分析以及处理慢查询的策略。
索引增加修改删除方式。
创建索引:
CREATE INDEX indexName ON table_name (column_name);
修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName);
ALTER 命令删除主键:
ALTER TABLE testalter_tbl DROP PRIMARY KEY;
一、mysql 聚簇索引含义
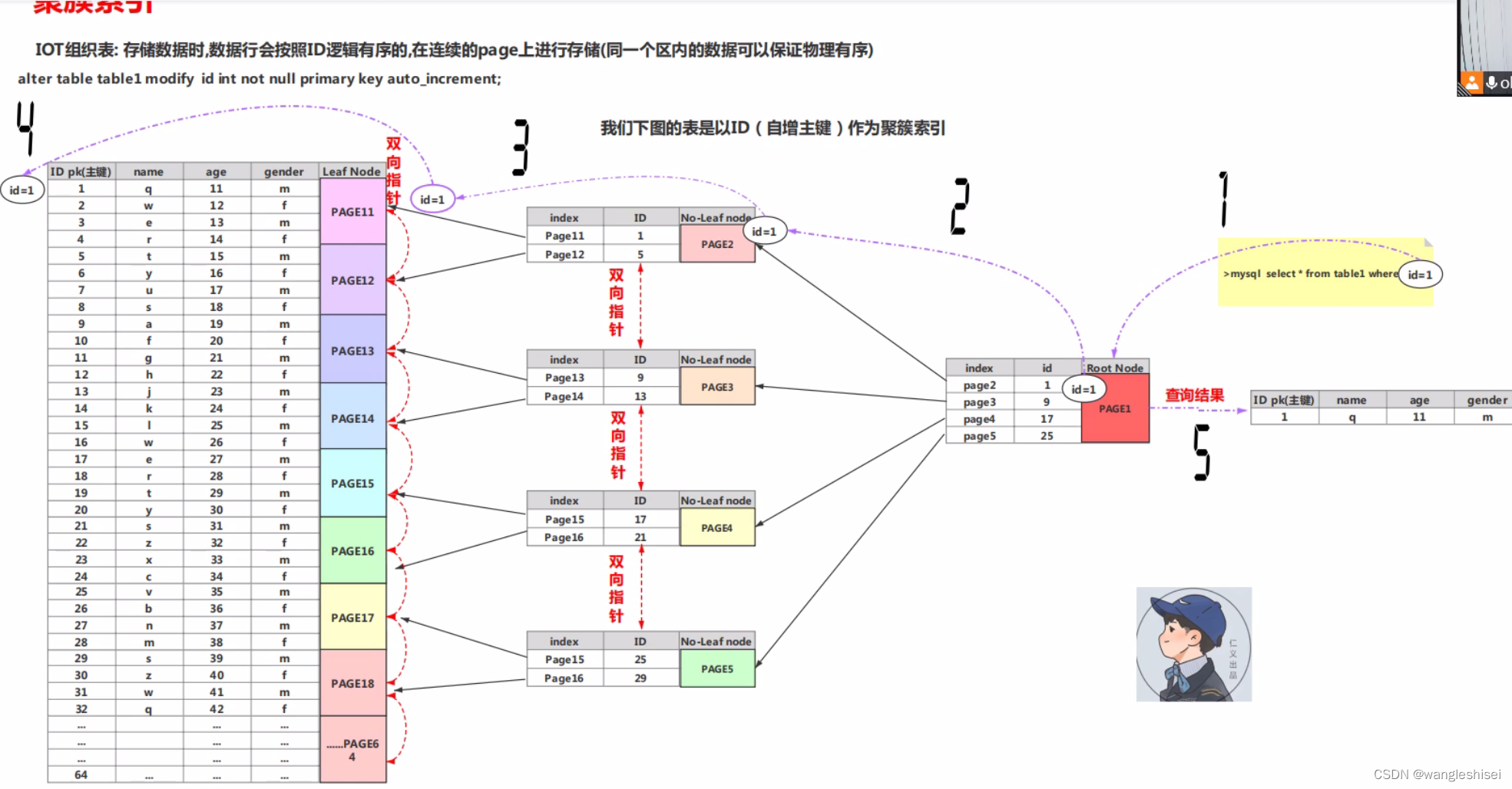
1、有主键选择主键为聚簇索引
2、没有主键选择不为空的唯一键索引
3、生成隐藏列 gen_clust_index。row id做为聚簇索引
**建议建表的时候。显示的创建主键。最好是数字自增列。
2、mysql 辅助索引(单列索引) (group 和 order by 排序)
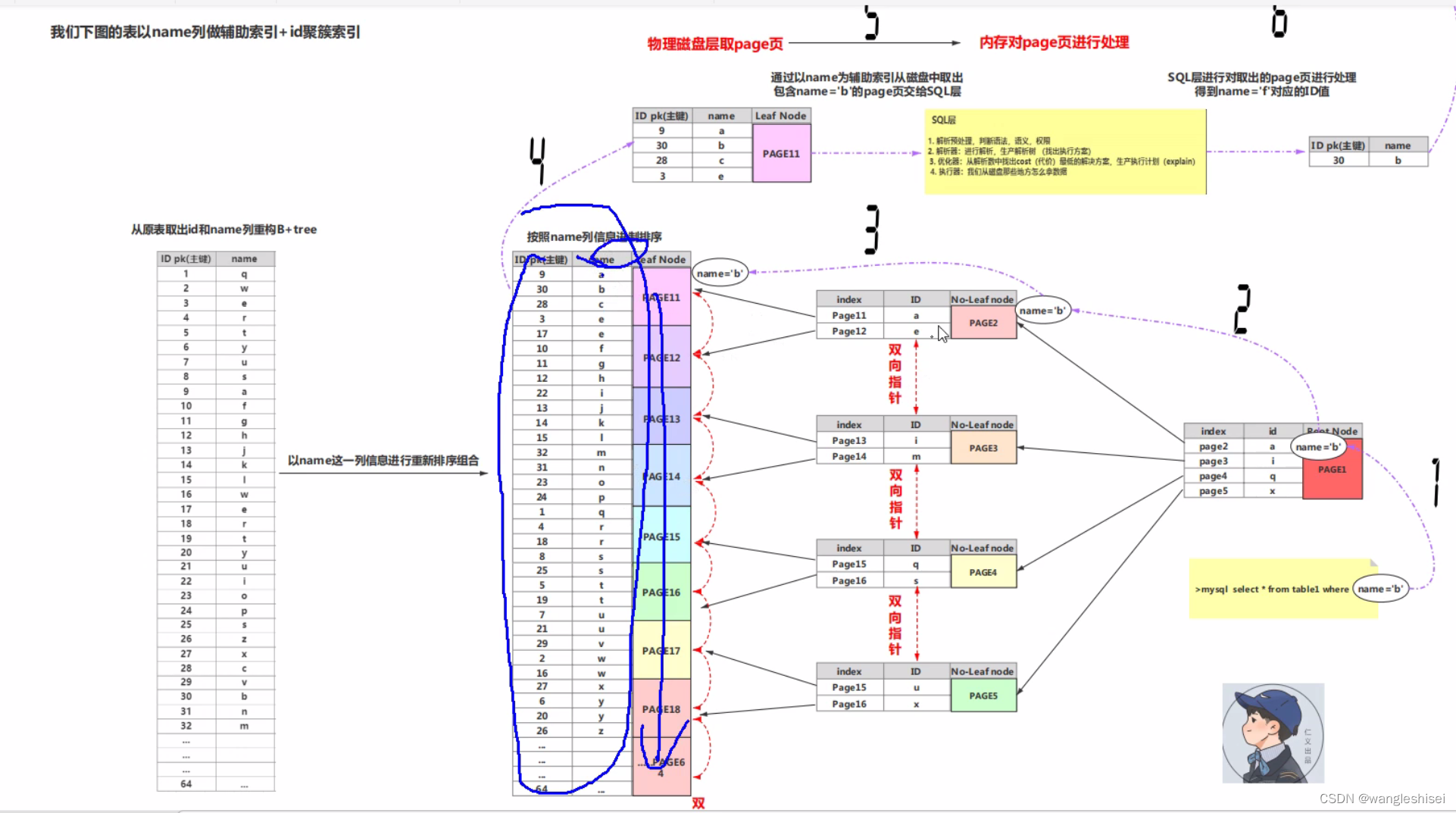
回表到主键索引继续查找。
联合索引
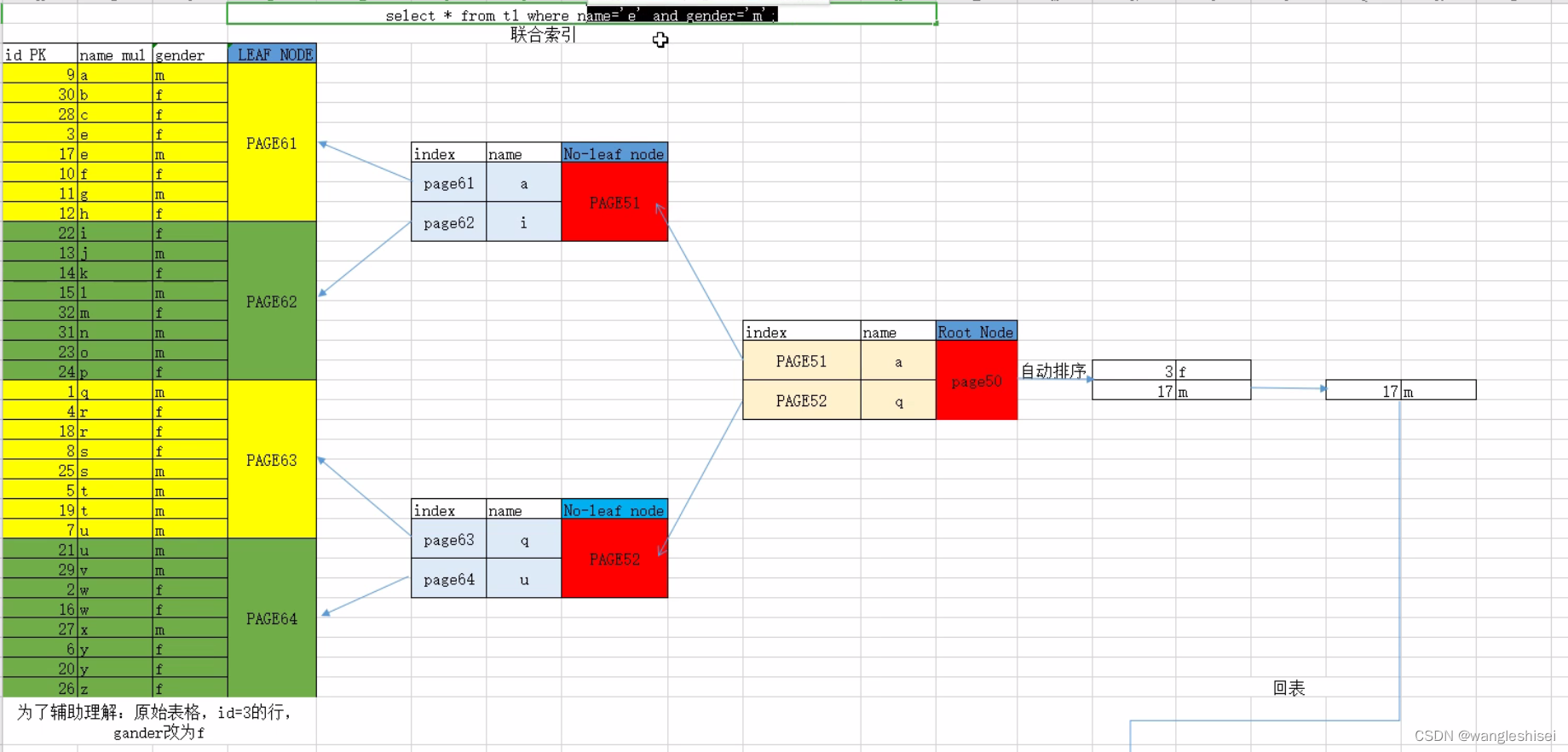
基于两列(或多列)生产的联合索引+上主键索引列
回表查询
a、按照辅助索引列,作为查询条件时。先查找辅助索引树得到ID。在到聚簇索引查找数据行的过程。
b、IO量多。IO次数多。随机io增多。sql层和engine交互多次。io偏高,cpu偏高。
c、减少回表建议。
1.辅助索引能够完全覆盖查询结果。可以使用联合索引。
2.尽量让查询条件精细化,尽量使用唯一值多的列作为查询条件。(id 列更好。先查id 在基于聚簇索引查询)
3.优化器,mrr()ICP(默认开启),锦上添花。
索引树高度影响因素?如何解决。
a 越低越好。(2层左右)。3层理论存储2千万数据。列越多。考虑减少。
b.数据行越多,高度越高。
1.高度太高的建议用分区表,一个实例里管理。
2.按照数据特点,进行归档表。pt-archiver.
3.分布式架构。针对海量数据高并发业务主流方案。
4.在设计方面,满足三大范式。 (减少数据冗余。)
c.主键规划,长度过长()辅助索引会用到主键索引的东西。 超级特殊(联合索引)
1.主键,尽量使用数字自增列。
d.列值长度越长,数据量大的话。会影响到高度。
特别长用前缀索引构建数据列。
e.数据类型的选择
选择合适的简短的。
例如:
1.存储人的年龄,使用 tinyint 更好。只占用一个字节。
2.存储名字char(20)和 varchar(20) 的选哪一个。
a.站在数据插入性能角度思考,应该选择char
b.从节省空间的角度选varchar
c.从索引高度选择varchar
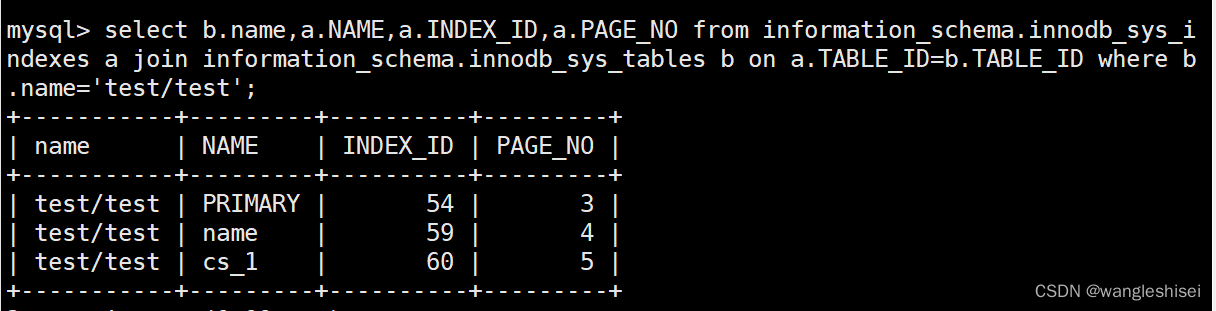
查看索引相关信息。
查看(表名库名。索引名。索引id。索引起始位置页点)
select b.name,a.NAME,a.INDEX_ID,a.PAGE_NO from information_schema.innodb_sys_indexes a join information_schema.innodb_sys_tables b on a.TABLE_ID=b.TABLE_ID where b.name=‘test/test’;
分析数据文件 ibd文件。
hexdump -s offset -n 10 XXX.ibd
** -s 是从哪里开始,单位是字节。 -n查看后多少
offset = page_no161024+64 #page_no 是上面查找到。
查询索引
desc test;
key
PK -->主键索引
MUL -->辅助索引
UK -->唯一索引
show index from test;
创建索引。
统计信息表
查看统计信息大小。
select * from mysql.innodb_table_stats;
查看已经创建的索引的基数
show index from 表名。
cardinality列表示基数。
查看实时更新统计信息。
analyze table world.city;
查看语句执行计划。desc==explain
desc format=tree 跟语句 树形结构显示。
explain
table :此次查询访问的表
type :索引查询的类型 :索引查询的类型
possible_keys: 可能会应用的索引
key :最终会选择的索引。
key_len: 索引覆盖长度。主要判断联合索引长度。
rows : 需要扫描的行数
extra :额外信息。
其中索引类型优化type值
1、(all.index 这俩优化)(all 是全表扫描。index 全索引扫描)。
2、range 索引范围扫描。(叶子中有双向指针。< > <= >=)在delete 和update 的时候。在索引设计不合理的时候。使用limit 有可能出现主从数据不一致的情况。(尽量做限制条件查询。)
3、如果有 or 或者 id(‘xx’,‘bb’);查询可以优化
如果查询列重复值少的话,建议改写为union all。
如。select * from city where cs=‘chn’ or cs=‘usa’;
改写成
select * from city where cs=‘chn’
union all
select * from city where cs=‘usa’;
4、ref 辅助索引的等值查询。
5、eq_ref 多表连接查询,非驱动表的连接条件为主键或者唯一键时。
6、联合索引查看是否使用了联合索引。或者使用了长索引。
desc format=json select id from c1;
desc format=json select * from t100w where num=‘11’ and k1=‘222’ and k2=‘ccc’ used_key_parts 列判定。
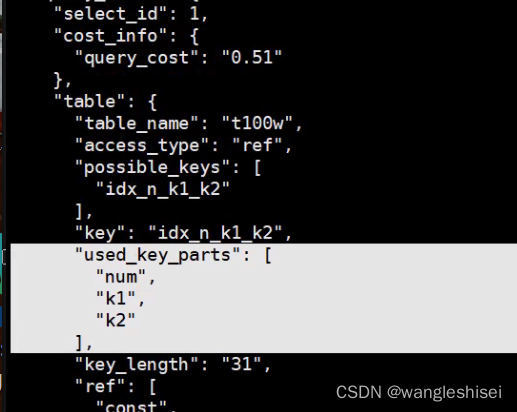
联合索引使用条件。
联合索引应用要满足最左原则。
使用联合索引时,选择重复值最少的列做最左列。
如果使用 order by 或者使用 group by
备注里面写。using filesort 。则要where条件跟 order by group by建立联合索引。
数据库语句慢
a.应急性的慢。
show processlist; ---->慢sql ------> explain sql ----->优化索引改写语句。
b. 间歇性慢。
slowlog ---->慢语句 ----> explain sql ----->索引优化、改写语句
数据库查询执行计划。
explain analyze select * from test where id=3; #尽量少用修改操作可能执行。
数据库建立索引原则

AHI 自适应的哈希索引。内存中的热点缓存页建立索引。
强制走索引
force index(索引名)
change buffer 没有在内存中的辅助索引,先存到这里,然后找时间在加载到内存中。占整个buffer pool 的20%。


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









