




示例
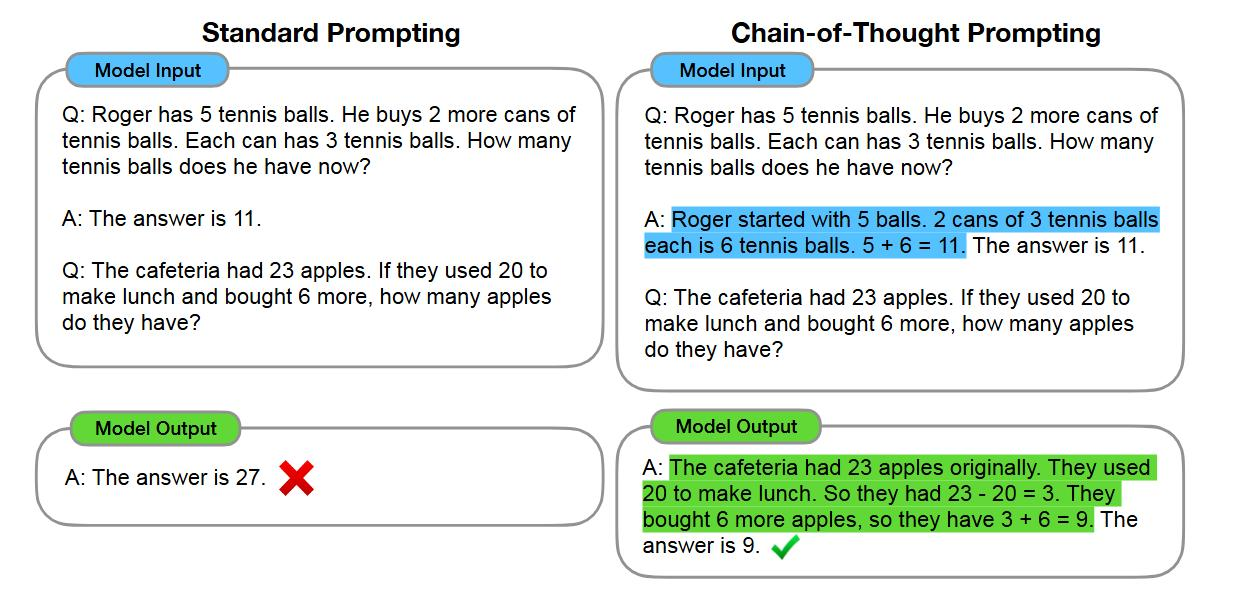
标准提示法
模型输入
问:罗杰有 5 个网球,又买了 2 罐网球,每罐有 3 个网球,他现在有多少个网球
答:答案是 11
问:自助餐厅有 23 个苹果,如果他们用了 20 个来做午餐,又买了 6 个,那他们现在有多少个苹果?
答:答案是 27
思维链提示法
模型输入
问:罗杰有 5 个网球,他又买了 2 罐网球,每罐有 3 个网球,他现在有多少个网球
答:罗杰一开始有 5 个球,2 罐、每罐 3 个网球,一共是 6 个网球,5 + 6 = 11,答案是 11
问:自助餐厅有 23 个苹果,如果他们用了 20 个来做午餐,又买了 6 个,那他们现在有多少个苹果
答:自助餐厅原本有 23 个苹果,他们用了 20 个做午餐,所以还剩 23 - 20 = 3 个;他们又买了 6 个苹果,所以现在 3 + 6 = 9 个;答案9
解释
LLM 大多数都是生成式模型(Genertive Models),比如GPT系列
本质:学习数据分布,创建新数据 ,一个随机数据生成器,里面遵循数学表达式,在足够大且准确的的参数支持下,能够对给定的输入,续写出大概率准确的答案,底层的依赖逻辑靠概率
LLM并不一定理解问的问题,也不一定清楚它回答的内容是什么,它只是输出一个比较有可能出现在问题之后的内容。所以模型回答存在幻觉(答非所问 / 胡编乱造),尤其是在一些复杂推理问题上,比如数学问题。
什么是CoT
CoT思维链是一种引导AI模型解决复杂问题的推理方法,核心是让模型像人类一样分步骤思考,而非直接输出结果,减少跳跃性错误
通过将问题拆解为多个中间推理步骤(例如“先计算A,再分析B,最后得出C”),模型能清晰地处理数学题、逻辑推理等需要多步分析的任务
问题:3人3天喝3桶水,9人9天喝几桶?
回答:3人1天喝1桶 → 1人1天喝1/3桶水->1人9天喝3桶 → 9人9天喝27桶
通过在输入文本中引入一系列中间推理步骤,引导语言模型逐步进行思考和推理,从而得出最终答案
模拟了人类解决问题时的逐步推理过程,让模型能够展示出更具逻辑性和连贯性的思维路径,结果更易验证,增强AI的透明度和可信度
对于一些需要多步推理的复杂问题,传统语言模型可能直接给出答案,缺乏中间推理过程,导致结果不准确或难以理解
CoT 能让模型按步骤分析问题,显著提高解决复杂问题的准确性。例如在数学应用题、逻辑推理题等方面表现更为出色
传统模型输出像黑箱,难以知晓其决策依据,CoT 通过展示中间推理步骤,使人理解模型为何得出特定结论,增加模型透明度和可解释性
引导模型生成更合理回复:在对话系统等应用中,能引导模型生成更符合逻辑和上下文的回复,提升对话的流畅性和质量
定义
a series of intermediate reasoning steps
一系列中间推理步骤,促进语言模型推理
什么是 short-CoT和long-CoT
short - CoT(Short Chain - of - Thought,短思维链)和 long - CoT(Long Chain - of - Thought,长思维链)
是在思维链提示(Chain - of - Thought Prompting)基础上发展出的概念,主要用于提升大语言模型在复杂任务中的推理能力
推理步骤长度
short - CoT:强调简洁精炼,推理过程相对简短 ,一般包含少量的中间推理步骤或关键推理节点。例如在解决数学应用题时,可能只通过一两个关键的逻辑转换就得出结论,旨在快速抓住问题核心要点,用较少的步骤完成推理
long - CoT:推理过程更为详细和冗长,涵盖了更多的中间推理步骤和细节。在处理复杂问题时,会逐步展开推理,将大问题拆解为多个子问题,每个子问题都有相应的推理分析,通过一系列连贯且细致的步骤最终得出答案 。比如解决一个涉及多条件、多约束的逻辑推理问题,long - CoT 可能会将每个条件的分析、条件之间的关联推导等都详细呈现出来
适用场景
short - CoT:适用于问题相对简单、答案明确,或者模型本身已经具备一定相关知识和推理能力的场景
比如简单的算术计算、常识性问题的推理,像 “2 + 3 = ?”,通过 short - CoT,模型可能直接基于已有的运算知识得出答案
在实际应用中,对于一些对响应速度要求较高,且问题难度不大的场景,short - CoT 既能保证一定的推理质量,又能快速给出结果
long - CoT:更适合处理复杂、需要深度推理和多步分析的任务,如复杂的数学证明题、多领域知识融合的问题、复杂的逻辑谜题等
例如,在解决一个涉及历史、地理、经济等多学科知识的综合问题时,long - CoT 可以逐步分析每个学科角度对问题的影响,整合多方面信息来得出准确结论
生成难度与效率
short - CoT:
生成相对容易,因为其推理步骤少,对模型的计算资源和推理复杂度要求较低,所以生成速度较快
同由于步骤简洁,在一些简单任务上,能减少模型出错的概率,提高推理的稳定性
但在复杂问题上,可能因为推理步骤过于简略而无法全面考虑问题,导致结果不准确
long - CoT:
生成难度较大,需要模型具备更强的推理能力、知识储备和逻辑组织能力
由于推理过程长,涉及更多的中间步骤和信息处理,会消耗更多的计算资源和时间
随着推理步骤的增加,模型在某一步骤出现推理错误的可能性也会增加,可能导致最终结果出错,但一旦正确生成,往往能在复杂任务上展现出更好的推理效果
对模型性能的影响
short - CoT:可以在一定程度上提升模型在简单任务或熟悉领域任务上的推理表现,帮助模型更准确地捕捉问题关键并给出答案,同时不会显著增加模型的运算负担 。但对于复杂任务的解决能力提升有限
long - CoT:能够显著增强模型在复杂任务中的推理能力,使模型能够处理那些需要多步深度思考和综合分析的问题 。通过详细的推理步骤展示,有助于更好地理解模型的决策过程,发现模型推理中的潜在问题,进而优化模型,但在一些简单任务上可能会显得过于繁琐,且增加不必要的计算开销
示例
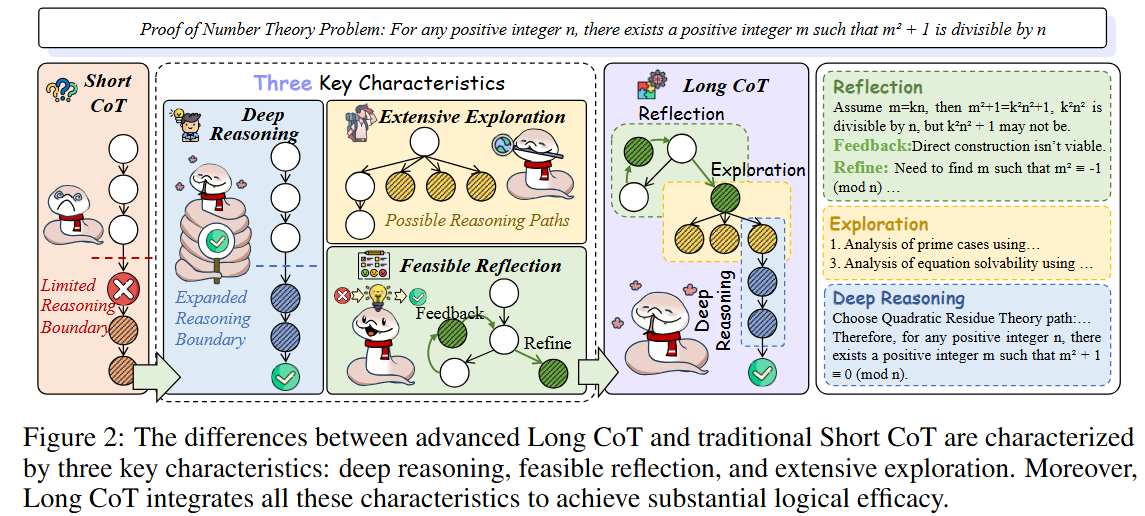


深度推理
深度推理是指跨多个互连的逻辑节点执行深入而彻底的逻辑分析的能力
广度探索
鼓励分支广泛探索不确定或未知的逻辑节点,从而扩展潜在的推理路径集
(生成并行的不确定节点和从已知逻辑过渡到未知逻辑)
可行反射(feasible reflection)
涉及重新访问以前的逻辑节点以验证其连接是否有效和准确,然后更正它们或选择替代逻辑路径
(涉及逻辑连接的反馈和完善)
附录
cafeteria ˌkæfəˈtɪəriə ˌkæfəˈtɪriə 自助食堂,自助餐馆
can 罐,听
intermediate ˌɪntəˈmiːdiət ˌɪntərˈmiːdiət
居中的,中间的;中等程度的,中级的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









