




 本文深入分析了MyBatis的执行流程,包括SqlSessionFactory的创建、SqlSession的生成、查询执行过程及一级缓存机制。详细解释了缓存键的生成、缓存的使用和刷新,以及通过源码解读MyBatis如何处理存储过程的参数缓存。
本文深入分析了MyBatis的执行流程,包括SqlSessionFactory的创建、SqlSession的生成、查询执行过程及一级缓存机制。详细解释了缓存键的生成、缓存的使用和刷新,以及通过源码解读MyBatis如何处理存储过程的参数缓存。
前言
上一讲我们分析到了sqlSessionFactory的执行流程,这一次我们来分析sqlsession的创建和执行流程还有查询的执行过程
开始
我们看这句代码
SqlSession sqlSession = sqlSessionFactory.openSession();
//这是个接口,就是sqlSession的工厂
public interface SqlSessionFactory {
SqlSession openSession();我们点击接口中的向下箭头,看到有两个实现类,而mybatis默认的实现类是这个

点进去看看
@Override
public SqlSession openSession() {
//从dataSource打开session会话
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//mybatis运行环境
final Environment environment = configuration.getEnvironment();
//事务工厂类
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
//新建一个事务
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//重点,执行器
final Executor executor = configuration.newExecutor(tx, execType);
//返回默认的sqlSession
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}protected boolean cacheEnabled = true;
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);//我们使用的是默认执行器
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);//一级缓存,这里引出一个mybatis的概念,就是mybatis的一级缓存是默认开启的,面试官问mybatis的一级缓存是不是默认开启的,就是这里得出的
}
executor = (Executor) interceptorChain.pluginAll(executor);//这句代码应该怎么去理解呢,这其实是一个责任链模式,这句代码用来拦截所有的插件,通过这些拦截器可以改变Mybatis的默认行为
return executor;
}
public class InterceptorChain {
private final List<Interceptor> interceptors = new ArrayList<Interceptor>();
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
Object plugin(Object target);
void setProperties(Properties properties);
}
这里稍微解释一下责任链模式,责任链模式是23种设计模式中的一种模式,责任链模式(Chain Of Responsibility Pattern )在 Wiki 上定义如下:
责任链模式在面向对象程式设计里是一种软件设计模式,它包含了一些命令对象和一系列的处理对象。每一个处理对象决定它能处理哪些命令对象,它也知道如何将它不能处理的命令对象传递给该链中的下一个处理对象。该模式还描述了往该处理链的末尾添加新的处理对象的方法。
到这里,sqlsession就创建完成了
接下来,我们开始分析User user = sqlSession.selectOne("com.ww.mybatis.mapper.UserMapper.selectUser", 1);这句代码
这句代码的第一个参数传入的是mapper的全类名加上方法名,后面的参数是参数值,我们断点进入发现这也是一个接口,也有两个实现类,默认的实现类是
<T> T selectOne(String statement, Object parameter);
点进去看一下
@Override
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.<T>selectList(statement, parameter);//执行selectList方法
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
@Override
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);//看到了吗,之前创建的MappedStatement,在这里被取出来了
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);//返回执行器的query方法,这里是重点
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}Executor接口中的query方法,两个实现类,默认实现是BasicExecutor抽象类
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
点进去看看
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);//Boundsql是保存sql的对象
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);//创建一级缓存的缓存键,等下主要看这个方法
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
//我们看一下BoundSql对象里有些什么
public class BoundSql {
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Object parameterObject;
private final Map<String, Object> additionalParameters;
private final MetaObject metaParameters;
public BoundSql getBoundSql(Object parameterObject) {
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);//之前我们讲过sql语句应该通过注解拿到放到了sqlSource中,现在在这里封装成了boundSql对象
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();//参数列表
if (parameterMappings == null || parameterMappings.isEmpty()) {
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
// check for nested result maps in parameter mappings (issue #30)
for (ParameterMapping pm : boundSql.getParameterMappings()) {
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);//resultMap
if (rm != null) {
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
return boundSql;
}好了重点来了,我们开始分析cacheKey的生成方法
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());//这个是MappedStatement的id
cacheKey.update(rowBounds.getOffset());//偏移量
cacheKey.update(rowBounds.getLimit());//limit
cacheKey.update(boundSql.getSql());//sql语句
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}cacheKey由MappedStatement的id+偏移量+limit+sql语句组成,我把生成出来的CacheKey对象放出来看看,大家一目了然
![]()
接下来我们来到CacheExecutor执行器的这个query方法,参数是(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();//先检查mappedStatement里有没有缓存
if (cache != null) {
flushCacheIfRequired(ms);//如果缓存不为空就看看要不要刷新缓存
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);//从事务缓存管理器中检查能不能取得缓存
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);//如果没有缓存,就调用普通执行器的查询方法
//把查询出的结果放到事务缓存管理器里
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}由于是第一次查询肯定不会有缓存的,于是我们就跳到BaseExecutor的query方法中来查看
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();//如果查询栈的大小为0,就清除缓存
}
List<E> list;
try {
queryStack++;//查询栈大小+1
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;//如果缓存中有值,则list等于缓存中的值
if (list != null) {
// 处理本地缓存的输出参数
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
// MappedStatement级别的缓存,则清空本地缓存
clearLocalCache();
}
}
return list;
}同样的,因为第一次查询肯定没有缓存,一定会查询数据库,那么我们来看看queryFromDatabase方法
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//先给本地缓存加一个placeholder值
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//执行真正的数据库查询,等会我们可以看到,最终还是用的jdbc的方式执行的数据库查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//把查询出的结果放到本地缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//看到了吗,prepareStatement,我这里不细展开了,我给大家解释下最终是不是调用的jdbc
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
//org.apache.ibatis.executor.statement.BaseStatementHandler#prepare在这个方法中,会去到org.apache.ibatis.executor.statement.PreparedStatementHandler#instantiateStatement方法
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
statement = instantiateStatement(connection);//这个方法
setStatementTimeout(statement, transactionTimeout);
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
//
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
java.sql.Connection#prepareStatement(java.lang.String, int)
//看到了吗,最终就是调用这里的prepareStatement我们看到,执行完query方法,数据已经被查出来了,同时放到了本地缓存中
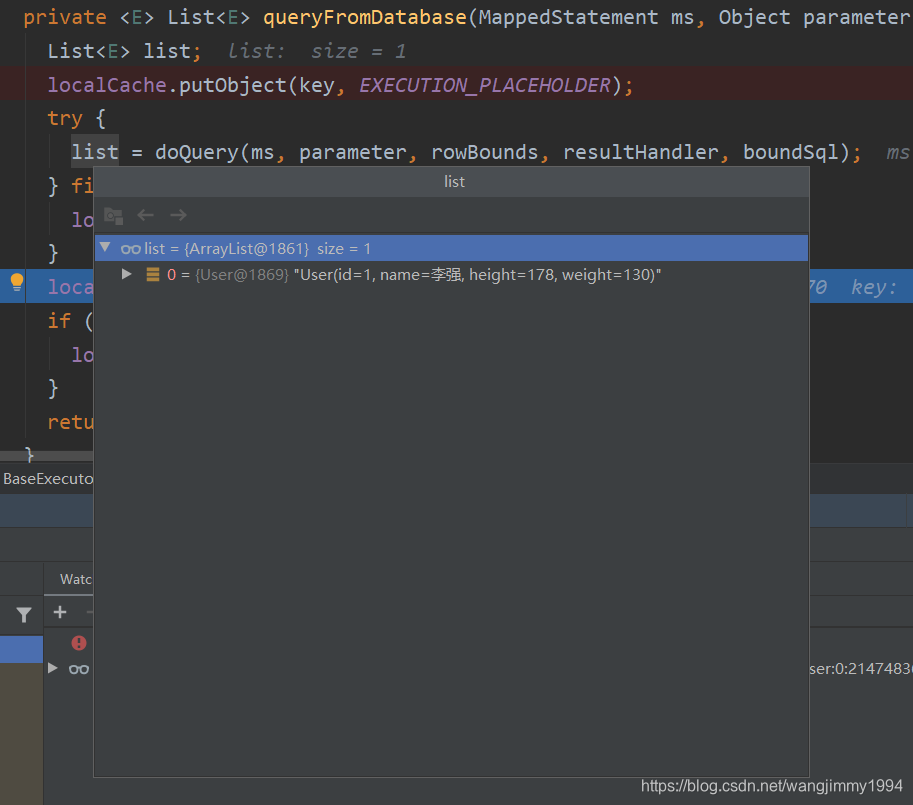
那么到这里我产生了一个疑问,本地缓存里已经有值了,那么我断开数据库会话,再启动一次,再执行查询,会从缓存中查出数据来吗,可以告诉大家,结果是否定的,经过我的实验证明了mybatis一级缓存只在一次会话中有效。这可能也是面试的时候会被问到的,大家要记住。
现在采用另一种方式来查询,也就是使用session的getMapper方法,直接得到mapper对象,执行mapper对象的查询方法,我们来看看getMapper方法是怎么执行的
首先我们来到org.apache.ibatis.session.defaults.DefaultSqlSession#getMapper这个方法
@Override
public <T> T getMapper(Class<T> type) {
return configuration.<T>getMapper(type, this);
}可以看到这里调用了configuration的getMapper方法,我们再进一步看看
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);//这里调用了mapper注册里的获取mapper的方法
}
//org.apache.ibatis.binding.MapperRegistry#getMapper
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);//返回一个mapperProxyFactory代理工厂
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);//代理工厂的新增实例方法
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
//org.apache.ibatis.binding.MapperProxyFactory#newInstance(org.apache.ibatis.session.SqlSession)
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);//这里调用了java反射包中的生成代理对象的方法
}
//java.lang.reflect.Proxy#newProxyInstance
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
throws IllegalArgumentException
{
Objects.requireNonNull(h);
final Class<?>[] intfs = interfaces.clone();
final SecurityManager sm = System.getSecurityManager();
if (sm != null) {
checkProxyAccess(Reflection.getCallerClass(), loader, intfs);
}
/*
* Look up or generate the designated proxy class.
*/
Class<?> cl = getProxyClass0(loader, intfs);
/*
* Invoke its constructor with the designated invocation handler.
*/
try {
if (sm != null) {
checkNewProxyPermission(Reflection.getCallerClass(), cl);
}
final Constructor<?> cons = cl.getConstructor(constructorParams);
final InvocationHandler ih = h;
if (!Modifier.isPublic(cl.getModifiers())) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
cons.setAccessible(true);
return null;
}
});
}
return cons.newInstance(new Object[]{h});
} catch (IllegalAccessException|InstantiationException e) {
throw new InternalError(e.toString(), e);
} catch (InvocationTargetException e) {
Throwable t = e.getCause();
if (t instanceof RuntimeException) {
throw (RuntimeException) t;
} else {
throw new InternalError(t.toString(), t);
}
} catch (NoSuchMethodException e) {
throw new InternalError(e.toString(), e);
}
}通过这个代理类的方法,我们最终得到了UserMapper这个对象,可以直接执行mapper对象的方法进行查询,通过断点debug我们发现通过一次代理后最终还是到了org.apache.ibatis.session.defaults.DefaultSqlSession#selectList这个方法来执行查询
好了,接下来开始测试mybatis的一级缓存到底是不是能像我们在源码中看到的那样起作用,我调用了三次查询方法
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.selectUser(1);
User user2 = userMapper.selectUser(1);
User user3 = userMapper.selectUser(1);
System.out.println(user);我们来看第一次执行查询时的情况,第一次查询完本地缓存中只有一个值为placeholder的缓存
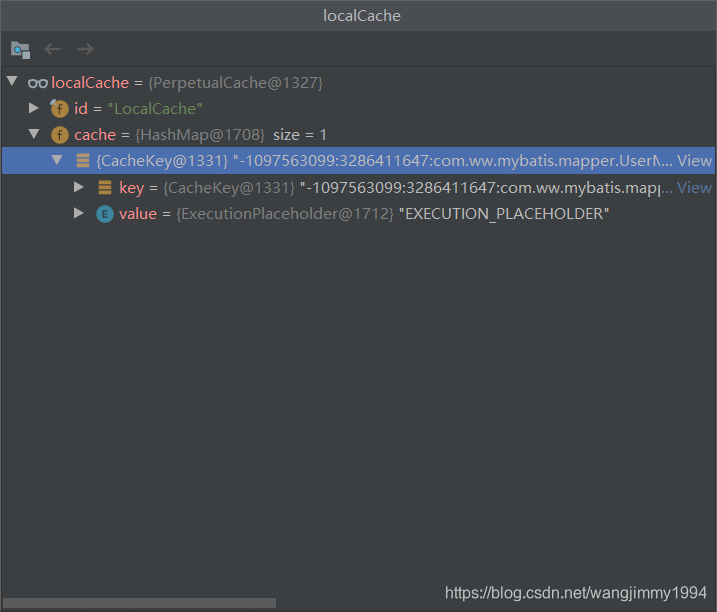
接着查询出的list放入本地缓存中,我们来看第二次的执行情况,此时本地缓存中已经有了查询出的记录的缓存
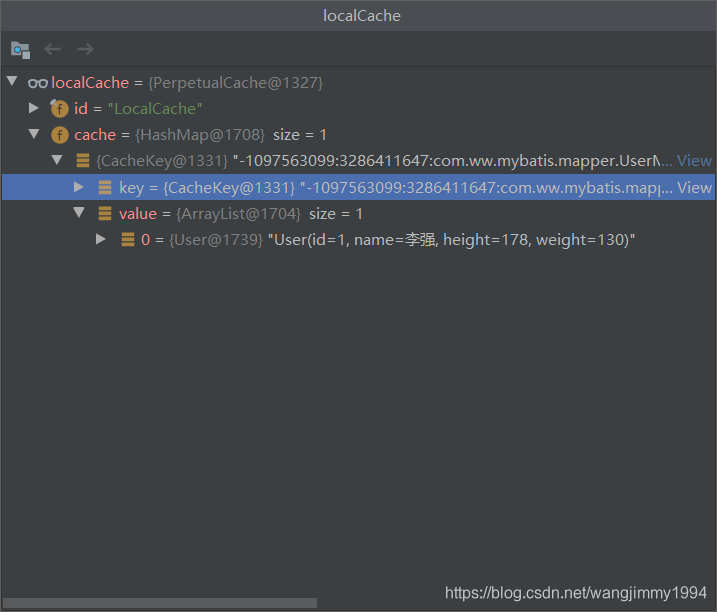
//执行到这语句,因为localCache本地缓存中已经有了值,直接取出
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;我们看到,接下来就到了这么一个方法handleLocallyCachedOutputParameters,这个方法我前面的代码分析中有注释过,看名字好像是控制本地缓存的输出参数,那么这个方法究竟是干什么的呢,我先进去看看
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
private void handleLocallyCachedOutputParameters(MappedStatement ms, CacheKey key, Object parameter, BoundSql boundSql) {
if (ms.getStatementType() == StatementType.CALLABLE) {
final Object cachedParameter = localOutputParameterCache.getObject(key);
if (cachedParameter != null && parameter != null) {
final MetaObject metaCachedParameter = configuration.newMetaObject(cachedParameter);
final MetaObject metaParameter = configuration.newMetaObject(parameter);
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
if (parameterMapping.getMode() != ParameterMode.IN) {
final String parameterName = parameterMapping.getProperty();
final Object cachedValue = metaCachedParameter.getValue(parameterName);
metaParameter.setValue(parameterName, cachedValue);
}
}
}
}
}这个方法有点不太好理解,我找到了一篇网上的博文,是这么解释的
localOutputParameterCache也是一级缓存,只不过它作用的不是我们理论上的返回结果,而是我们请求的参数(可以是DO),更进一步说他是对存储过程的一种缓存
具体的说明请前去https://www.jianshu.com/p/b1e8b1458afb查看
对了还有一点也是我在阅读源码的时候发现的,那就是为什么mapper文件里配置的映射语句是在那里起的作用,答案在org.apache.ibatis.binding.MapperMethod#execute这个方法中
//看到了吗,这里判断了命令的类型,会执行各自对应的方法
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}总结
接下来我来总结一下,首先我总结mybatis中的核心模块和核心类,不分先后分别有
-
SqlSessionFactoryBuilder,它的作用是通过XML配置文件创建Configuration对象,然后通过build方法创建SqlSessionFactory对象。
-
SqlSessionFactory,SqlSessionFactory的主要功能是创建SqlSession对象,和SqlSessionFactoryBuilder对象一样,没有必要每次访问Mybatis就创建一次SqlSessionFactory,通常的做法是创建一个全局的对象就可以了。
-
SqlSession,顾名思义,Sql会话,主要功能是完成一次数据库的访问和结果的映射
-
Executor,Executor是一个执行器,Executor对象在创建Configuration对象的时候创建,并且缓存在Configuration对象里。Executor对象的主要功能是调用StatementHandler访问数据库,并将查询结果存入缓存中
-
StatementHandler,StatementHandler是真正访问数据库的地方,并调用ResultSetHandler处理查询结果。
-
ResultSetHandler,处理查询结果
画个简单版的核心类工作流程
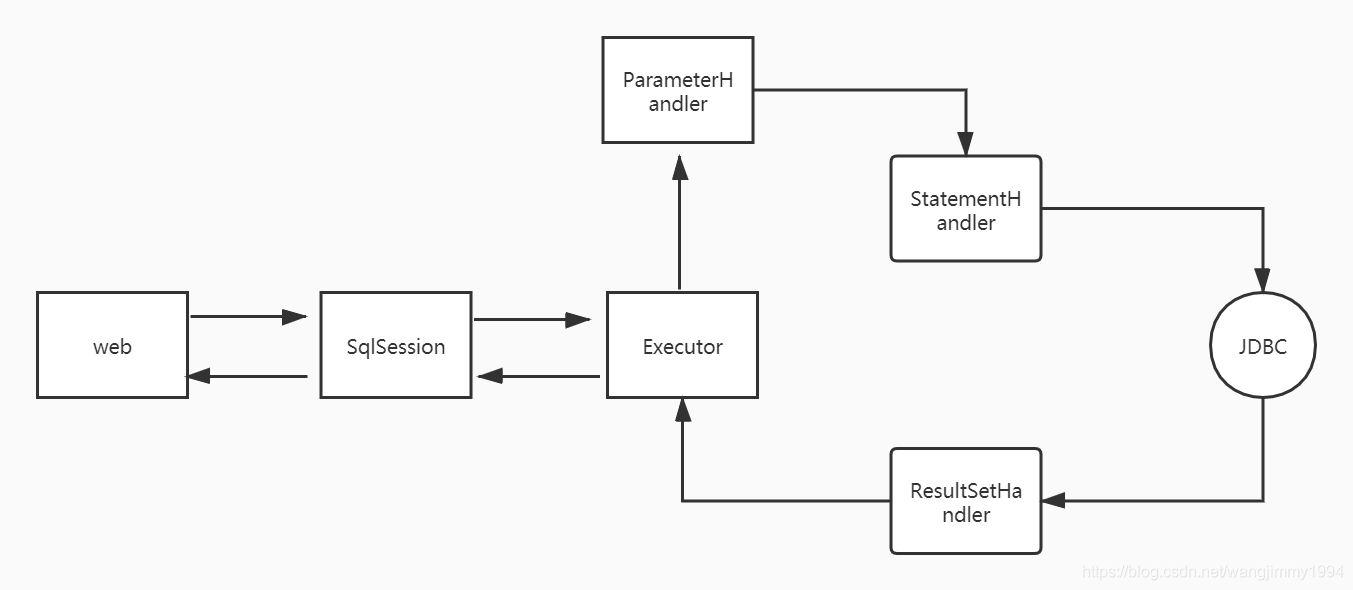
再介绍几个次核心类吧
- Configuration,Configuration就像是Mybatis的总管,Mybatis的所有配置信息都存放在这里,此外,它还提供了设置这些配置信息的方法
- Enviroment,环境配置类,MyBatis 可以配置多种环境。
以Executor为分界线,Mybatis的工作流程还可以分成这样两部分
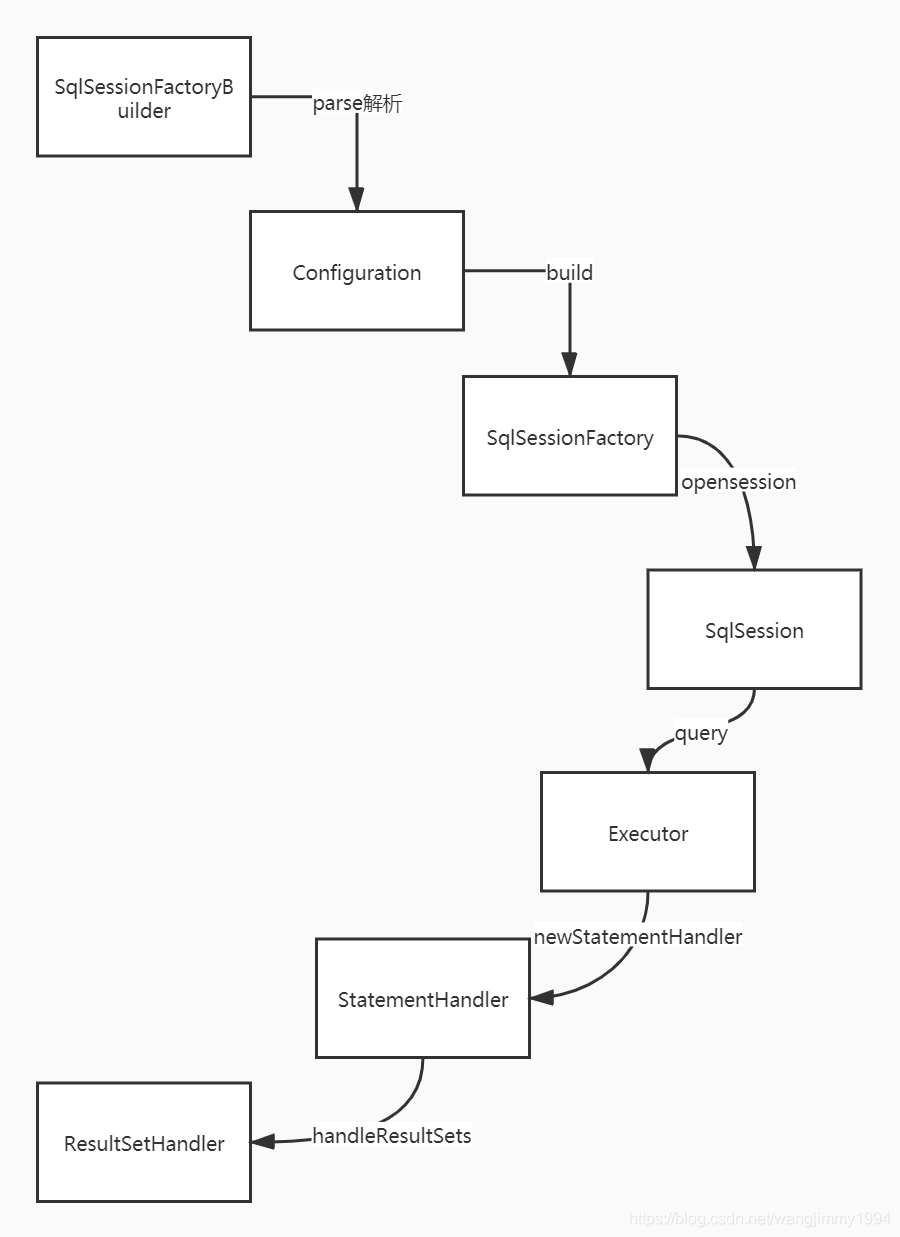
好了,我的总结就到这里,谢谢大家的观看。

















 6831
6831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









