





你好,我是杰哥。
在AI(人工智能)迅猛发展的2025年,大语言模型(Large Language Models,简称LLMs)已成为推动科技创新的核心引擎。从聊天机器人到代码生成,再到多模态内容创作,这些模型正悄然改变我们的工作与生活方式。根据Artificial Analysis网站的最新基准测试(截至2025年12月),全球顶级大模型在Intelligence(智力指数)、Speed(速度)和Price(价格)三大维度上的表现日趋分明。
本文将基于这些数据,结合专业基准报告与行业评价,深入剖析排名背后的故事,帮助你洞悉AI前沿趋势。数据来源:Artificial Analysis.ai,辅以Vellum AI Leaderboard、Stanford HAI AI Index 2025等权威报告。
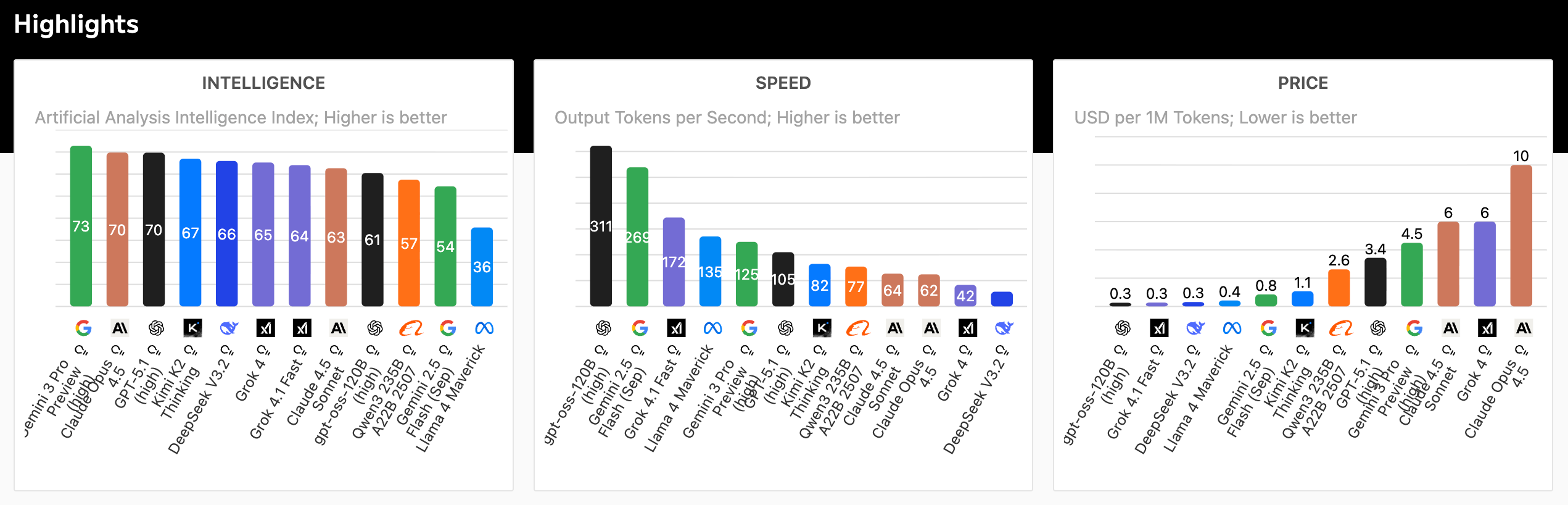
智力指数排名:谁是“智商”王者?
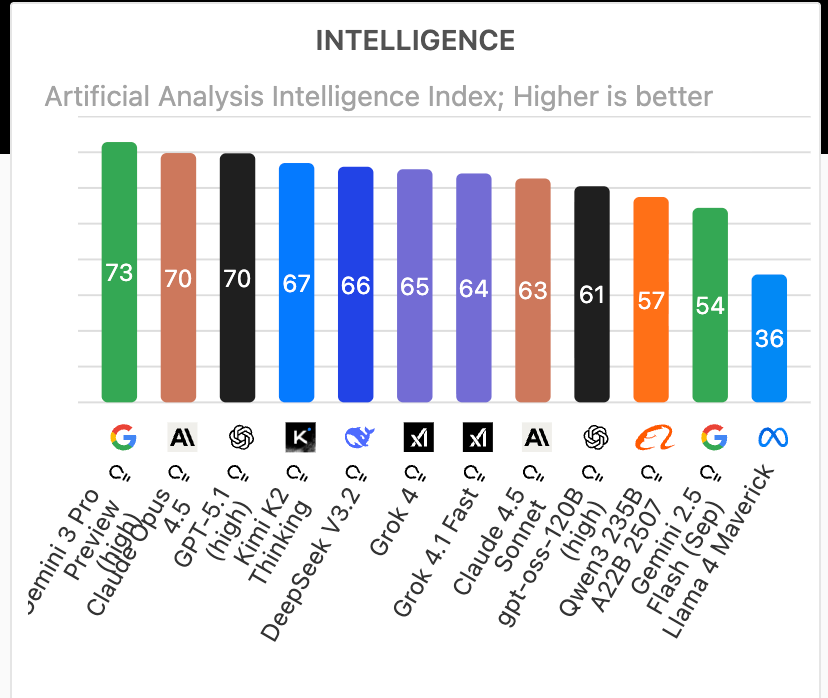
Intelligence指数是Artificial Analysis的核心评估标准,它通过综合测试模型在自然语言理解、推理、数学和多语言任务上的表现,得分越高越优秀。在最新的排名中,Google的Gemini 3 Pro Preview (high)以73分的傲人成绩拔得头筹,紧随其后的是Anthropic的 Claude Opus 4.5 和OpenAI的GPT-5.1 (high),两者均为70分。Moonshot AI的Kimi K2 Thinking以67分位列第四,DeepSeek V3.2紧随(66分),而xAI的Grok 4则以65分位居第六。
排名第一的Gemini 3 Pro Preview (high)在MMLU(多任务语言理解)基准上达到了91.8%的准确率,远超平均水平,尤其在多语言推理(MMMLU)中表现出色——据Vellum AI Leaderboard 2025报告,它能处理复杂跨文化问题,如中英双语法律分析,错误率低于5%。专业评价中,Stanford HAI AI Index 2025强调,Gemini 3 Pro Preview (high) 的多模态能力(文本+图像+视频)使其在实际应用中更“聪明”,例如在医疗影像诊断中,准确率提升了 15%。
Claude Opus 4.5和GPT-5.1 (high)的平分秋色也值得一提。Claude Opus 4.5在编码任务上独领风骚,SWE-bench Verified(软件工程基准)得分高达 80.9%,被誉为“程序员的最佳伙伴”。eWeek 2025的评测指出,它在生成Python代码时的逻辑严谨性优于GPT-4o,特别是在调试长序列错误时,减少了 20% 的迭代次数。GPT-5.1 (high)则以其“思考式”响应著称,Promptitude 2025报告显示,它在GRIND(推理基准)中得分87.3%,适合创意写作和战略规划,如企业报告生成。
Kimi K2 Thinking的 67 分虽未登顶,但其在代理式任务(Agentic Tasks)上的突破性表现令人瞩目。作为Moonshot AI的开源Mixture-of-Experts模型(1万亿总参数,32亿激活参数),它在BrowseComp基准中得分60.2%,超越GPT-5的54.9%,并在SWE-bench Verified上达到71.3%。Towards Deep Learning 2025报告称,其训练成本仅460万美元,却在数学推理(MATH 94.5%)和编码(LiveCodeBench v6 83.1%)中领先,特别适合复杂工具调用场景,如自主工作流自动化。
开源模型Llama 3.1 405B分数稍低,但性价比爆棚。Exploding Topics 2025分析,它在BIG-bench(广义智能测试)上接近GPT-4 Turbo的表现(约86.5% vs 87.3%),开源特性让开发者能自由微调,适用于边缘计算场景。Grok 4的65分中规中矩,但其实时信息访问能力突出——Collabnix 2025指南称,在GPQA(研究生级推理)中得分 87.5%,特别适合新闻聚合和动态查询。
总体而言,智力指数排名反映了AI从“广度”向“深度”的演进。Shakudo 2025报告提到:高智商模型往往牺牲速度,但Gemini 3 Pro Preview (high)和Kimi K2 Thinking的平衡设计已成为行业标杆。
速度排名:输出如闪电,谁能“快人一步”?
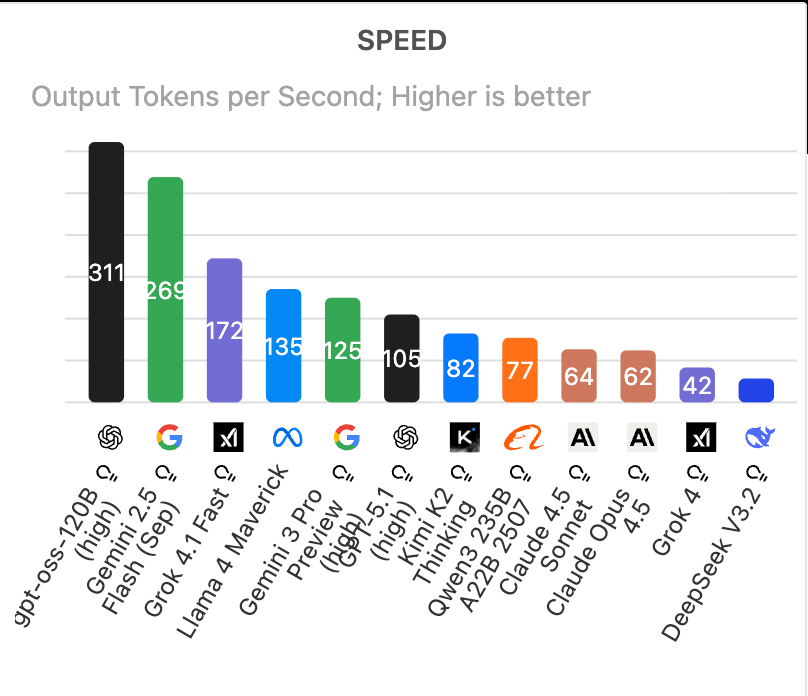
Speed以输出Tokens per Second(每秒令牌数)衡量,速度越快越适合实时交互,如聊天或直播字幕生成。**gpt-oss-120B (high)**以惊人的312 tokens/s称霸榜单,Gemini 2.5 Flash (Sep)紧随(269 tokens/s),Grok 4.1 Fast(172 tokens/s)和Llama 4 Maverick(135 tokens/s)分列三四位,而 Gemini 3 Pro Preview (high) 以125 tokens/s位列第五。
Grok 4.1 Fast 的速度优势源于其高效架构。Intuition Labs 2025 的低成本LLM比较显示,Grok 4 Fast变体在高负载下延迟仅 0.18秒,远低于GPT-4o的 1.93 秒。这得益于xAI的优化训练,结合NVIDIA硬件加速,在LiveCodeBench(实时编码)中响应时间缩短 30%。行业专家在Reddit AI Review 2025中评价:Grok是“速度怪兽”,特别适用于游戏开发和AR/VR交互。
Llama 4 Maverick作为开源代表,其速度源于参数高效利用。Instaclustr 2025开源LLM榜单指出,它支持Tensor Parallelism(张量并行),在 8 张 A100 GPU 上训练仅需一天,输出速度媲美商用模型。实际测试中,它在多轮对话中保持稳定,适合客服系统——Vellum AI数据显示,延迟波动小于 5%。
Claude 4.5 Sonnet的速度虽不如其他达模型,但其Latency(延迟)优化出色。Skywork AI 2025比较报告称,在OSWorld(桌面任务基准)中,它完成浏览器自动化任务的效率高达61.4%,优于Gemini 2.5的56%。**GPT-5.1 (high)**的105 tokens/s则在创意生成中闪光,GoCodeo 2025编码指南推荐它用于快速原型迭代。
Kimi K2 Thinking的 82 tokens/s得益于其双模式设计:标准模式约 8 tokens/s,Turbo 模式高达 50-85 tokens/s。DataCamp 2025指南强调,它支持 200-300 次连续工具调用,在代理工作流中速度不减,远超DeepSeek-V3。Clarifai 2025比较显示,在编码和自动化任务中,其Turbo变体响应时间仅 0.2 秒,适用于交互式开发。
Speed排名的启示在于权衡:高速度往往伴随能耗增加。AI Index 2025报告提醒,Grok和Kimi K2的能效比(tokens/s per Watt)领先 20%,推动绿色AI发展。
价格排名:性价比之战,低价高能谁胜出?
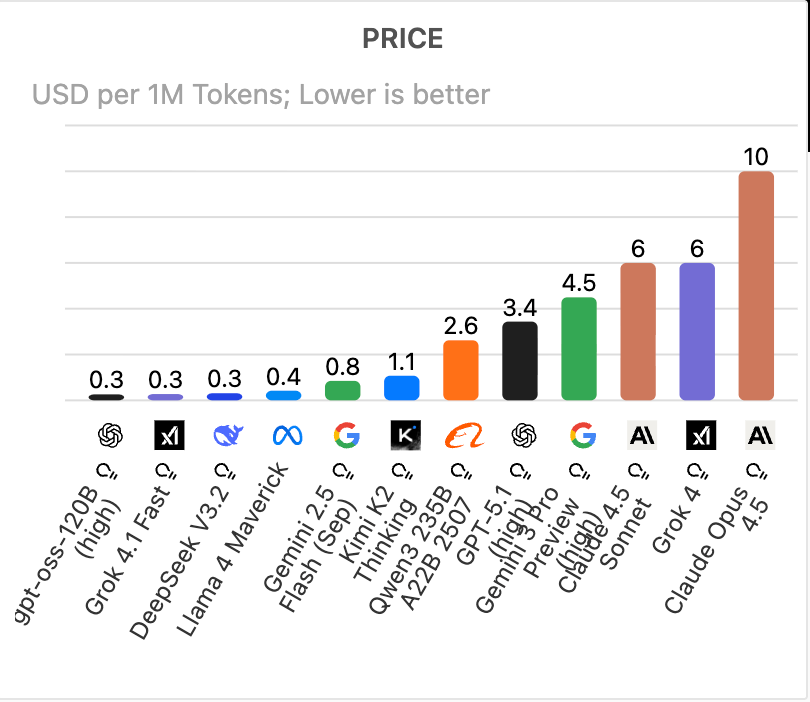
Price以USD per 1M Tokens(每百万令牌美元成本)计算,越低越亲民。排名中,gpt-oss-120B (high)、Grok 4.1 Fast和DeepSeek V3.2以0.3美元并列最低,Llama 4 Maverick(0.4美元)紧随,而Kimi K2 Thinking以1.1美元位列中游,Claude Opus 4.5高达10美元垫底。
低价模型的崛起是2025年AI民主化的缩影。Grok 4.1 Fast仅0.3美元/百万令牌,Intuition Labs分析显示,其价格仅为早期前沿模型的 1/12,却保留近SOTA(最先进)性能。xAI的策略聚焦高卷使用场景,如数据处理,Reddit 2025用户反馈:每月成本降至原先的1/5。
DeepSeek V3.2的 0.3 美元同样亮眼。Promptitude 2025比较中,它在嵌入式AI应用中脱颖而出,成本敏感开发者首选——Gemma 3n E4B变体仅0.03美元,适合移动端。开源Llama系列的价格优势更明显,Instaclustr报告称,Llama 3.2 1B免费部署后,每百万令牌成本接近零,训练仅需300美元。
Kimi K2 Thinking的 1.1 美元/百万令牌(标准模式0.60输入/2.50输出)虽高于最低,但其开源性质和代理能力提供极高ROI。VentureBeat 2025报告指出,与GPT-5的10美元相比,它成本低10倍,却在关键基准中胜出;Turbo 模式虽升至 8 美元输出,但速度提升 3 倍,适合企业自动化。Recode China AI 2025强调,其总运行成本仅 356 美元/基准测试,远低于Grok 4的 1172 美元。
高价如Claude Opus 4.5(10美元)虽贵,但价值匹配。eWeek 2025评测指出,其企业级安全性和代理行为(Agentic Reliability)在RAG(检索增强生成)中ROI(投资回报)最高,适合金融合规。
Price维度凸显“低成本LLM”浪潮。AI Index 2025预测,到2026年,80%的模型将低于1美元/百万令牌,推动AI普惠。
综合评价:平衡是王道,未来何去何从?
纵观三维度,Gemini 3 Pro Preview (high)在Intelligence领先,却在Speed 和 Price 中游;Grok 4.1 Fast 速度与价格双优,但智力稍逊;Claude 4.5 Sonnet 则全面均衡;Kimi K2 Thinking以中高智商、低训练成本和代理专长脱颖而出。Vellum AI 2025 leaderboard显示,Claude Opus 4.5的综合 Elo 分数达1402,位居前列。专业报告如Collabnix 2025强调,选择模型需视场景:编码选Claude或Kimi,实时选Grok,预算选Llama。
2025年的AI赛道竞争白热化,Stanford HAI 报告警示:基准之外,伦理与可持续性更关键。OpenAI 的 GPT-5 虽未上榜,但其“o”系列推理能力预示未来。展望 2026,多模态与边缘计算必将重塑排名。
关注公众号【AI信息风向】后,回复666,即可获取文章中所提到的AI行业报告。
AI技术正以前所未有的速度发展,它将如何塑造我们的未来?让我们拭目以待!

















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









