




 本文深入解析了TensorFlow中tf.one_hot()函数的使用方法,通过实例演示如何进行独热编码,适用于多分类问题,特别是在交叉熵损失函数的场景中。
本文深入解析了TensorFlow中tf.one_hot()函数的使用方法,通过实例演示如何进行独热编码,适用于多分类问题,特别是在交叉熵损失函数的场景中。
tf.one_hot()进行独热编码
首先肯定需要解释下什么叫做独热编码(one-hot encoding),独热编码一般是在有监督学习中对数据集进行标注时候使用的,指的是在分类问题中,将存在数据类别的那一类用X表示,不存在的用Y表示,这里的X常常是1, Y常常是0。
举个例子:
比如我们有一个5类分类问题,我们有数据(Xi,Yi),其中类别Yi有五种取值(因为是五类分类问题),所以如果Yj为第一类那么其独热编码为: [1,0,0,0,0],如果是第二类那么独热编码为:[0,1,0,0,0],也就是说只对存在有该类别的数的位置上进行标记为1,其他皆为0。这个编码方式经常用于多分类问题,特别是损失函数为交叉熵函数的时候。接下来我们再介绍下TensorFlow中自带的对数据进行独热编码的函数tf.one_hot(),首先先贴出其API手册
one_hot( indices,#输入,这里是一维的 depth,# one hot dimension. on_value=None,#output 默认1 off_value=None,#output 默认0 axis=None, dtype=None, name=None )
需要指定indices,和depth,其中depth是编码深度,on_value和off_value相当于是编码后的开闭值,如同我们刚才描述的X值和Y值,需要和dtype相同类型(指定了dtype的情况下),axis指定编码的轴。这里给个小的实例:
import tensorflow as tf
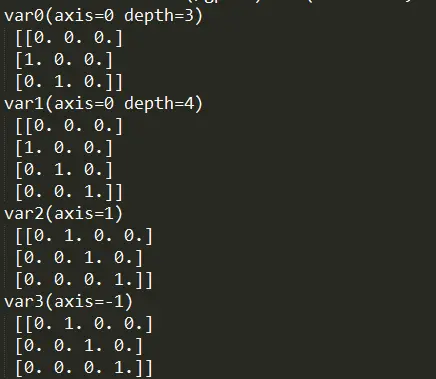
var0 = tf.one_hot(indices=[1, 2, 3], depth=3, axis=0)
var1 = tf.one_hot(indices=[1, 2, 3], depth=4, axis=0)
var2 = tf.one_hot(indices=[1, 2, 3], depth=4, axis=1)
# axis=1 按行排
var3 = tf.one_hot(indices=[1, 2, 3], depth=4, axis=-1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
a0 = sess.run(var0)
a1 = sess.run(var1)
a2 = sess.run(var2)
a3 = sess.run(var3)
print("var0(axis=0 depth=3)\n",a0)
print("var1(axis=0 depth=4P)\n",a1)
print("var2(axis=1)\n",a2)
print("var3(axis=-1)\n",a3)


















 3778
3778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









