



1. 概述
神经网络和深度学习技术发展到如今的程度,已经在各行各业得到了广泛的应用,但是,和人工智能的初衷——人类智能之间的偏差也越来越明显,譬如说,在面对不同问题和场景的时候,人的大脑会使用不同的智能程度去做不同的计算分析,然而,目前的深度学习计算却总是使用同样的智能程度去做计算和预测。
2. 案例
我们此处以六连子的连子棋对弈为例,首先来看如下两图所示的棋局:
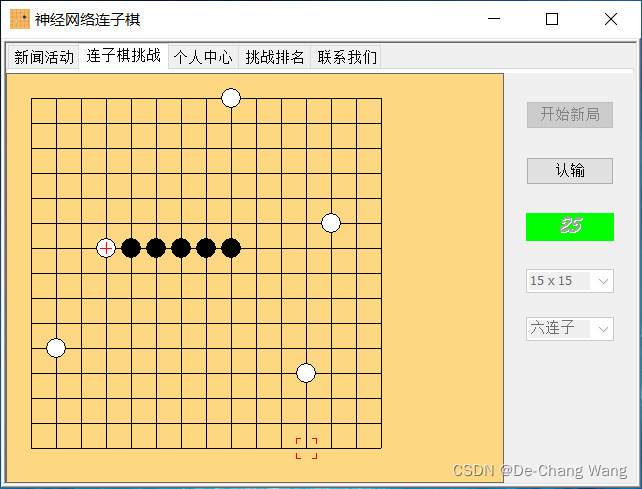
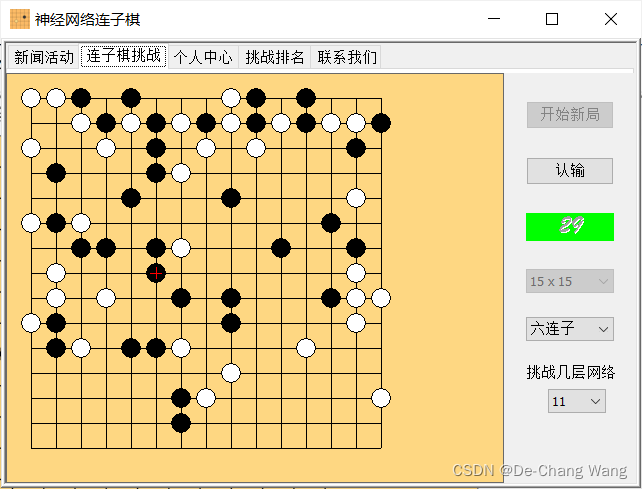
对于第一幅图所示的棋局,人类大脑会迅速分析思考出黑子的落子位置;而对于第二幅图所示的棋局,通常人类大脑会思考较长的时间,然后才能给出白子的较佳落子位置。即,人脑在不同棋局上所使用的智能程度是不同的,对应的,所消耗的精力和时间也是不同的。
但是,如果使用普遍的深度学习模型来进行预测的话,对于第一幅图和第二幅图的棋局,模型会使用相同的网络结构、相同的网络深度、相同的网络参数等进行计算和预测,对应的,所消耗的计算资源和时间等也是相同的,即,目前的深度学习技术对于同一个应用在所有的场景下都使用相同的智能程度。
3. 扩展和分析
由上述的案例不难得知,对于六连子的连子棋对弈的所有棋局,普遍的深度学习模型都是使用的相同的计算量和时间进行预测。扩展一下,对于其它的每一种应用,普遍的深度学习技术也都是使用的相同的计算量和时间进行计算,即智能程度是固定的。由此分析可知,深度学习模型的智能程度是应对能解决的最难场景的,而对于大多数较容易的场景来说,则会产生较多的算力资源和时间的浪费,同时也不利于在保证现有性能的前提下优化算法和模型来解决更困难的场景。
例如:对于车牌识别这个应用,距离车牌的远近不同、看车牌的角度不同、周围的光照强度不同、车牌的污损程度不同都会对识别算法有不同的要求,目前普遍的做法是将所有这些场景的车牌照片都收集起来进行训练,用训练出的模型对所有场景进行车牌识别。即便近距离站在车牌正前方拍的照片也要用相同的智能程度、相同的算力和时间进行分析识别。如果后期要优化算法,要增加识别距离等,还需要在优化的同时考虑是否对上一版本已经解决的场景产生了不良的效果。
相对的,人脑在进行车牌识别的时候则会根据不同场景选择不同的智能程度、使用不同的时间识别出车牌,例如,站在车辆正前方看车牌时立刻能识别出来,而傍晚时分站在100米远的地方则需要盯着仔细看一会儿才能看清并识别出车牌。
当然了,在目前的人工智能应用中,也有通过附加条件来选择不同的模型,以达成不同的智能程度切换的,譬如说,有的应用会增加光照强度的判断,通过阈值选择不同的模型进行计算分析,例如,白天的光照情形选择白天用的模型,夜晚的光照条件选择夜晚用的模型。诸如此类的工程方法不在本文讨论的算法范畴之内,有兴趣的可以自行对比。
4. 总结
深度学习技术和模型应具备自动调整智能程度的能力,以便在不同难度的场景使用不同的智能程度,来减少总的算力和时间消耗,同时节约相应的能源和时间,也能更接近人工智能的初衷,更接近人脑的思考模式。
有兴趣的也可以参考“确定性神经网络”及对应的“神经网络连子棋”,该模型中会进行智能程度自动调节,对不同难度的棋局需要不同的预测和落子时间。


















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











