




 本文介绍了Kafka如何使用Reactor模式处理请求。客户端通过请求/响应方式与Broker交互,请求通过Acceptor线程分发到工作线程池。网络线程将请求放入共享队列,IO线程负责实际逻辑处理,如消息写入和读取。延时请求则由Purgatory组件缓存,等待满足条件后处理。Kafka的Broker参数如num.network.threads和num.io.threads控制线程数量以调整处理能力。
本文介绍了Kafka如何使用Reactor模式处理请求。客户端通过请求/响应方式与Broker交互,请求通过Acceptor线程分发到工作线程池。网络线程将请求放入共享队列,IO线程负责实际逻辑处理,如消息写入和读取。延时请求则由Purgatory组件缓存,等待满足条件后处理。Kafka的Broker参数如num.network.threads和num.io.threads控制线程数量以调整处理能力。
kafka是如何处理请求的?
引言
kafka的客户端和Borker之间的交互都是通过“请求/相应”的方式完成的。就像:客户端通过网络发送消息给Broker,Borker发送相应给客户端。
kafka自己定义了一组请求协议,用于实现各种交互操作。比如:PRODUCE请求用于生产消息,FETCH请求用于消费消息,METADATA请求用请求kafka集群元数据信息。
kafka的请求处理:Reactor 模式
Reactor模式是时间驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发送请求的场景。
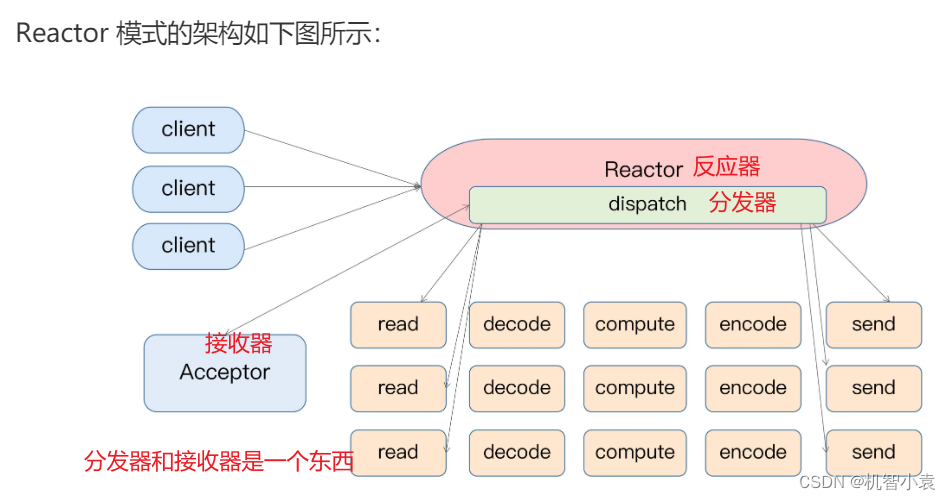
客户端会将请求发给Reactor反应器,Reactor有一个请求分发线程dispatch,也就是Acceptor,它会将请求分发给多个工作线程处理。
在这个架构中,Acceptor线程只是用于请求分发,不处理具体的逻辑业务,很轻量级,所以有很高的吞吐量表现。并且工作线程可以根据业务需要任意增减,从而实现动态调节系统负载能力。
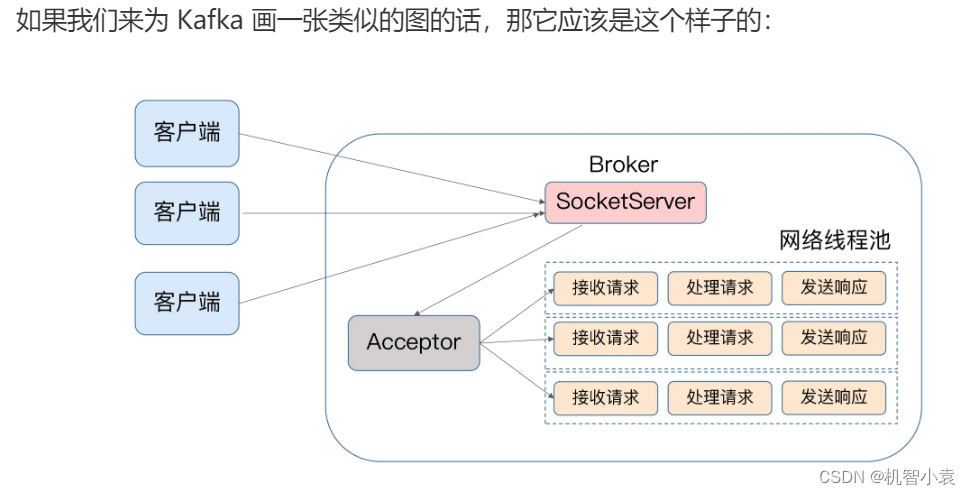
kafka的Broker端有个SocketServer组件,类似于Reactor模式中的Dispatcher,它也是有Acceptor线程和一个工作线程池,在kafka中工作线程叫网络线程池。kafka提供了Broker端参数num.network.threads,用于调整该网络线程池的线程数。其默认值是3,表示每台Broker启动时会创建3个网络线程,专门处理客户端发送的请求。
Acceptor线程采用轮询的方式将入站请求公平的发到所有网络线程中,因此在实际使用过程中,这些线程通常有相同的机率被分配到待处理请求。比较公平。
至此请求已经到达了网络线程,那到达网络线程之后是如何处理的呢?看下图:
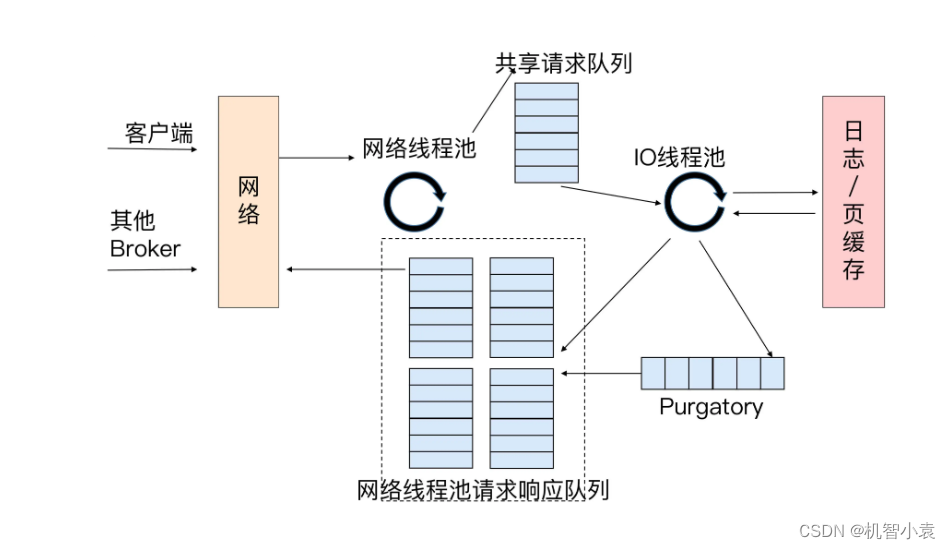
网络线程不会真正的处理逻辑,它会将收到的请求加入到共享请求队列中,之后由IO线程池中的线程进行真正的逻辑处理,即:将消息写入底层磁盘日志,以及从磁盘或缓存中读取消息。
IO线程池中的线程才是真正执行请求逻辑的线程。Broker端参数num.io.threads控制了这个线程池中的线程数。目前该参数的默认值是8,表示每台Broker启动后自动创建8个IO线程处理请求。
再继续向后看我们会发现请求队列是所有网络线程共享的,但是相应队列则是每个网络线程专属的。这个设计的原因是响应数据只需要网络线程自己发送给客户端就可以了,与其他组件已经没关系了。所以也就不用放在一个公共的地方了。
还有一个东西:Purgatory组件。这个组件是用来缓存延时请求的。就是那些一时未满足条件不能立刻处理的请求。比如设置了acks=all之后的PRODUCE请求,必须等待ISR中的所有副本都接收到了消息才能返回,此时处理该请求的IO线程就必须等待其它Broker的写入结果。等满足条件再继续处理该请求。

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









