




 本文深入解析数据库索引的概念,包括其工作原理、优缺点及如何高效使用。涵盖BTree、B+Tree、聚簇和非聚簇索引,并探讨索引在MySQL存储引擎中的实现。
本文深入解析数据库索引的概念,包括其工作原理、优缺点及如何高效使用。涵盖BTree、B+Tree、聚簇和非聚簇索引,并探讨索引在MySQL存储引擎中的实现。
什么是索引?
“索引”是存储引擎用于快速查找记录的一种数据结构。比如一本书的目录,就是这本书的内容的索引,读者可以通过在目录中快速查找自己想要的内容,然后根据页码去找到具体的章节。
数据库也是一样,如果查询语句使用到了索引,会先去索引里面查询,取得数据所在行的物理地址,进而访问数据。
索引的优缺点
- 优势:
- 索引大大减少了服务器需要扫描的数据量
- 索引帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O
- 缺点:
- 索引本身也是表,因此会占用存储空间。索引的维护和创建需要时间成本,这个成本随着数据量增大而增大
- 构建索引会降低数据表的修改操作(删除,添加,修改)的效率,因为在修改数据表的同时还需要修改索引表
索引的使用原则
- 对经常更新的表就避免对其进行过多的索引,对经常用于查询的字段应该创建索引,
- 数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
- 在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可以建立索引。
索引的分类
在MySQL中,常见的索引类型有:主键索引、唯一索引、普通索引、全文索引、组合索引。创建语法分别为:
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
ALTER TABLE 'table_name' ADD UNIQUE index_name('col');
ALTER TABLE 'table_name' ADD INDEX index_name('col');
ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col');
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3');
其中,组合索引又称为多列索引,上述代码中最后一个例子就是建立了3列的索引。MySQL在根据索引查询时,会遵循“最左匹配”原则,即先根据col1的条件查寻,再根据col2的条件查,然后再根据col3的条件去查。
最左匹配原则:InnoDB是基于B-Tree数据结构来实现的,B-Tree会建立从左到右的树形结构。假设索引index(name, age),会先匹配name字段,如果name相同,然后再去匹配age字段,最后找到数据。如果有这么一条SQL:
SELECT * FROM TABLE WHERE AGE = 20;这种情况下B-Tree不知道下一步该查询那个节点,从而导致索引失效。
如果跳过了一个列直接查后面的列,比如下面的语句,就不能使用上面创建的索引了:
SELECT * FROM table_name WHERE clo2=2;
对于某列如果是字符串且比较长(比如UUID),推荐使用前缀索引,即匹配前n个字符。具体这个n取值多少是根据你的数据来的,《高性能MySQL》里提供了一个技巧:通过使用LEFT函数查询,从1开始,不断增加n的值,直到查询结果的行数接近完整列的查询结果的行数,就是合适的n的值。
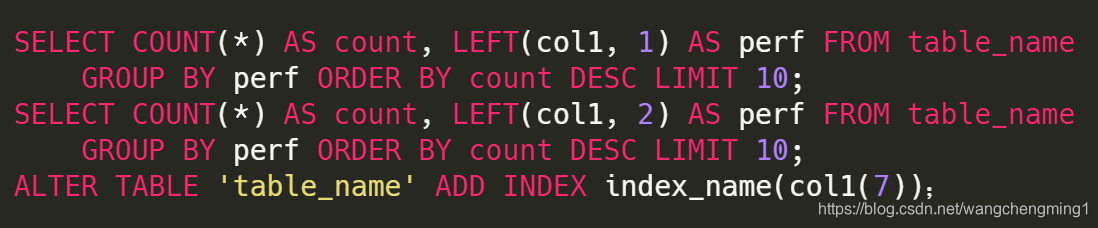
索引的实现原理
MySQL的索引是由存储引擎来实现的。由于存储引擎不同,所以具有不同的索引类型,如BTree索引、B+Tree索引、哈希索引等。这里由于主要介绍BTree索引和B+Tree索引,我们平时使用最多的InnoDB引擎就是基于B+Tree索引的。
-
从二叉搜索树聊起
-
了解过数据结构的朋友应该知道一种叫二叉树的数据结构。二叉树根据用途不同,衍生了不同的变种,比如堆,比如二叉搜索树。
-
而二叉搜索树中,为了防止极端情况树的高度过大影响查询效率,所以衍生出了一些平衡二叉查找树,最典型的就是AVL和红黑树。
-
但二叉树在数据量较大时,深度过深,不太适合数据库的查询,所以数据库使用了多叉树。
-
-
BTree
BTree(又称为B-Tree)是一个平衡搜索多叉树。BTree的结构如下图:
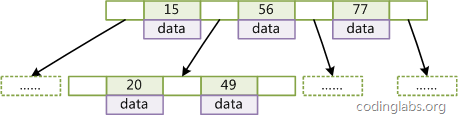
设树的度为2d(d>1),高度为h,那么BTree有以下性质:
1.每个叶子结点的高度一样,等于h;
2.每个非叶子结点由n-1个key和n个指针组成,key和指针相互隔离,结点两端一定是key
3.叶子结点指针为null;
4.非叶子结点的key都是[key,data]二元组,其中key表示作为索引的键,data为键值所在行的其它列的数据;
在BTree中,对索引列是顺序存储的,所以很适合查找范围数据和ORDER BY操作。
- B+Tree
B+Tree是BTree的一种变种。B+Tree和BTree的不同主要在于:
1.B+Tree中的非叶子结点不存储数据,只存储键值;
2.B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应data数据的物理地址;
3.B+Tree的每个非叶子节点由n个键值key和n个指针point组成;
结构图:
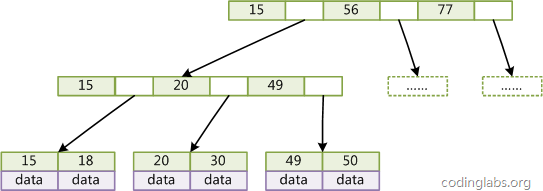
- B+Tree对比BTree的优点
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构。
磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4K,数据库的页通常设置为操作系统页的整数倍,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找。
已知内存的读取速度是外存读取I/O速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘I/O,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
聚簇索引和非聚簇索引
MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,分别实现了聚簇索引和非聚簇索引。
前段时间看到一个问题:“你知道为什么InnoDB非主键索引普遍比主键索引要慢吗?”答案是InnoDB使用了聚簇索引,主键索引只需要查询一次,而非主键索引需要查询两次。
为什么非主键索引需要查询两次呢?且看接下来的内容。
- 主索引与辅助索引
首先介绍一下基础的概念。在索引的分类中,我们可以按照索引的键是否为主键来分为“主索引”和“辅助索引”,使用主键键值建立的索引称为“主索引”,其它的称为“辅助索引”。因此主索引只能有一个,辅助索引可以有很多个。
为什么需要用到辅助索引?因为前面我们介绍了,查询语句如果想要使用索引,是需要满足最左匹配原则的。有时候我们的查询并不会使用到主键列,所以需要在其它列建立索引,即辅助索引。
- 非聚簇索引
非聚簇索引的主索引和辅助索引几乎是一样的,只是主索引不允许重复,不允许空值,他们的叶子结点的key都存储指向键值对应的数据的物理地址。
非聚簇索引的数据表和索引表是分开存储的。非聚簇索引中的数据是根据数据的插入顺序保存。因此非聚簇索引更适合单个数据的查询。插入顺序不受键值影响。
- 聚簇索引
聚簇索引的主索引的叶子结点存储的是键值对应的数据本身,辅助索引的叶子结点存储的是键值对应的数据的主键键值。因此主键的值长度越小越好,类型越简单越好。
聚簇索引的数据和主键索引存储在一起。
聚簇索引的数据是根据主键的顺序保存。因此适合按主键索引的区间查找,可以有更少的磁盘I/O,加快查询速度。但是也是因为这个原因,聚簇索引的插入顺序最好按照主键单调的顺序插入,否则会频繁的引起页分裂(BTree插入时的一个操作),严重影响性能。
在InnoDB中,如果只需要查找索引的列,就尽量不要加入其它的列,这样会提高查询效率。
一张图说明聚簇索引与非聚簇索引的区别:
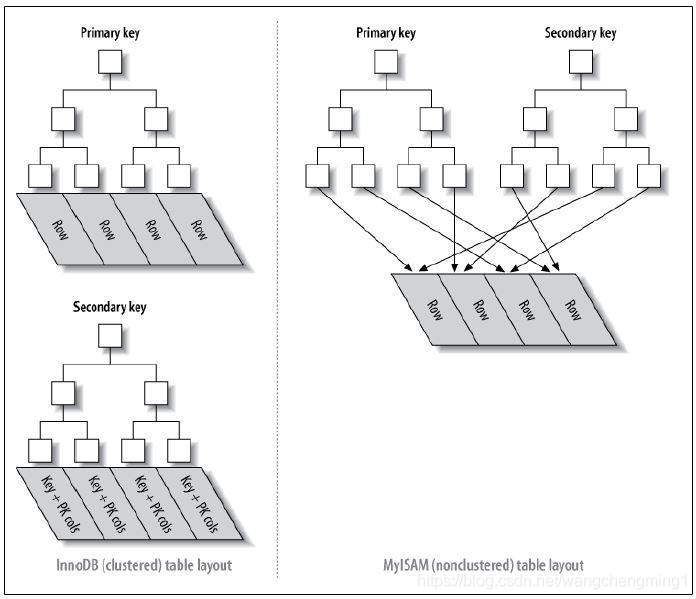
聚簇索引就是叶子节点中存储的就是完整的行数据,索引和数据存储在一起;而非聚簇索引的索引文件和数据文件是分开的,所以查询数据会多一次查询。
覆盖索引
常见的方式就是建立组合索引(联合索引)进行索引覆盖,什么是索引覆盖呢?索引覆盖就是索引的叶子节点已经包含了查询的数据,没必要再回表进行查询。
假如我有一个索引index(name),然后执行如下sql:select name, age, sex from employee where name =‘as’; 因为普通索引只有name字段才建立了索引,这必然会导致回表查询。
为了提高查询效率,就(name)单列索引升级为联合索引(name, age, sex)就不同了。
因为建立的联合索引,在二级节点的叶子阶段就会同时存在name, age, sex三个的值,一次性就会获得所需要的数据,这样就避免了回表,但是所有的方案都不是完美的。
若是这个联合索引哪一天某一个数据行的name值改变了或者age改变了,我就需要同时维护主键索引和联合索引两棵树,这样的维护成本就高了,性能开销也大了。
相比之前数据的改变,我只需要维护主键索引即可,联合索引的创建就导致了需要同时维护两棵树,这样就会影响插入、更新数据的操作,所以并没有哪种方案是完美的。
参考资料
《高性能MySQL》

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









