




Redis通常是用来做缓存来使用的,使用缓存可以显著的提高程序的性能。但是在高并发的时候也容易出现一些问题。
缓存雪崩
缓存雪崩的问题可能是最常见的问题了,大家可能都遇到过。所谓缓存雪崩指的是大量key在同一时间大面积失效,请求缓存的时候请求不到,这个时候就会全都打到数据库中。针对缓存雪崩常见的解决方案有:
- 给key设置失效时间的时候加一个随机值,这样子就不会造成大量的key在同一时间失效
- 针对热点数据的key设置永不过期
- 使用分布式缓存集群(持久化、主从复制、哨兵和集群)
当然还有很小的几率以上的方案还是没有抵挡住缓存雪崩,那么我们就需要做限流处理,尽量保证我们的数据库不被打死,只要数据库不挂掉我们的服务就是可以用的。
缓存穿透
假如用户想查询一个商品信息,这个时候用id = -1去调getProduct(Long id)查询商品信息,这个时候缓存中没有数据,数据库也没有数据,如果没有做参数合法性校验的话,用户频繁的请求接口,就会给数据库造成很大的压力,严重的情况可能会导致数据库挂掉,从而导致服务不可用。
所谓缓存穿透就是用户访问一个缓存和数据库中都不存在的数据,导致每次都要查询一次缓存和数据库,这种情况就叫做缓存穿透。缓存穿透常见的解决方案有:
- 对请求参数做合法性校验,比如
id <= 0时,直接返回参数不正确,这一步是必须要做的 - 如果缓存和数据库都不存在,这个时候在缓存中给这个key的value设置成null,这样子下次请求就可以存缓存中拿到null,从而不必再次请求数据库。但是这个key的过期时间应该设置比较短的时间,比如10s,防止数据库中更新了值,用户不能及时的取到。
- 使用布隆过滤器(BloomFilter),判断一个key是否已经查过了,如果已经查过了,就不去数据库查询。
缓存击穿
缓存击穿和缓存雪崩有点像,所谓缓存击穿指的是一个热点key在不断的抗住大并发,但是这个key过期了,就会导致很多的请求一下子全都打到了数据库,一下子就把数据库打挂了,从而导致了服务瘫痪。常见的解决方案有:
- 同样还是要做参数的合法性校验
- 针对热点数据可以将key的过期时间设置的长一点,甚至有些热点key可以设置永不过期
- 使用互斥锁,在请求数据的时候锁住,返回结果后将值设到缓存中,然后再释放锁,下面写一段伪代码
public static String getData(String key){
// 从redis中读取数据
String value = getDataByRedis(key);
// 锁住
if(StringUtils.isBlank(value)){
if(lock.tryLock()){
value = getDataByDB(key);
// 放到redis中
set2Redis(key, value);
lock.unLock();
}
}
return value;
}
数据库缓存双写不一致问题
首先我们先弄明白什么是双写不一致问题:双写不一致指的是缓存和数据库中的值不一样。
在使用数据库缓存的时候,读和写的流程往往是这样的:
- 读取的时候,先读取缓存,如果缓存中没有,就直接从数据库中读取,然后取出数据后放入缓存
- 更新的时候,先删除缓存,再更新数据库
所谓双写不一致,就是在发生写操作(更新)的时候或写操作之后,可能会存在数据库里面的值和缓存中的值不同的情况。
为什么更新的时候要先删除缓存,再更新数据库?因为如果先更新数据库,然后在删除缓存的时候失败了,就会造成缓存里面的值和数据库的值不一致。
然而这样并不能完全避免双写不一致问题。假设在大并发情景下,一个线程先删除缓存,然后取更新数据库,这个时候另一个线程去取缓存,发现没有值,于是去读数据库,然后把数据库旧的值设置进缓存。等第一个线程更新完数据库后,数据库里面就是新的值,而缓存里面是旧的值,所以就存在了数据不一致的问题。
-
一个比较简单的解决办法是把过期
时间设置得比较低,这样就只有在缓存没过期之前存在数据不一致问题,在一些业务场景下也还能接受。 -
另一种解决方案是
使用队列辅助。先更新数据库,再删除缓存。如果删除失败,就放进队列。然后另一个任务从队列中取出消息,不断去重试删除相应的key。 -
还有一种解决方案是
对一个数据使用一个队列,使读写操作串行化。比如对id为n的数据建立一个队列。对这条数据的写操作,删除缓存后,放进一个队列;然后另一个线程过来了,发现没有缓存,则把这个读操作也放进这个队列里面。不过这样会增加程序的复杂性,串行化也会降低程序的吞吐量,可能得不偿失。一般主流的解决方案还是先删除缓存,再更新数据库。可以满足绝大部分需求。
Redis相比Memcached有哪些优势
- 首先redis支持更加丰富的数据结构,而Memcached只有String类型
- redis是支持RDB和AOF持久化的,而Memcached是不支持持久化的
- redis支持集群模式(Redis Cluster),而Memcached不支持集群的
- redis在2.6以后支持事务,而Memcached不支持事务
Redis为什么快
- redis是完全基于内存的,就像HashMap一样,时间复杂度是O(1)
- Redis使用的是非阻塞I/O,I/O多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争
- redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争
- redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大
- 最主要的redis定义了自己的数据结构,请看这篇文章
Redis哨兵
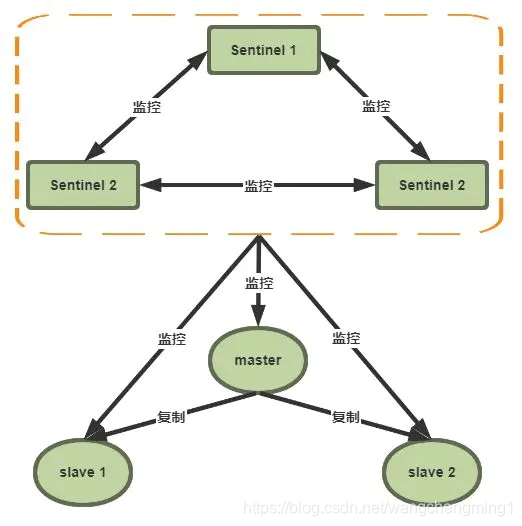
哨兵必须用三个实例去保证自己的健壮性,哨兵 + 主从 并不能保证数据不丢失 ,但是可以保证集群的高可用。工作原理:
- 每个 Sentinel 节点以每秒一次的频率向它所知的主服务器、从服务器和其他 Sentinel 节点发送一个 PING 命令
- 如果 一个实例举例最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 所指定的值,那么这个实例就会被标记为主观下线
- 如果一个主服务器被标记为主观下线,那么正在监视这个服务器的所有 Sentinel 节点会以每秒一次的频率确认主服务器的确进入了主观下线状态
- 如果有足够数量的 Sentinel (至少要达到配置文件中指定的数量)在指定的时间范围内同意这一判断,那么这个主服务器就会被标记为客观下线
- 当主服务器被标记为客观下线后,Sentinel 节点会向下线主服务器的所有从服务器发送 INFO 命令的频率从 10 秒一次改为每秒一次
- Sentinel 节点会协商客观下线主服务器的状态,如果处于 SDOWN 状态,则投票自动选出新的主节点,将剩下从节点指向新的主节点进行数据复制。
- 当没有足够数量的 Sentinel 节点泳衣主服务器下线是,主服务器的客观下线状态就会被移除。或者当主服务器重新向 Sentinel 的 PING 命令返回有效回复是,主服务器的主观下线状态就会被移除
Redis集群原理
Redis Sentinel(哨兵)着眼于高可用,在master 宕机时会自动将slave提升为master,继续提供服务。Redis Cluster(集群)着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。选主策略:
- slave 的 priority 设置的越低,优先级越高
- 同等情况下,slave 复制的数据越多优先级越高
- 相同的条件下,runid 越小越容易被选中


















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









