




这个系列介绍如何利用DeepSeek辅助编程实现特定功能的几个具体案例。
针对之前文章的视频文字提取中长视频提取文字会出现提取失败问题,提供代码修改方案。视频文字提取(一)
将视频提取出来的音频分段切割处理:
将切割完的音频进行处理,最后在合并成一个提高识别准确率。
temp_audio.wav最后针对这个音频文件进行文字提取最后保存为txt格式;
完整代码如下:
from moviepy.editor import VideoFileClip
from pydub import AudioSegment
import speech_recognition as sr
import os
import time
# 视频文件路径
video_path = 'D:/program/DeepSeek/视频文件/11.mp4'
# 音频文件路径
temp_audio_path = 'temp_audio.wav'
processed_audio_path = 'D:/program/DeepSeek/视频文件/temp_audio-example.wav'
# 设置每段音频的最大时长(秒)
chunk_length = 60 # 每段音频最大1分钟
# 加载视频文件并提取音频
video = VideoFileClip(video_path)
audio = video.audio
audio.write_audiofile(temp_audio_path)
# 载入音频文件
audio = AudioSegment.from_wav(temp_audio_path)
audio = audio.set_channels(1)
audio = audio.set_frame_rate(16000)
audio.export(processed_audio_path, format="wav")
# 初始化语音识别器
recognizer = sr.Recognizer()
def split_audio(audio, chunk_length):
"""将音频按时长切分成多个片段"""
chunks = []
duration = len(audio) # 获取音频总时长(毫秒)
for i in range(0, duration, chunk_length * 1000):
chunk = audio[i:i + chunk_length * 1000]
chunk_path = f"temp_chunk_{i // 1000}.wav"
chunk.export(chunk_path, format="wav")
chunks.append(chunk_path)
return chunks
def recognize_audio_chunk(chunk_path):
"""识别音频片段中的语音并返回文本"""
with sr.AudioFile(chunk_path) as source:
audio_data = recognizer.record(source)
try:
text = recognizer.recognize_google(audio_data, language='zh-CN') # 假设音频语言为中文
return text
except sr.UnknownValueError:
print(f"无法识别音频文件 {chunk_path}")
return ""
except sr.RequestError:
print(f"请求失败,无法连接到 Google Speech Recognition 服务")
return ""
def main(video_path):
# 分割音频
audio_chunks = split_audio(AudioSegment.from_wav(processed_audio_path), chunk_length)
all_text = ""
# 逐个识别每个音频片段
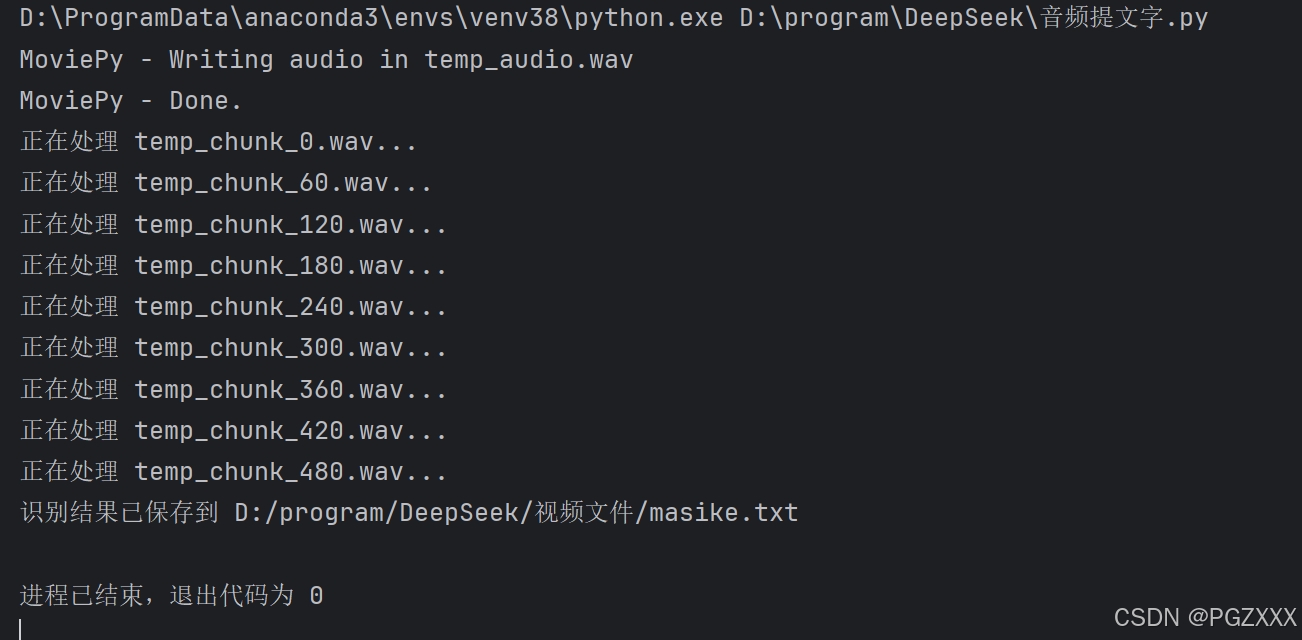
for chunk in audio_chunks:
print(f"正在处理 {chunk}...")
text = recognize_audio_chunk(chunk)
all_text += text + "\n\n"
# 删除处理过的临时音频文件
if os.path.exists(chunk):
os.remove(chunk)
# 可以加个延时,避免频繁请求
time.sleep(1)
# 保存识别结果到文本文件
txt_file_path = 'D:/program/DeepSeek/视频文件/masike.txt' # 设定保存文本的路径
with open(txt_file_path, 'w', encoding='utf-8') as f:
f.write(all_text)
print(f"识别结果已保存到 {txt_file_path}")
# 清理临时文件
os.remove(temp_audio_path)
os.remove(processed_audio_path)
# 运行程序
main(video_path)
最后一个问题是提取出来的文字没有分段和标点符号,解决方案是将文件发给deepseek进行处理加上标点符号和分段。
 完整的文字识别结果如下:
完整的文字识别结果如下:
马斯克的这个2025年的最新预测,强烈建议所有想抓住未来机会的人必须要看,而且是反复看。这一次,老马在CS上关于2025年的预言说了太多颠覆性的内容,我自己就看了好几遍。在这场访谈中,马斯克展现出他对人类未来的完整布局,从AI的大脑到机器人的身体,再到自动驾驶的突破,然后是脑机接口的进化和火星殖民的跨越。这是一个从地球到太空,从人类到超人类的宏大蓝图。不得不说,像老马这样的人在这个时代出现,一定是天意。接下来呢,我就用马斯克的原话加上一点自己的理解,跟大家分享一下他到底说了些什么。视频可能比较长,但绝对会帮你更好地理解未来,记得先点赞收藏。
第一部分,AI将成为人类历史上最大的变革。马斯克一开场就抛出一句重量级的话:“我不想让你们感到惊讶,但我敢肯定,AI将变得非常强大。”其实早在五年甚至10年前,马斯克就预言了AI的智能将远远超过人类,但是当时很多人都不以为然,甚至一些人认为这个想法很荒谬。但是现实啪啪打脸了,现在的AI系统已经能够通过各种专业考试,在医疗诊断方面的表现超过了80%的医生,特别是在影像分析领域,比很多资深专家还要准确。更关键的是,马斯克还提到了一个重要事实:去年AI已经完成了一个历史性的突破,它学完了人类积累的所有知识,包括所有的书籍、互联网和有价值的视频内容。所以现在AI已经开始自己合成数据,自己训练自己。接下来的预测更加重磅,马斯克说未来的三到四年内,除了体力活,AI几乎能完成所有脑力工作。这让我想起了互联网上一个著名的梗:原本我们期待机器人能够帮我们分担家务,让我们有更多的时间去追求诗和远方,现实却是机器人开始写诗画画,而人类却还在扫地洗碗。这是一个残酷的事实,不过老马紧接着就给出了他的解决方案。
第二部分,马斯克谈到了特斯拉的人形机器人和自动驾驶汽车。有了它们,AI才能从虚拟世界走向物理世界,把人类从体力劳动中解放出来。在机器人领域,马斯克展现出了前所未有的信心。他说擎天柱将成为历史上最大的产品,比任何其他产品都重要,每个人都可能想要拥有一个自己的机器人伙伴。马斯克还提到了擎天柱的具体产量计划:今年先生产几百到几千台,明年提升到五到十万台,后年再提升十倍,达到五十到一百万台。而且马斯克预测,未来机器人的数量可能会超过人类,达到人类数量的三到五倍。也就是说,地球上可能会出现数百亿个机器人。他说这不仅将改变人类的生活方式,还会重塑全球的经济结构。到那时,我们不会是普遍基本收入,而是普遍高收入。机器人将为社会创造巨大的财富,让每个人都能享受更高的生活标准。
第三部分,老马认为自动驾驶将迎来重大突破。今年的二季度,特斯拉的自动驾驶系统就将比人类的驾驶员安全十倍。也就是说,只要再过几个月,我们就能见证这个历史性的时刻了。更让人惊讶的是,特斯拉实现这个目标不需要像其他公司那样依赖昂贵的激光雷达。马斯克解释说,人类只要用两只眼睛就能开车,那么为什么AI就需要激光雷达?我们的AI视觉系统已经超越了人类的感知能力。他还透露,特斯拉的自动驾驶系统每天要处理超过1亿次的人工感应数据,这些数据能不断训练和完善AI系统,让它变得越来越安全。马斯克认为,不久之后,让人类开车上路反而会变得不安全,就像今天让马在高速公路上奔跑一样不合适。
第四部分,更炸裂的是脑机接口将改变人类的进化方向。当主持人问到能不能在有生之年看到直接的大脑通信技术时,马斯克表示肯定。他还解释了目前人类的交流带宽其实很低,平均每人每天的信息输出还不到八万六千四百比特。但通过Neuralink,这个数字可能提升一千倍甚至一百万倍。马斯克的这项技术的愿景实在是太庞大了,如果真的可行,未来每一个人都将是超级人类。
第五部分,就是火星殖民。这是马斯克最具野心的布局,也是到现在都有很多人表示不理解的布局。但是马斯克的信念是,地球文明必须成为多行星文明,这不是选择,这是必然。我们必须在有能力的时候就开始行动,而不是等到被迫行动的时候。具体到时间表,马斯克表示:“我认为我们两年内可以发射第一艘无人飞船前往火星。地球和火星的轨道每两年都会同步一次,我们现在正处于同步点,下一次同步大约在两年之后,再下一个就是再两年之后。第一次任务的关键是确保星舰能够安全着陆,而不是增加火星表面的陨石坑数量。如果星舰成功着陆,那么下一次任务就可能会送人上去。”马斯克强调,这不是一个商业项目,而是关乎人类文明的进程。从更大的视角来看,评价一个文明的标准之一是这个文明是局限于单一星球,还是已经成为多星球文明。我们不想成为那些只停留在一个星球的失败文明,即使无法超越太阳系,我们至少要扩展到另一个星球。这就是马斯克的宏大愿景。
第六部分,未来已来,人类和AI共存。在这场访谈的最后,马斯克提出了一个深刻的问题:当AI和机器人能完成所有的工作,人类的生活意义从何而来?这不是一个遥远的未来。让我们回到最开始,马斯克的预测:未来的三到四年内,除了体力活,AI几乎能完成所有的脑力工作,而且随着机器人技术的发展,体力劳动也将被取代。说到这里,我的脑海里浮现出两个字:失业。但是马斯克对这个未来保持着惊人的乐观。他说,那个时候不需要人类工作,但是人类会进入一个普遍高收入的时代,因为AI和机器人将创造巨大的财富,以至于每个人都能过得上更好的生活。所以马斯克认为,未来的四五年非常乐观,我们将见证人类的黄金时代。
听完这场访谈,我突然明白了马斯克的整体布局:AI是引擎,机器人是躯体,自动驾驶是突破口,脑机接口是人类进化的方向,火星殖民是文明的跨越。我们将进入一个全新的时代,一个由AI驱动的时代,一个人类与机器共生的时代。面对这样的未来,我们需要的不仅仅是技术上的准备,更是心态上的转变。我们需要重新思考工作的意义,重新定义生活的价值。马斯克的宏大布局让很多人心潮澎湃,同时也让很多人感到不安。但是历史一次又一次地证明,改变世界的往往就是那些敢想敢做的人。这或许就是天才的远见,在别人还在担心馒头的时候,他已经在为人类的千年大计布局了。不管怎么样,现在的问题留给了我们每一个人:未来已来,我们准备好了吗?

















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









