




 层次注意力网络(HAN)是一种用于文本分类的神经网络模型,它通过层次化的结构捕捉文本的内在特征。HAN包含词级和句子级的注意力机制,使得模型能聚焦于文档中的关键信息。在多个大型文本分类任务中,HAN表现出色,优于传统的基于词袋模型的方法。HAN的创新之处在于利用上下文来决定哪些序列相关,而非简单地过滤上下文。模型由词级编码器、词级注意力、句子级编码器和句子级注意力组成,采用GRU单元进行信息整合。通过这种方式,HAN能够更好地理解和利用文本的结构信息,从而提高分类效果。
层次注意力网络(HAN)是一种用于文本分类的神经网络模型,它通过层次化的结构捕捉文本的内在特征。HAN包含词级和句子级的注意力机制,使得模型能聚焦于文档中的关键信息。在多个大型文本分类任务中,HAN表现出色,优于传统的基于词袋模型的方法。HAN的创新之处在于利用上下文来决定哪些序列相关,而非简单地过滤上下文。模型由词级编码器、词级注意力、句子级编码器和句子级注意力组成,采用GRU单元进行信息整合。通过这种方式,HAN能够更好地理解和利用文本的结构信息,从而提高分类效果。
HAN网络:
按照我的理解HAN网络是用于文本分类的,是对文本的一个向量表示。但表示过程是层次化的。
摘要
HAN网络有两大特点,1HAN是层次化的模型,可以暗示了文本本身具有的层次化特征2.使用了两级注意力机制,允许关注更重要的信息。在六个大型分类任务上都取得了良好的成绩。
介绍
文本分类是NLP的基本任务。目标是为一个文本联系一个标签。传统分类方法基于稀疏的从词特征,比如n_gram,再放入SVM中。如今神经网络已经在其中大规模应用。
虽然神经网络方法已经足够有效,但这篇文章表名,如果把文本结构集成到网络模型这种可以获得更好的结果。这篇文章动机在于,并非文档的所有部分都与回答问题同等相关,相关性涉及对单词的相互作用进行建模,而不仅仅是孤立的单词存在。
主要贡献是提出了一种新网络结构,层次注意力网络,来捕获两种在文档结构中洞察到的领悟。1.因为文档是层次化的,我们先建立构建文档的句子表示,在构建词表示。2.不同的词和句子在文档中信息不同,词和句子的意思高度依赖于上下文,同样的词在不同的句子中可能有不同的重要性。为了获取这个信息,我们使用了两层注意力模型,一层在单词级,一层在句子级。让模型能够更集中注意力在单词个体和句子个体。
与以前工作的关键区别在于,HAN使用上下文来发现序列何时相关,而不是简单地从上下文中筛选。
HAN
HAN模型:四部分组成,word级编码器,word级注意力,sentence级编码器,sentence级注意力
基于GRU
GRU使用门控机制但不使用额外的cell存储信息:
GRU有两个门 update门和reset门
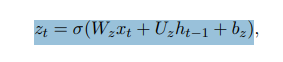
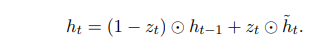
更新门负责内部状态更新
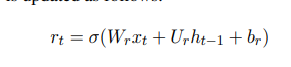
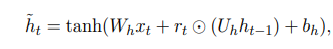
最终状态依靠复位门输出
层次化注意力
我们关系的是文本分类问题。假设有一个文档有L个句子,每个句子有Ti个单词。wit是第t个句子中第i个单词。该模型将原始文档投影为向量表示,并在此基础上构建分类器进行文档分类。在下面,我们将介绍如何使用层次结构构建文档,逐步从单词向量中提取向量。
单词编码器
给定一个句子由wit组成,第一步把单词转为词嵌入表示。
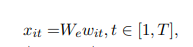
在此之上,我们使用双向GRU来汇总双向单词信息得到向量。
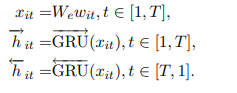
hit汇总了以wit为中心的两端的对单词的表示。除了直接使用词向量,我们还可以使用字符级别的嵌入来获得。
这样子每个单词就有了一个编码hit
单词注意力
不是每个单词对句子向量的构建都起到相同的作用,所以我们使用注意力机制来提取单词中的重要性信息,并且汇聚一个表示。
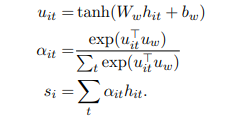
先使用单层MLP来获得一个hit的隐藏表示,然后uw作为上下文评分向量(这是可学习的)。然后获得一个分数,对hit进行加权相加。得到一个句子向量si。
句子编码器
给定句子向量,我们要计算文本向量。也使用双向GRU。
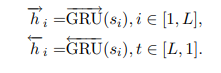
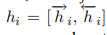
hit汇总了以wit为中心的两端句子的表示。
句子注意力
同样不同句子的重要性也是不同的。也使用一个注意力机制。
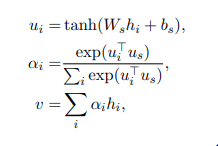
来得到一个文本向量表示。
文本分类
文本分类可以基于softmax分类。使用负对数极大似然。
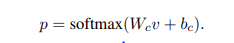
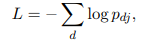
.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









