



 本文详细介绍了如何在CDPPrivateCloudBase中启用HDFS的多NameNode功能,包括先决条件、配置步骤、已知问题及解决方案。重点讲解了在ClouderaManager中启用支持,添加新NameNode的过程和遇到的问题处理方法。
本文详细介绍了如何在CDPPrivateCloudBase中启用HDFS的多NameNode功能,包括先决条件、配置步骤、已知问题及解决方案。重点讲解了在ClouderaManager中启用支持,添加新NameNode的过程和遇到的问题处理方法。
此功能为 CDP Private Cloud Base 提供了使用多个备用名称节点的能力。
先决条件
-
Cloudera Manager 版本必须为 7.7.1 或更高版本
-
CDP 包裹版本必须为 7.1.8 或更高版本
-
HDFS 应该启用高可用性
-
HDFS的最新升级必须完成
-
根据 Cloudera Manager,集群必须是健康的,并且没有任何陈旧的配置
此功能仅对 7.1.8 集群启用。这需要启用高可用性功能。在为集群配置额外的 NameNode 后,您无法回滚 Cloudera Manager 升级或 CDP 包升级。在升级到 718 完成后,您必须添加一个额外的名称节点。
多个 Namenodes 配置
Cloudera Manager 中默认不启用此功能。您必须首先在 Cloudera Manager 配置中启用此功能。然后,您可以使用多个备用 NameNode 配置 HDFS 服务。
在 Cloudera Manager 中启用多个名称节点支持功能
-
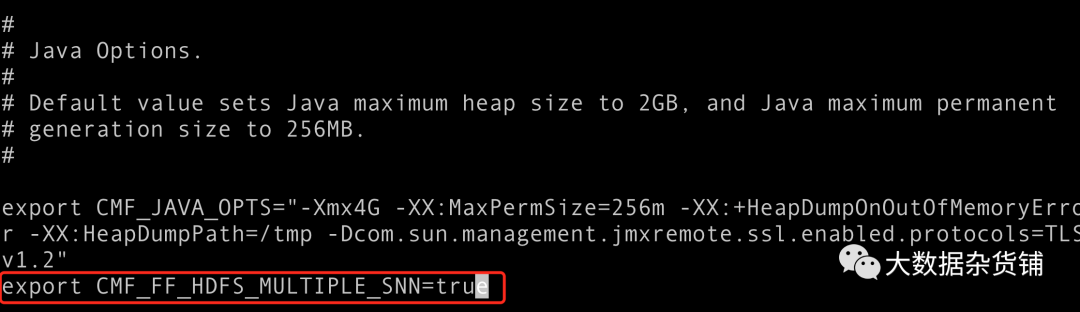
导航到/etc/default/cloudera-scm-server 文件。
-
在cloudera-scm-server文件的末尾 添加 export CMF_FF_HDFS_MULTIPLE_SNN=true 。
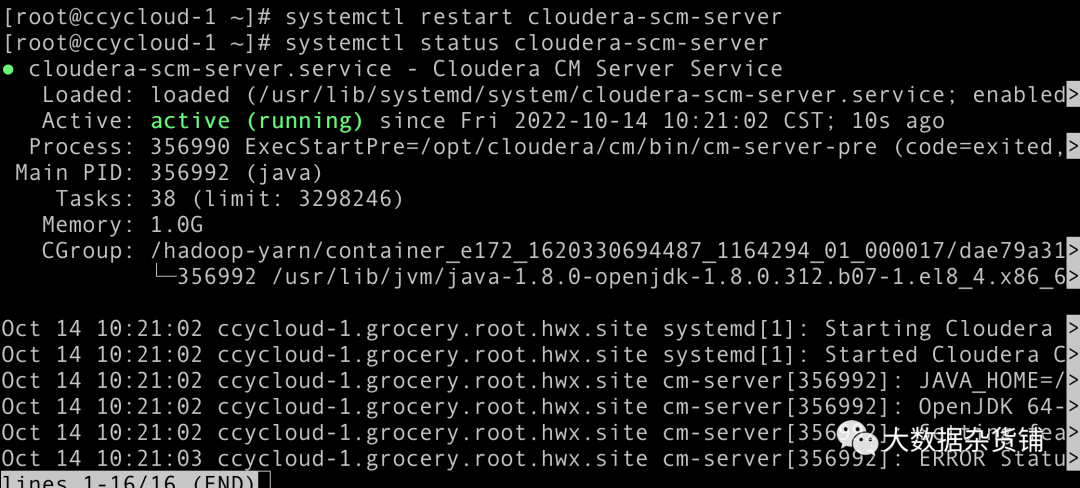
- 重新启动 Cloudera Manager服务。
systemctl restart cloudera-scm-server
已知问题及其解决方法
在继续进一步配置其他名称节点之前,您必须了解以下已知问题。
已知问题描述
如果最近在集群上重新启动了JournalNodes,如果在重新启动 JournalNodes 后没有创建新的fsImage ,则 HDFS 服务的添加新 NameNode向导可能无法引导新的 NameNode 。但是,在重新启动 JournalNodes 时,编辑日志会在系统中滚动。
已知问题解决方法
如果在Add new NameNode向导期间引导失败,您必须执行以下步骤:
-
删除新添加的NameNode和FailoverController
-
将活动的 HDFS NameNode 移动到安全模式
-
在活动的 HDFS NameNode 上执行 Save Namespace 操作
-
在活动的 HDFS NameNode 上离开安全模式
-
尝试再次添加新的 NameNode
笔记
进入安全模式会禁用对 HDFS 的写入操作并导致服务中断。如果无法进入安全模式,只需删除HDFS服务中新添加的NameNode和FailoverController即可。您必须等到 HDFS 自动创建新的 fsImage 并尝试使用向导再次添加新的 NameNode。
使用 HDFS 服务添加多个名称节点
您必须确保 Cloudera Manager 处于干净状态,没有任何健康问题并且集群上没有陈旧的配置。如果存在任何运行状况问题或过时的配置,那么您必须与命令分开重新启动集群,而不是在命令中。为此,您必须清除Rolling Restart HDFS 和所有相关服务以激活步骤 10b 中的更改选项。此外,如果有任何健康问题或无法从集群中清除的陈旧配置,您必须单独重新启动集群。
可以使用 Cloudera Manager 中的 HDFS 服务添加多个名称节点。
- Hdfs服务已经启用高可用
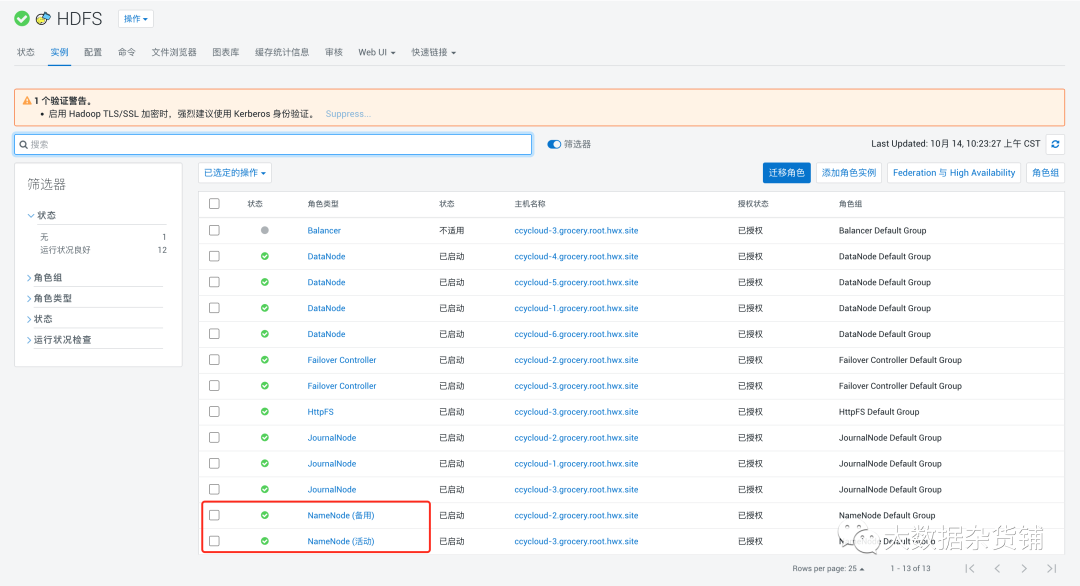
- 导航到集群,选择HDFS服务,然后转到实例,单击联邦和高可用性按钮
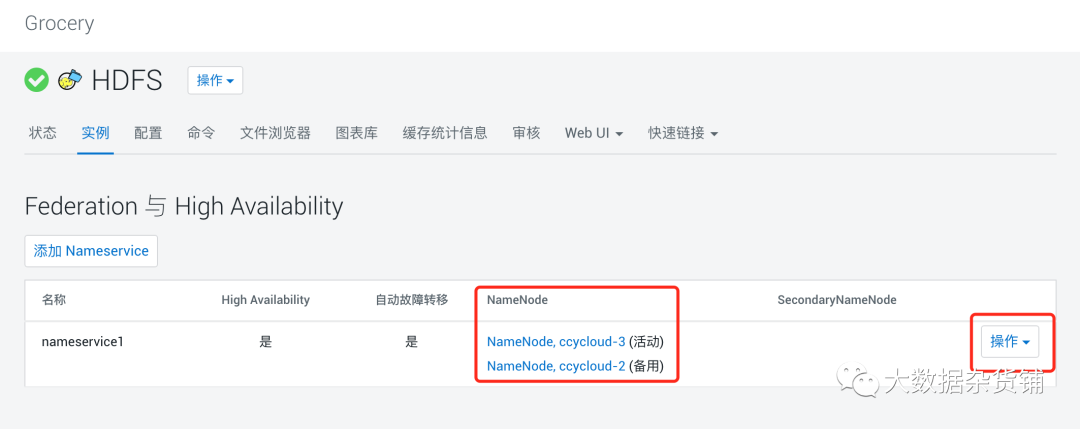
- 单击操作,单击添加其他名称节点。添加 其他 NameNode向导打开。
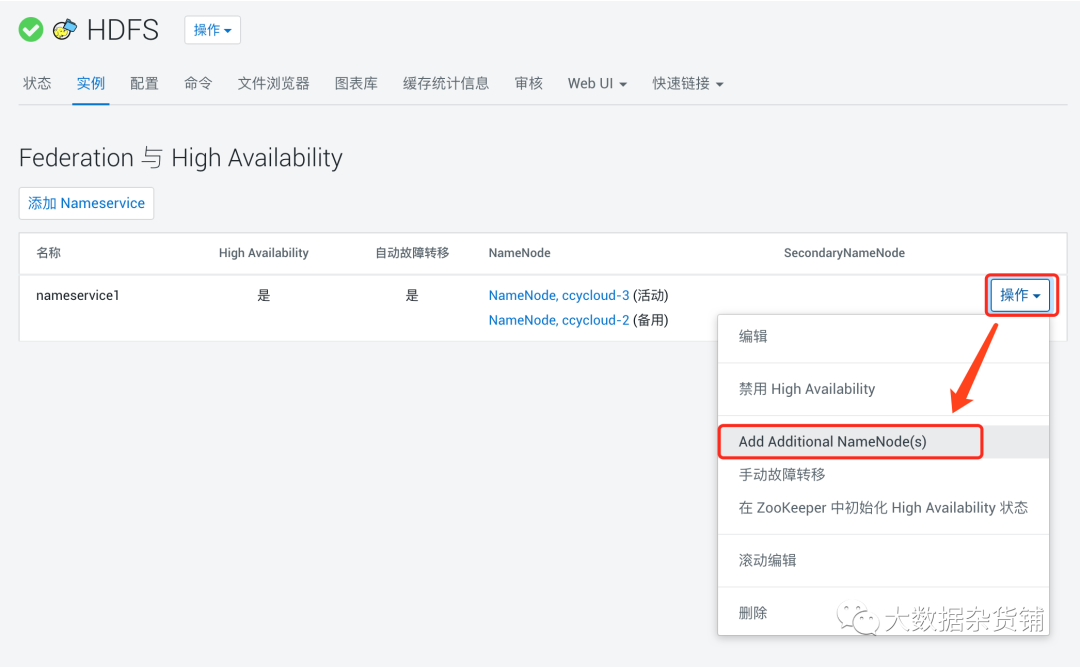
- 在“分配角色”页面中,选择未分配给任何名称节点的主机。
-
单击继续。
-
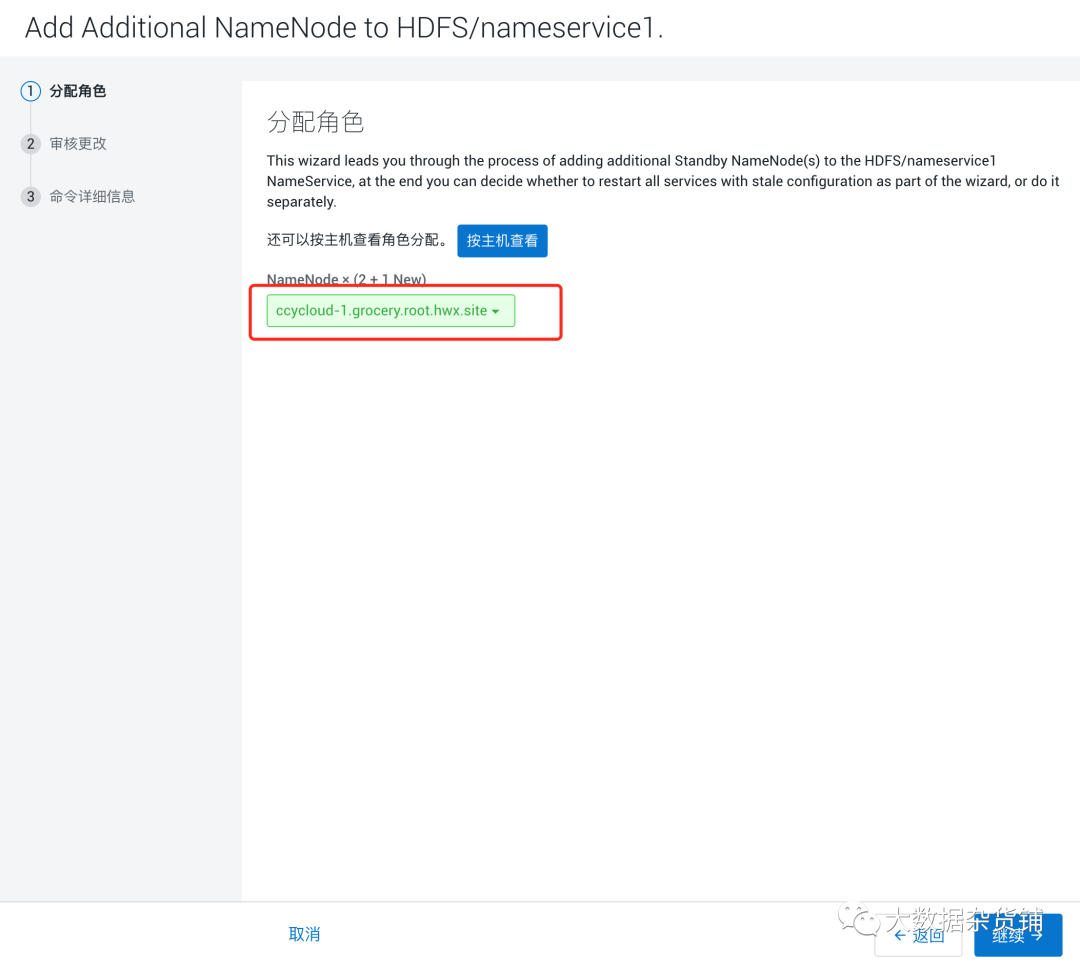
在Review Changes页面中,您可以指定 namenode 数据目录。
-
如果要删除已提供的名称节点数据目录中存在的数据,则必须选择清除备用名称节点名称目录中存在的任何现有数据选项。请记住备份名称节点数据目录。
-
如果要重启 HDFS 服务及其依赖项,则必须选择Rolling Restart HDFS and alldependent services 以激活更改选项。请记住,如果您没有启用高可用性功能,滚动重启可能会导致集群停机。注意:如果您未选择 Rolling Restart 选项,则可以单击 Continue 稍后重新启动集群。
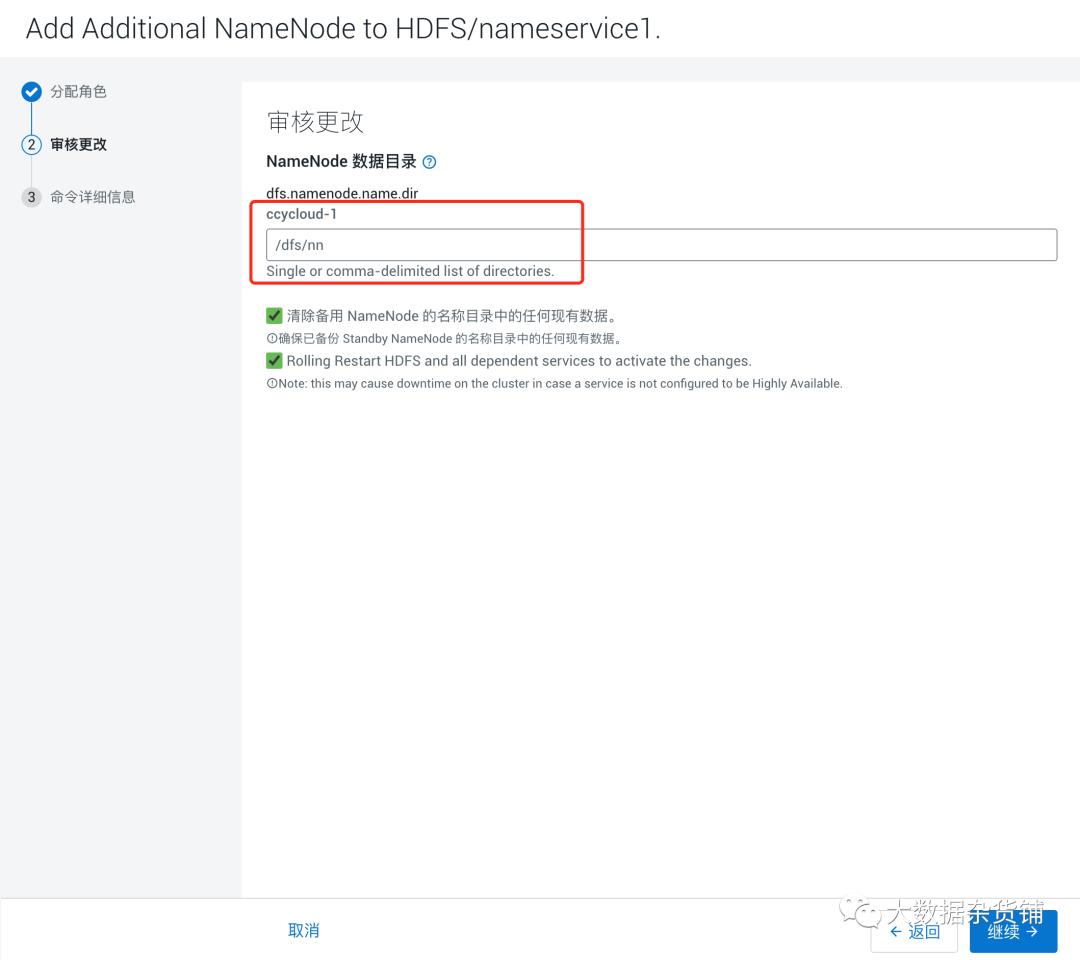
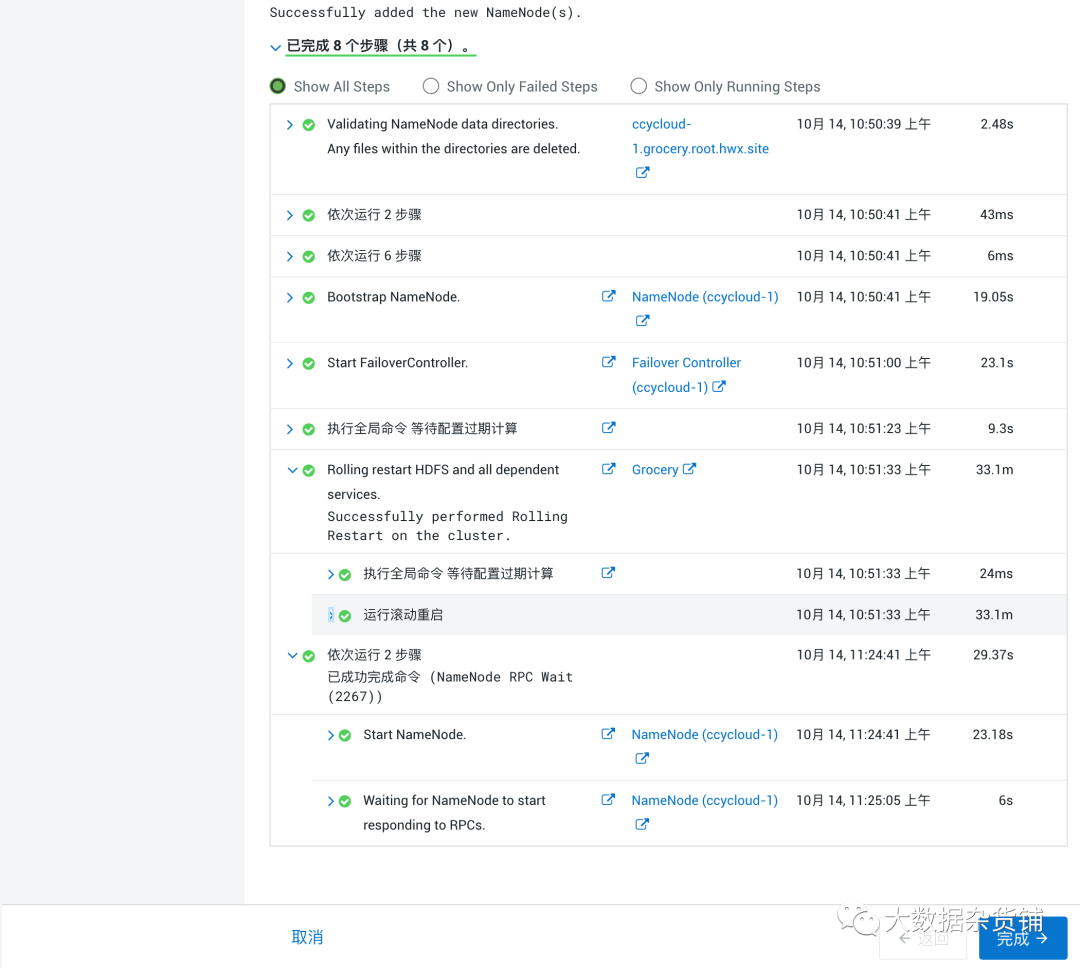
- 单击继续。这将运行所需的命令并添加额外的名称节点。
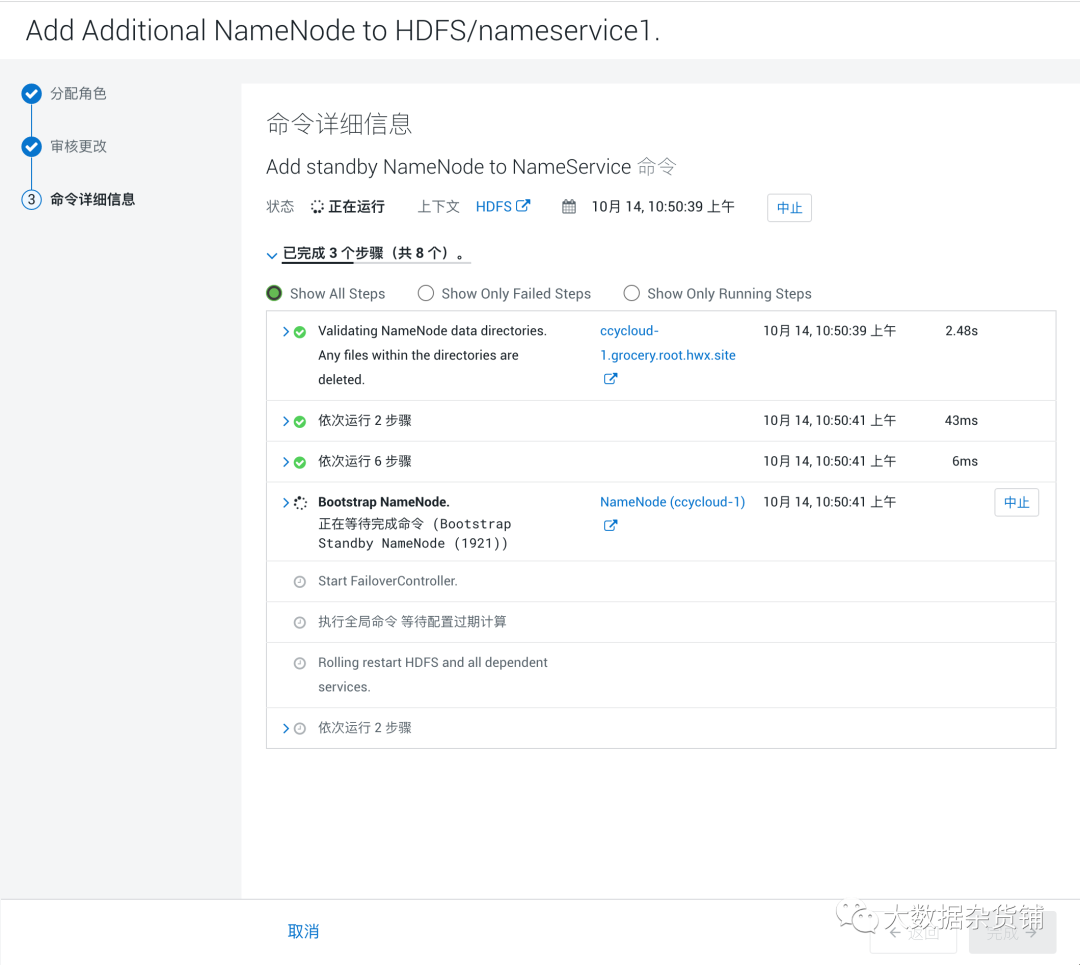
- 单击完成。
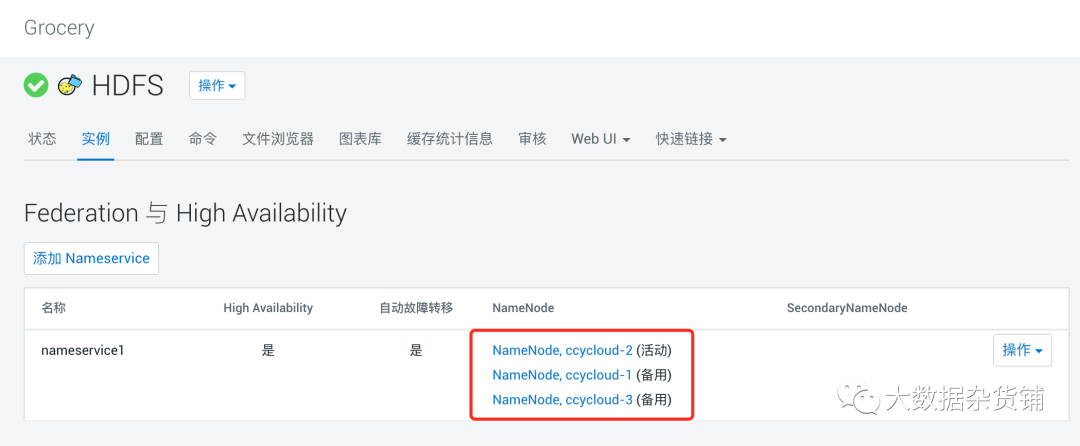
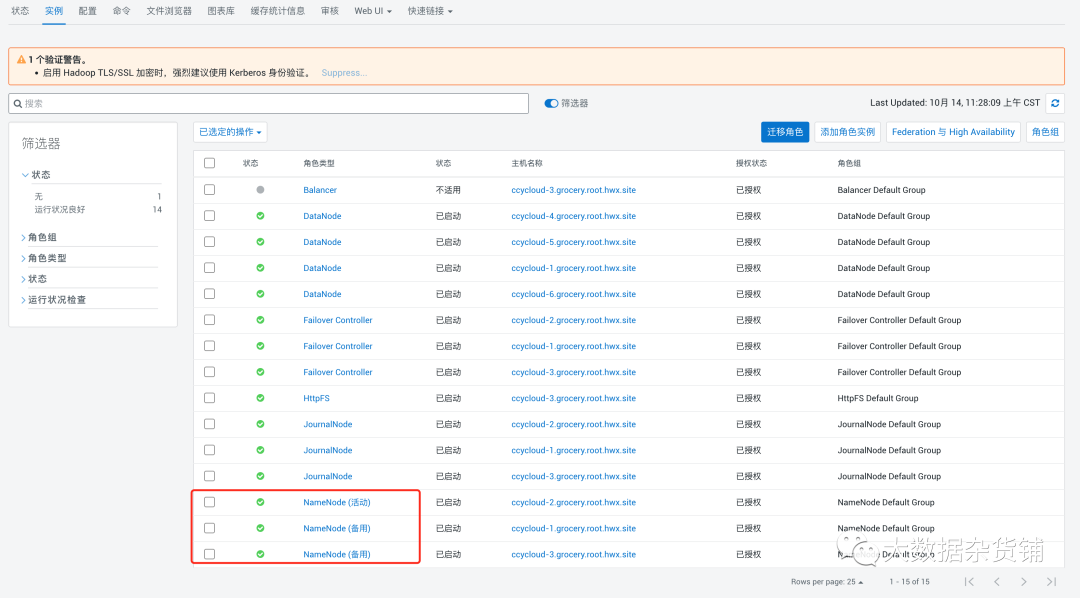
可以看到已经有三个NameNode, 其中一个是活动的,两个是备用的。

















 8666
8666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









