




目标
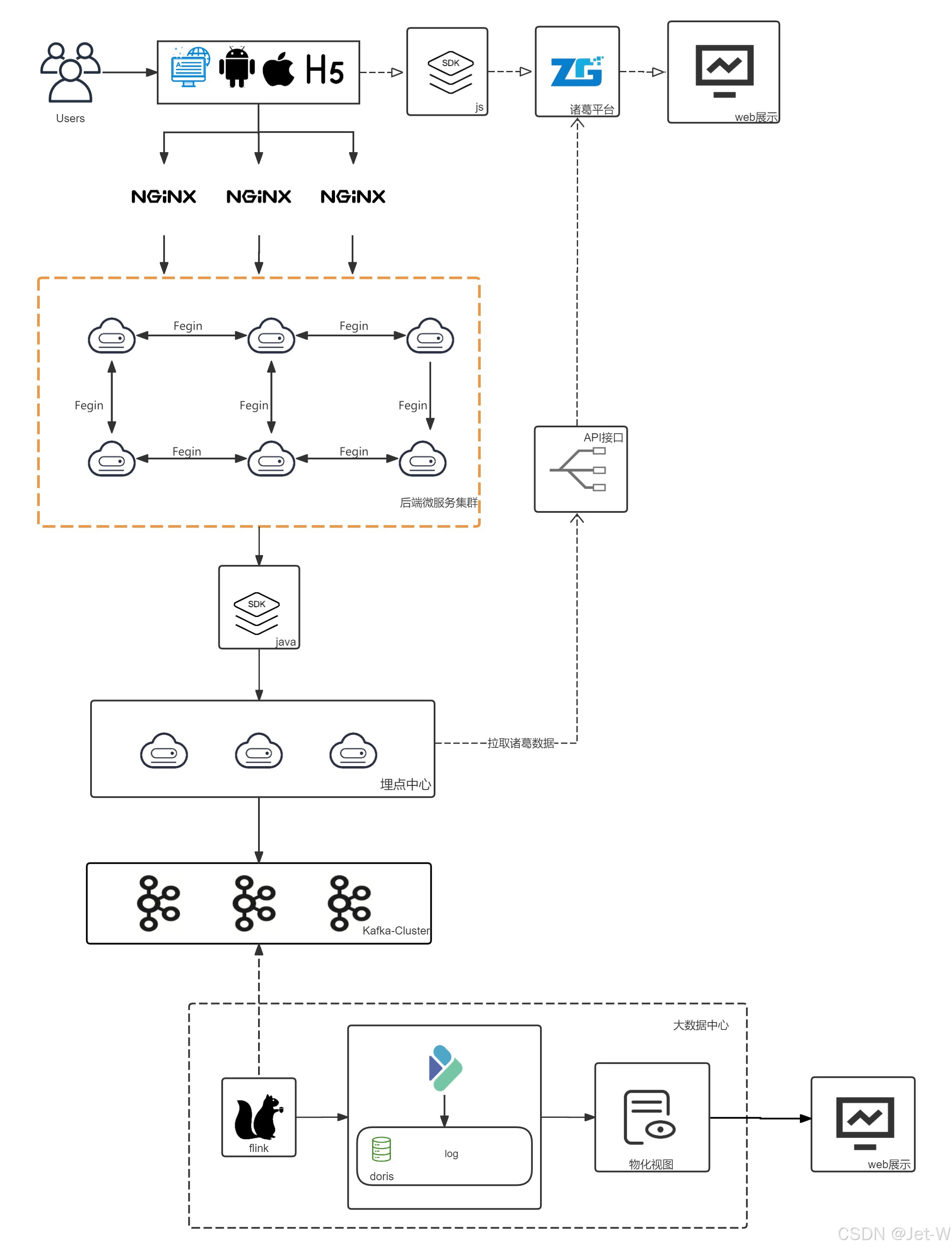
主要职责是收集用户操作行为数据,包括但不限于点击、搜索、筛选、跳转、登录、登出、接口调用、请求参数和调用链路等。这些数据的收集对于提供用户行为分析和报告至关重要,它们可以帮助业务功能设计提供有价值的参考信息。
现状:
1、没有区分出基础字段和可以业务自定义字段,每个业务线开发都有权限随意加字段,难以有效管理和控制,导致数据蔓延和膨胀,维护难度极大
2、用的是ES+MONGO架构,这样一个架构成本是比较高的,且这两个组件各自都有缺陷可能会无法满足未来的上十亿级别数据量的分析场景或者说是成本极高
3、目前ops(audit)项目经过不同人的多次迭代,数据存储流程和代码实现都比较混乱,需要重新梳理和设计
4、项目组各自写一套入库逻辑散落在各处,风格不统一且难以维护
升级后:
1、基础字段的新增更新都由基础架构组统一定义和审查,业务方只能在单个维度按照规范增加字段,有效控制数据蔓延和膨胀非风险
2、使用大数据中心做数据存储和分析,分析性能更好,维度更多,对于超大数据量的分析支持更好,成本也能得到很好的控制
3、埋点中心的项目由基础架构组重新梳理和搭建,未来项目也只有基础架构组来维护,可以有效的保证流程统一和项目质量
埋点流程图
埋点对象设计
升级目的:现状:没有区分出基础字段和可以业务自定义字段,每个开发都有权限随意加字段,难以有效管理和控制,会导致字段蔓延,字段膨胀,大幅提升了维护难度带来很大的困扰
埋点对象分为:公共基础字段、类型通用字段以及业务私有字段三层。
首先是全局公共字段,包括用户、来源、触发的时间戳、触发设备信息、ip等等。
第二个是针对不同的埋点类型,包括业务模块、动作、操作时间或者业务特色的业务内容埋点,抽象出这个类型通用字段去做一个具体的预填充。
第三个部分就是业务定制化的私有参数,比如商情的图表点击,需要这个图表的D,或者这个图表对应跳转公司的conpanyId等参数,就是业务它自定义去使用的参数信息。
升级前原对象
| 字段名 | 描述 | ||
|---|---|---|---|
| code | 业务模块 "mailsou-task" "bi-analysis" | ||
| id | mongoId | ||
| source | 来源 | ||
| actor | userId | 用户信息 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











