




 本文详细介绍了ConcurrentHashMap的使用方法实现,包括get、put、remove、size和containsValue等操作。get操作通过volatile保证获取最新值;put操作会初始化槽并考虑并发情况;remove操作需加锁保证线程安全;size和containsValue操作在多线程环境下可能需加锁,应尽量避免使用。
本文详细介绍了ConcurrentHashMap的使用方法实现,包括get、put、remove、size和containsValue等操作。get操作通过volatile保证获取最新值;put操作会初始化槽并考虑并发情况;remove操作需加锁保证线程安全;size和containsValue操作在多线程环境下可能需加锁,应尽量避免使用。
一、ConcurrentHashMap的使用方法实现
1、get操作
get操作先经过一次再散列,然后使用这个散列值通过散列运算定位到Segment(使用了散列值的高位部分),再通过散列算法定位到table(使用了散列值的全部)。整个get过程,没有加锁,而是通过volatile保证get总是可以拿到最新值。segment下的HashEntry数组用了transient字段修饰,不能被反序列化。
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);**//准备定位的hash**
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {**//拿到Segment下的tab值**
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {**//遍历tab下的HashEntry链表**
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
/**
* The per-segment table. Elements are accessed via
* entryAt/setEntryAt providing volatile semantics.
*/
transient volatile HashEntry<K,V>[] table;
2、put操作
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽,在插入第一个值的时候再进行初始化。
具体实现是:
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);**//准备定位的hash**
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);**//初始化segment,因为整个map初始化的时,只初始化segment[0]。**
return s.put(key, hash, value, false);
}
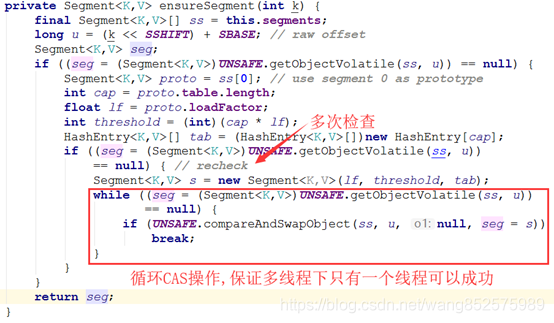
ensureSegment方法考虑了并发情况,多个线程同时进入初始化同一个槽 segment[k],但只要有一个成功就可以了。
具体实现是
put方法会通过tryLock()方法尝试获得锁,获得了锁,node为null进入try语句块,没有获得锁,调用scanAndLockForPut方法自旋等待获得锁。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);
V oldValue;
scanAndLockForPut方法里在尝试获得锁的过程中会对对应hashcode的链表进行遍历,如果遍历完毕仍然找不到与key相同的HashEntry节点,则为后续的put操作提前创建一个HashEntry。当tryLock一定次数后仍无法获得锁,则通过lock申请锁。
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
在获得锁之后,Segment对链表进行遍历,如果某个HashEntry节点具有相同的key,则更新该HashEntry的value值。否则新建一个HashEntry节点,采用头插法,将它设置为链表的新head节点并将原头节点设为新head的下一个节点。新建过程中如果节点总数(含新建的HashEntry)超过threshold,则调用rehash()方法对Segment进行扩容,最后将新建HashEntry写入到数组中。
源码实现:
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
3、remove操作
与put方法类似,都是在操作前需要拿到锁,以保证操作的线程安全性。
4、size、containsValue等操作
这些方法都是基于整个ConcurrentHashMap来进行操作的,他们的原理也基本类似:首先不加锁循环执行以下操作:循环所有的Segment,获得对应的值以及所有Segment的modcount之和。在 put、remove 和 clean 方法里操作元素前都会将变量 modCount 进行变动,如果连续两次所有Segment的modcount和相等,则过程中没有发生其他线程修改ConcurrentHashMap的情况,返回获得的值。
当循环次数超过预定义的值时,这时需要对所有的Segment依次进行加锁,获取返回值后再依次解锁。所以一般来说,应该避免在多线程环境下使用size和containsValue方法。

















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









