




 本文介绍了javax.sql.DataSource作为数据库连接工厂接口的重要性,对比了传统的DriverManager。讨论了Spring框架中常用的DataSource实现,如Hikari和Druid,以及动态路由数据源AbstractRoutingDataSource。文章还提出了静态和动态多数据源配置的策略。
本文介绍了javax.sql.DataSource作为数据库连接工厂接口的重要性,对比了传统的DriverManager。讨论了Spring框架中常用的DataSource实现,如Hikari和Druid,以及动态路由数据源AbstractRoutingDataSource。文章还提出了静态和动态多数据源配置的策略。
javax.sql.DataSource
javax.sql.DataSource 是 jdk 提供的接口,各个连接池厂商 和 Spring 都对 DataSource 进行了设计和实现。
javax.sql.DataSource 是连接到物理数据源的工厂接口。它是 java.sql.DriverManager 功能的替代者,是获取数据库连接的首选方法。
DataSource 数据源在必要时可以修改它的属性。例如,如果将数据源移动到其他服务器,则可以更改 DataSource 的属性,这样访问该数据源的代码不需要做任何更改就可以获取到达到目的。
有些 DataSource 的连接池实现还可以支持部分属性在程序运行期间进行修改。
最原始的获取 DB 连接的方法是使用
java.sql.DriverManager#getConnection()来获取连接。
现在都推荐使用javax.sql.DataSource#getConnection()来获取连接。
Spring 对 DataSource 的封装
类图如下:
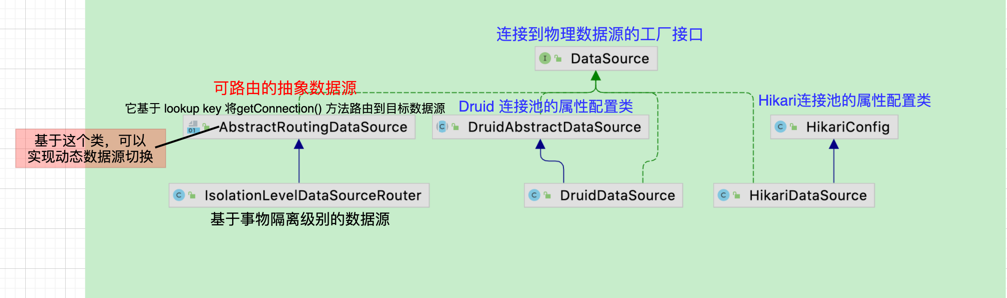
图中列出了 DataSource 的三个典型的实现类: HikariDataSource、DruidDataSource 和 AbstractRoutingDataSource
HikariDataSource
HikariDataSource 是 SpringBoot 默认使用的连接池,而且代码量是很少的。
连接池相关的配置参数是放在父类 HikariConfig 中的。
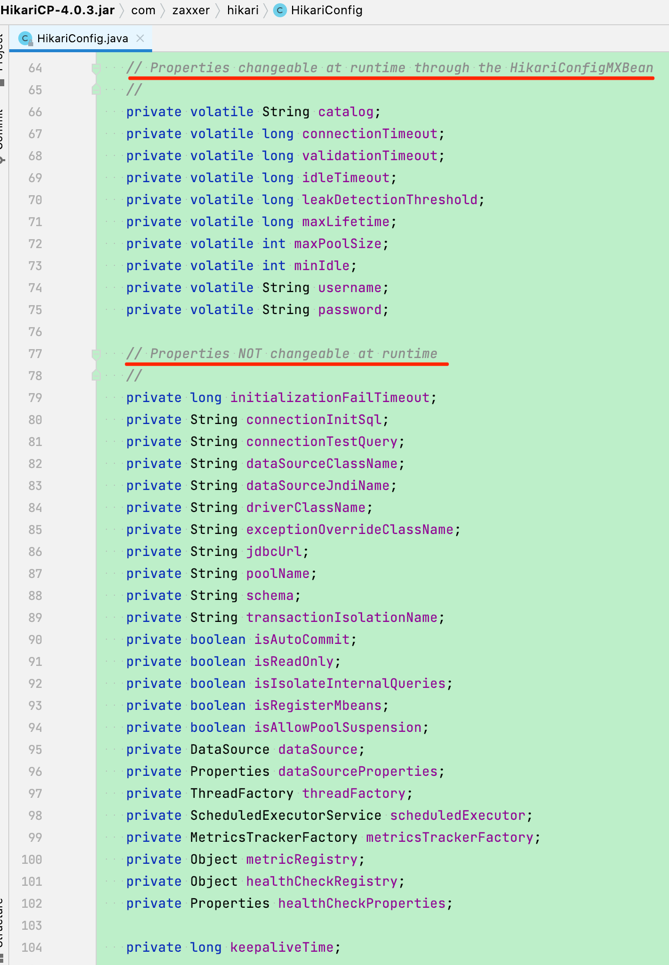
Hikari 连接池的参数分成了两类:一类是可以在运行期间动态修改的;一类是在运行期间不可修改的。
配置项的说明可以参考:
https://github.com/brettwooldridge/HikariCP
https://pdai.tech/md/spring/springboot/springboot-x-mysql-HikariCP.html
关于 connectionTestQuery 参数
connectionTestQuery 参数的作用是:
在一个连接从连接池中拿出来之前,会优先执行 connectionTestQuery 指定的查询语句,从而验证这个连接是存活且有效的。
如果驱动程序支持 JDBC4,那么强烈建议不要设置此属性。
connectionTestQuery 参数是针对不支持 JDBC4 的 Connection#isValid() API 接口的“传统”驱动程序的。
如果没有设置 connectionTestQuery,且驱动程序不支持 JDBC4,那么 HikariCP 将记录一个错误。
DruidDataSource
Druid 连接池是阿里巴巴开源的数据库连接池。Druid 连接池是以监控为主的连接池。
Druid 的配置参数有很多,大致分为了三类:JDBC配置;连接池配置;监控配置。

配置说明可以参考:
https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
https://pdai.tech/md/spring/springboot/springboot-x-mysql-druid.html
https://github.com/alibaba/druid/wiki/DruidDataSource配置属性列表
AbstractRoutingDataSource
AbstractRoutingDataSource 是 Spring 对 DataSource 的抽象实现。它是一个基于 lookup key ,将 DataSource#getConnection() 的调用路由到目标数据源的抽象数据源实现。
通常都是通过 ThreadLocal 绑定的事务上下文变量来确定路由到哪个目标数据源。
IsolationLevelDataSourceRouter 是 AbstractRoutingDataSource 的实现类,它是一个能基于当前事务隔离级别路由到目标数据源的 DataSource 数据源。
举一反三:多数据源配置的思考
结合前面对 多事物管理器和多数据源处理 的分析,以及上面对 AbstractRoutingDataSource 特性的讲解,我们可以发现,多数据源的切换可以通过两种方式来实现:
1、静态多数据源的方式来配置
- 首先,配置多个 DataSource
- 然后,配置多个 SqlSessionFactory。
当然,这些 SqlSessionFactory 都是基于上面的 DataSource 来配置的,这样就可以通过 MyBatis 的 Mapper 接口来组装 sql 操作 DB 了。
很显然,这种方式比较适合异构的数据源,即每个数据源中的表都是不一样的,这样定义出来的 MyBatis 的 Mapper 接口也不一样。
那如果是分库分表的数据源(或者主从结构的数据源),这类数据源中的表的结构都是一样的,如果也使用这种静态多数据源的方式来配置的话,就需要定义多个一模一样的 Mapper 接口,这样就会显得冗余且不太优雅。
2、动态多数据源切换的方式
基于 AbstractRoutingDataSource 来进行数据源的切换。
动态数据源的切换可以通过自定义注解的方式,对方法打标记来实现,这里对具体的实现方式不做展开
很显然,这种方式就比较适合分库分表的数据源(或者主从结构的数据源),定义一套 MyBatis 的 Mapper 接口就可以操作多个数据源了。
小结
javax.sql.DataSource 是连接到物理数据源的工厂接口。它是 java.sql.DriverManager 功能的替代者,是获取数据库连接的首选方法。
DataSource 三个典型的实现类: HikariDataSource、DruidDataSource 和 AbstractRoutingDataSource
- HikariDataSource: SpringBoot 默认使用的数据源实现
- DruidDataSource: 阿里 Druid 连接池使用的数据源实现
- AbstractRoutingDataSource: Spring 抽象出来的可动态路由的数据源实现



















 4093
4093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











