




 本文深入探讨逻辑回归的基本理论,包括Sigmoid函数、分类概率表示、梯度上升算法,以及如何用Python3实现逻辑回归算法。通过实例展示了如何在数据集上应用逻辑回归,解释了学习曲线和决策边界的绘制。
本文深入探讨逻辑回归的基本理论,包括Sigmoid函数、分类概率表示、梯度上升算法,以及如何用Python3实现逻辑回归算法。通过实例展示了如何在数据集上应用逻辑回归,解释了学习曲线和决策边界的绘制。
文中的代码和数据集下载地址:
https://github.com/TimePickerWang/MachineLearningInAction
一、基本理论
逻辑回归是一个二值型的分类器,它是利用Sigmoid函数来进行分类的,Sigmoid函数的表达式如下:
g(z)=11+e−z g ( z ) = 1 1 + e − z
其函数图像如下图:
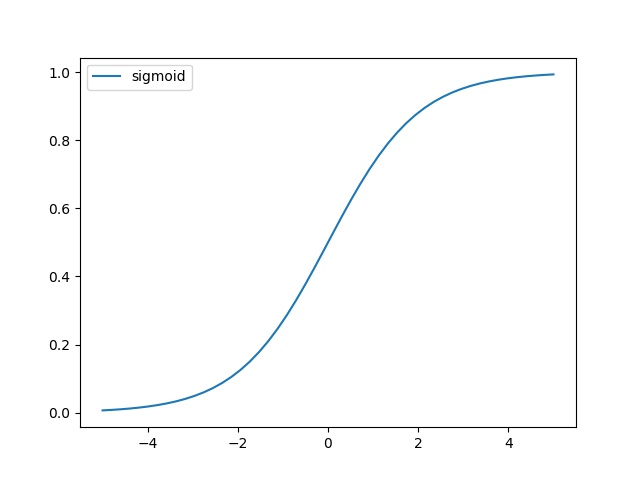
结合表达式可以知道:
当z=0时,g(z)=0.5 当 z = 0 时 , g ( z ) = 0.5
当z>0时,g(z)>0.5 当 z > 0 时 , g ( z ) > 0.5 ,且随着z的增大,g(z)会越来越接近1
当z<0时,g(z)<0.5 当 z < 0 时 , g ( z ) < 0.5 ,且随着z的减小,g(z)会越来越接近0
利用这一特性,我们可以进行这样一种分类方式:
当输入 z>0.5 z > 0.5 时,把样本分为1类
当输入 z<0.5 z < 0.5 时,把样本分为0类
那么 z z 具体是什么呢?假设每一个样本有n个特征:{
},则:
其中, x0=1 x 0 = 1 是一个常数,表示一个偏差量。 w0,w1,w2,...wn w 0 , w 1 , w 2 , . . . w n 可以理解为每一个特征的权重,我们的目的就是寻求一组 w0,w1,w2,...wn w 0 , w 1 , w 2 , . . . w n ,使得分类正确的概率尽可能的大。
那么问题来了,怎么表示分类正确的概率呢?假设有一个样本 i i ,其类标签是
,则可以利用上面提到的“ g(z) g ( z ) ”表示样本 i i 为类1的概率,由于Sigmoid的值域为(0,1),所以可以令”
”表示样本为类0的概率。则样本 i i 分类正确的概率可以表示如下:
上式中,当 y=1 y = 1 时, p=g(z) p = g ( z ) ;当 y=0 y = 0 时, p=1−g(z) p = 1 − g ( z ) 。所以无论样本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4447
4447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









