




 本文档详细介绍了如何使用OptaPlanner进行基准测试和调优,包括寻找最佳求解器配置、配置和运行基准测试、编写基准测试报告、统计和解析基准测试结果。内容涵盖解决方案文件的输入输出、预热编译器、基准测试蓝图、求解器排名、统计摘要等多个方面,旨在帮助用户优化算法性能。
本文档详细介绍了如何使用OptaPlanner进行基准测试和调优,包括寻找最佳求解器配置、配置和运行基准测试、编写基准测试报告、统计和解析基准测试结果。内容涵盖解决方案文件的输入输出、预热编译器、基准测试蓝图、求解器排名、统计摘要等多个方面,旨在帮助用户优化算法性能。
【教程14】OptaPlanner基准测试和调优
文章目录
- 【教程14】OptaPlanner基准测试和调优
- 1. 查找最佳求解器配置
- 2. 基准测试配置
- 3. 基准测试报告
- 4. 摘要统计数据
- 5. 数据集统计(图表和CSV)
- 6. 单个基准测试统计(图表和CSV)
- 高级基准测试
- 7.1. 基准测试性能技巧
- 7.2. 统计基准测试
- 7.3. 基于模板的基准测试和矩阵基准测试
- 7.4. 基准测试报告聚合
- 参考链接
1. 查找最佳求解器配置
OptaPlanner支持多种优化算法,所以您可能想知道哪个是最好的?虽然一些优化算法通常比其他算法表现更好,但实际上取决于您的问题领域。大多数求解器阶段都有可以调整的参数。这些参数可以很大程度上影响结果,尽管大多数求解器阶段在开箱即用时表现良好。
幸运的是,OptaPlanner包含了一个基准测试工具,它允许您在开发中使用不同的求解器阶段和设置相互对比,以便在生产环境中使用最佳的配置来解决规划问题。
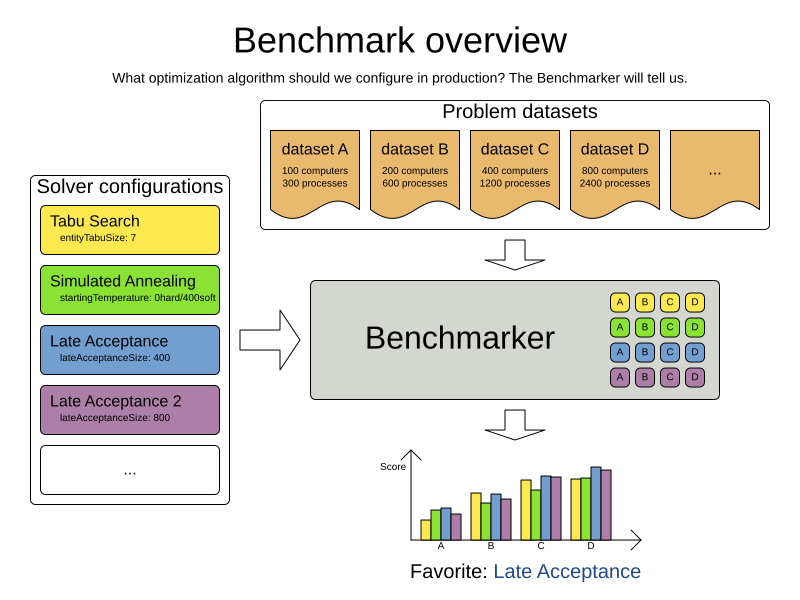
2. 基准测试配置
2.1. 添加optaplanner-benchmark依赖
基准测试工具位于名为optaplanner-benchmark的独立库中。
如果您使用Maven,请在pom.xml文件中添加以下依赖项:
<dependency>
<groupId>org.optaplanner</groupId>
<artifactId>optaplanner-benchmark</artifactId>
</dependency>
Gradle、Ivy和Buildr等构建工具也类似。版本必须与使用的optaplanner-core版本完全相同(如果导入了optaplanner-bom,则会自动匹配)。
如果您使用ANT,则可能已经从下载zip文件的binaries目录中复制了所需的jar包。
2.2. 运行简单基准测试
为了快速设置一个基准测试,可以根据求解器配置XML文件创建一个PlannerBenchmarkFactory,并加载一些数据集进行基准测试。例如,有3个数据集:
PlannerBenchmarkFactory benchmarkFactory = PlannerBenchmarkFactory.createFromSolverConfigXmlResource(
"org/optaplanner/examples/cloudbalancing/solver/cloudBalancingSolverConfig.xml");
CloudBalance dataset1 = ...;
CloudBalance dataset2 = ...;
CloudBalance dataset3 = ...;
PlannerBenchmark benchmark = benchmarkFactory.buildPlannerBenchmark(
dataset1, dataset2, dataset3);
benchmark.benchmarkAndShowReportInBrowser();
这将在local/benchmarkReport目录下生成一个基准测试报告,并在完成时在浏览器中显示出来。SolverFactory的求解器配置需要一个终止条件来限制每个数据集运行的时间。要配置不同的基准测试目录,将一个File参数传递给createFromSolverConfigXmlResource()方法。
生成的基准测试报告已经包含了有趣的信息,但它并没有比较求解器配置以找到最佳算法。要做到这一点,需要设置一个显式的基准测试配置。
2.3. 配置和运行高级基准测试
使用PlannerBenchmarkFactory构建一个PlannerBenchmark实例。使用基准测试配置XML文件来配置它,该文件作为类路径资源提供:
PlannerBenchmarkFactory benchmarkFactory = PlannerBenchmarkFactory.createFromXmlResource(
"org/optaplanner/examples/cloudbalancing/benchmark/cloudBalancingBenchmarkConfig.xml");
PlannerBenchmark benchmark = benchmarkFactory.buildPlannerBenchmark();
benchmark.benchmarkAndShowReportInBrowser();
也可以通过编程方式从PlannerBenchmarkConfig创建一个PlannerBenchmarkFactory。
基准测试配置XML文件的结构如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<plannerBenchmark xmlns="https://www.optaplanner.org/xsd/benchmark" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.optaplanner.org/xsd/benchmark https://www.optaplanner.org/xsd/benchmark/benchmark.xsd">
<benchmarkDirectory>local/data/nqueens</benchmarkDirectory>
<inheritedSolverBenchmark>
<solver>
...<!-- 公共求解器配置 -->
</solver>
<problemBenchmarks>
...
<inputSolutionFile>data/cloudbalancing/unsolved/100computers-300processes.json</inputSolutionFile>
<inputSolutionFile>data/cloudbalancing/unsolved/200computers-600processes.json</inputSolutionFile>
</problemBenchmarks>
</inheritedSolverBenchmark>
<solverBenchmark>
<name>Tabu Search</name>
<solver>
...<!-- Tabu Search特定的求解器配置 -->
</solver>
</solverBenchmark>
<solverBenchmark>
<name>Simulated Annealing</name>
<solver>
...<!-- Simulated Annealing特定的求解器配置 -->
</solver>
</solverBenchmark>
<solverBenchmark>
<name>Late Acceptance</name>
<solver>
...<!-- Late Acceptance特定的求解器配置 -->
</solver>
</solverBenchmark>
</plannerBenchmark>
这个PlannerBenchmark尝试在两个数据集(100computers-300processes和200computers-600processes)上运行三种配置(Tabu Search、Simulated Annealing和Late Acceptance),因此它运行了六个求解器。
每个元素都包含一个求解器配置和一个或多个元素。它会在每个未解决的解决方案文件上运行求解器配置。如果缺少element name,将自动生成它。inputSolutionFile是相对于工作目录的SolutionFileIO读取的。
请使用斜杠(/)作为文件分隔符(例如在元素中)。这样可以在任何平台上正常工作(包括Windows)。
不要使用反斜杠()作为文件分隔符:这会破坏可移植性,因为Linux和Mac上无法正常工作。
基准测试报告将写入由元素指定的目录中(相对于工作目录)。
建议将benchmarkDirectory设置为一个在源代码控制中被忽略并且不会被构建系统清理的目录。这样生成的文件就不会使您的源代码库变得臃肿,并且在进行干净构建时不会丢失这些文件。例如,在git中,应将其添加到.gitignore中。通常该目录被称为local。
如果单个基准测试发生异常或错误,则整个Benchmarker不会立即失败(与OptaPlanner中的其他所有内容不同)。相反,Benchmarker会继续运行所有其他基准测试,编写基准测试报告,然后在至少一个基准测试失败时才失败。失败的基准测试在基准测试报告中明确标记。
2.3.1. 继承的求解器基准测试
为了降低冗余性,多个元素的公共部分被提取到元素中。每个元素仍然可以覆盖每个属性。请注意,继承的求解器阶段(如或)不会被覆盖,而是添加到求解器阶段列表的末尾。
2.4. SolutionFileIO:输入和输出解决方案文件
2.4.1. SolutionFileIO接口
基准测试工具需要能够读取输入文件以加载问题。此外,它还可以将每个基准测试的最佳解决方案可选地写入输出文件。它通过SolutionFileIO接口来实现读取和写入方法:
public interface SolutionFileIO<Solution_> {
...
Solution_ read(File inputSolutionFile);
void write(Solution_ solution, File outputSolutionFile);
}
SolutionFileIO接口在optaplanner-persistence-common库中(这是optaplanner-benchmark库的依赖项)中。有几种方法可以对解决方案进行序列化。
2.4.2. JacksonSolutionFileIO:序列化为JSON格式
通过扩展JacksonSolutionFileIO,可以使用JSON格式读取和写入解决方案:
public class NQueensJsonSolutionFileIO extends JacksonSolutionFileIO<NQueens> {
public NQueensJsonSolutionFileIO() {
// NQueens是@PlanningSolution类。
super(NQueens.class);
}
}
如果JSON文件需要启用/禁用特定的Jackson模块和功能,可以创建所需的对象映射器作为JacksonSolutionFileIO的依赖项:
public class NQueensJsonSolutionFileIO extends JacksonSolutionFileIO<NQueens> {
public NQueensJsonSolutionFileIO() {
// NQueens是@PlanningSolution类。
super(NQueens.class,
new ObjectMapper()
.registerModule(new JavaTimeModule())
.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS)
);
}
}
然后在基准测试配置中使用它:
<problemBenchmarks>
<solutionFileIOClass>org.optaplanner.examples.nqueens.persistence.NQueensJsonSolutionFileIO</solutionFileIOClas 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











