



 本文详细讨论了MySQL数据库中的慢查询解决方案、SQL执行计划分析、索引(如B+树、聚簇索引和覆盖索引)的重要性,以及事务特性、并发问题和隔离级别,还包括主从同步原理和分库分表策略。
本文详细讨论了MySQL数据库中的慢查询解决方案、SQL执行计划分析、索引(如B+树、聚簇索引和覆盖索引)的重要性,以及事务特性、并发问题和隔离级别,还包括主从同步原理和分库分表策略。
1、定位慢查询

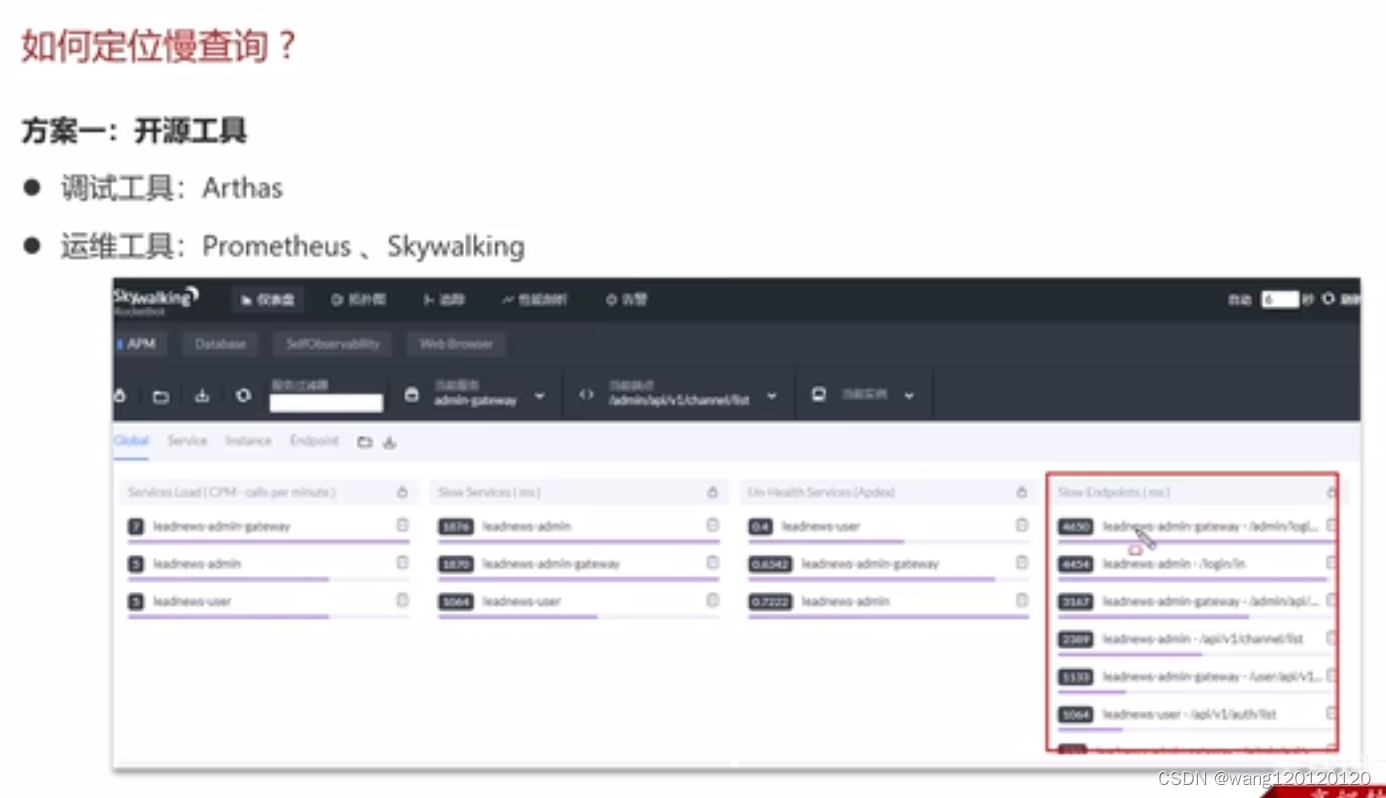
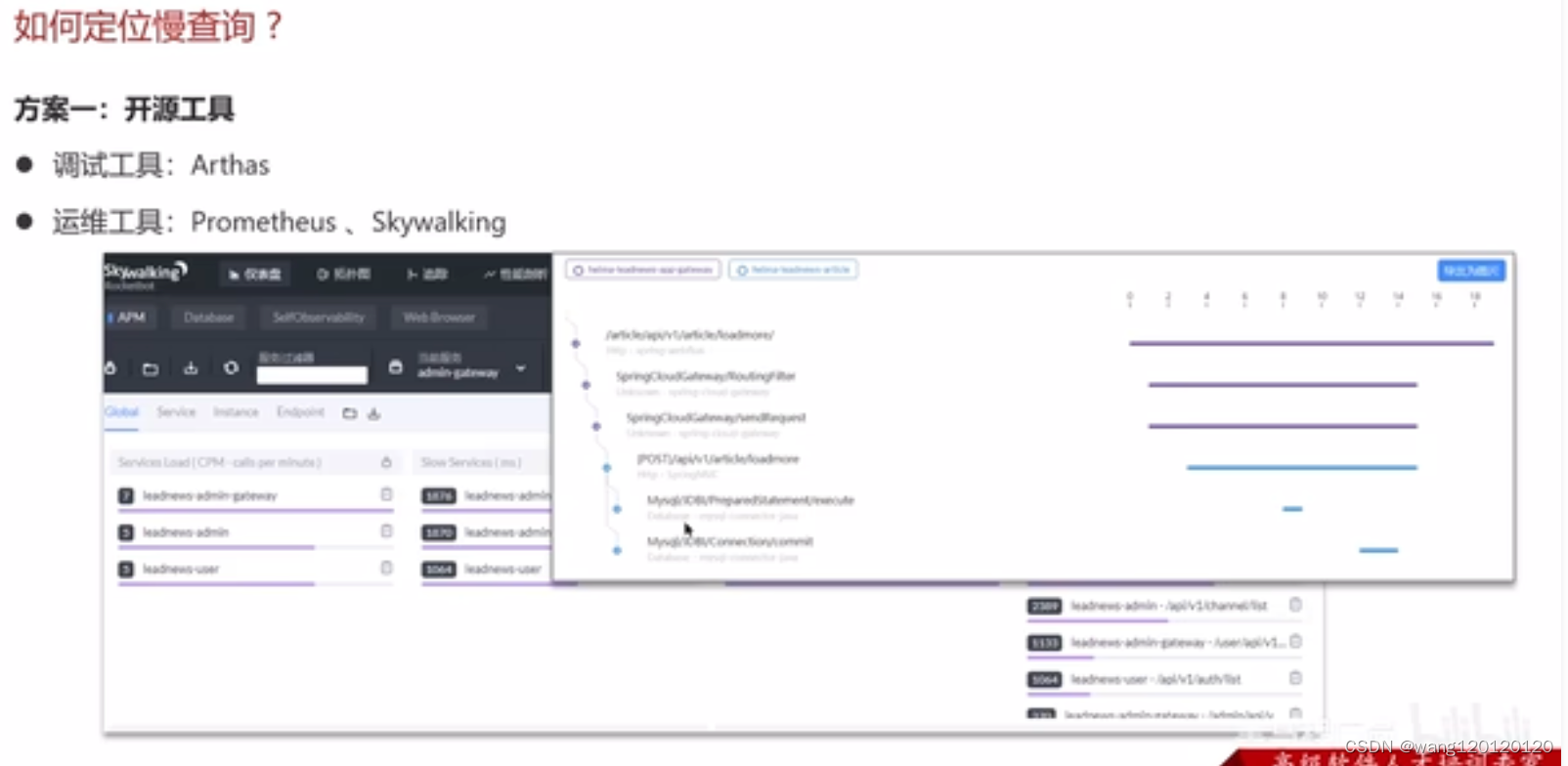
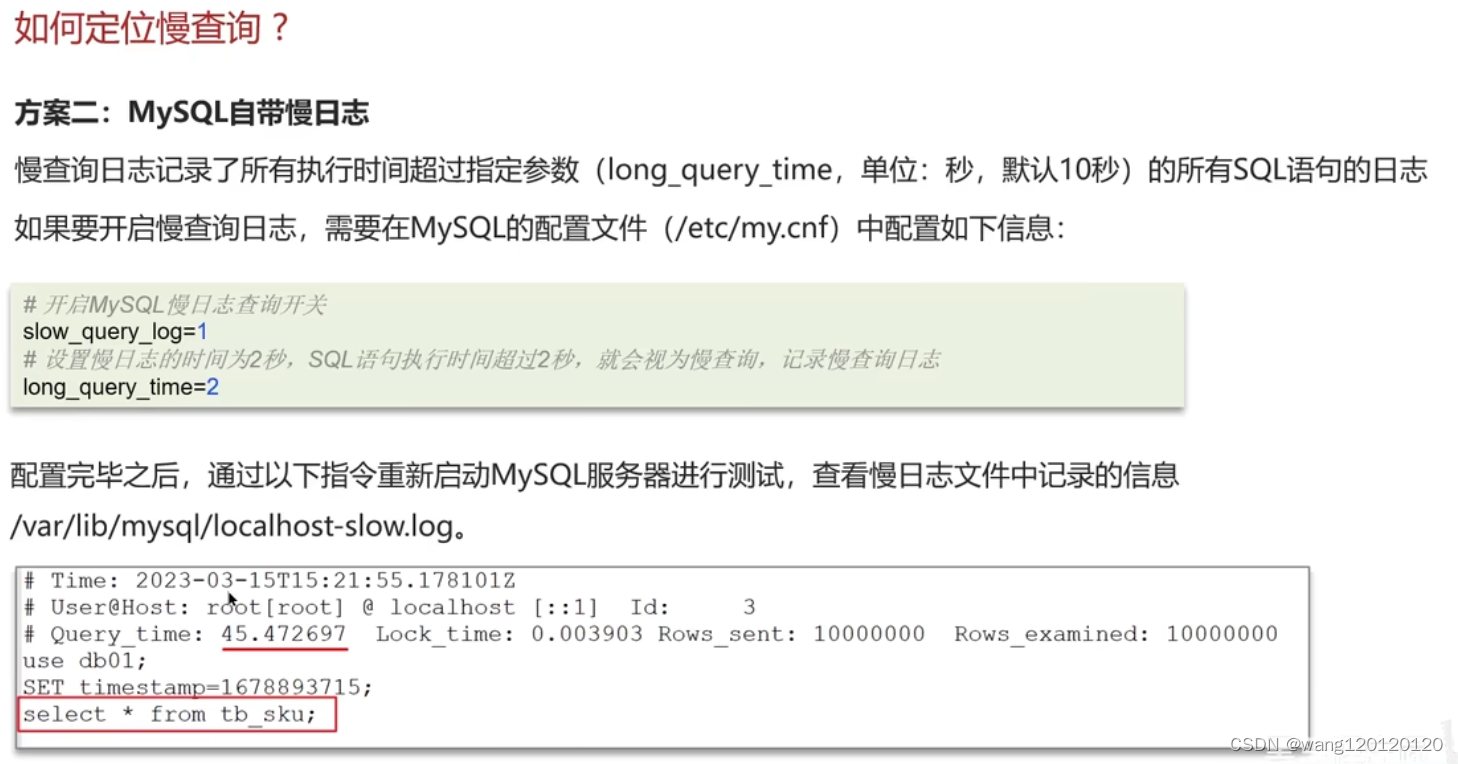
方案二:mysql自带慢日志


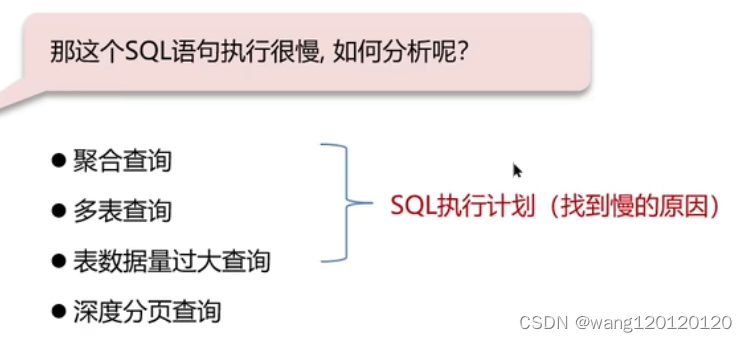
2、sql执行很慢,如何分析 SQL执行计划
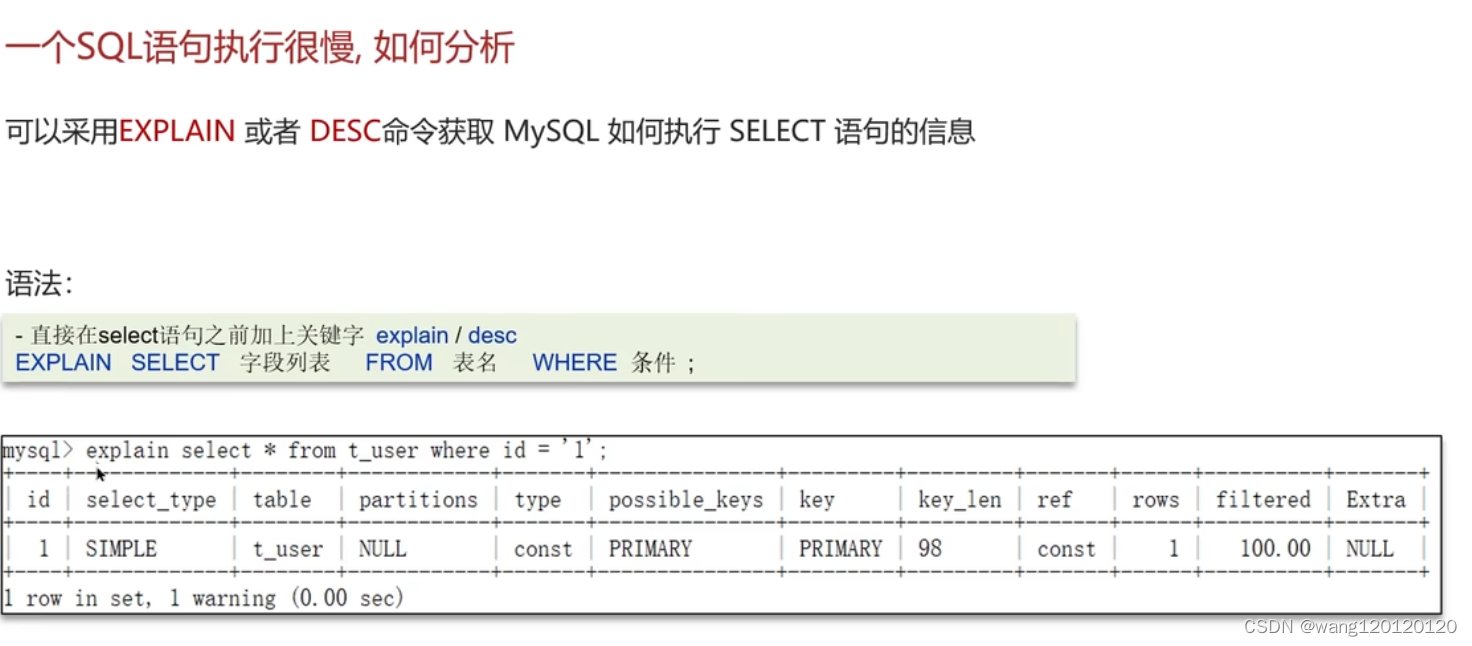
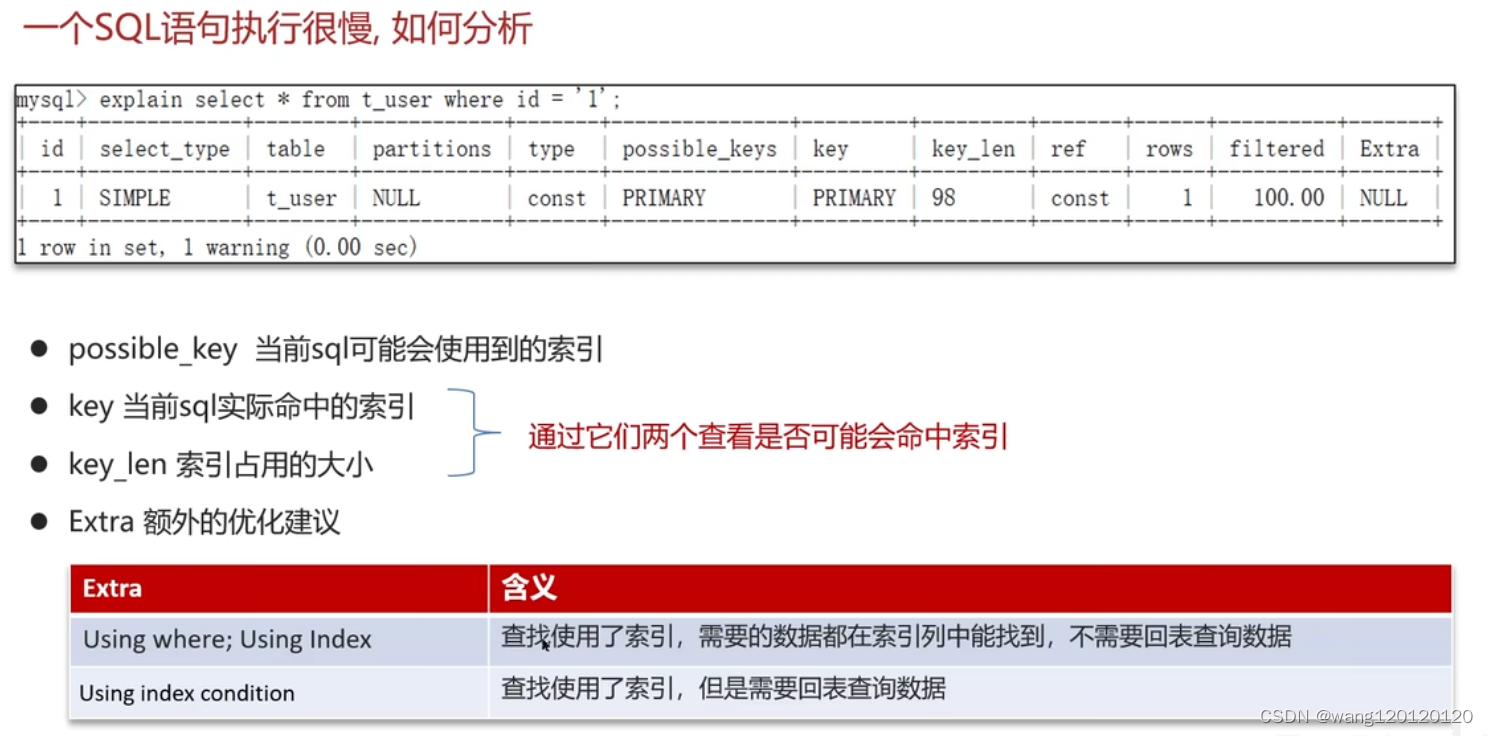
NULL:这条sql执行的时候没有使用到表


3、索引&底层数据结构
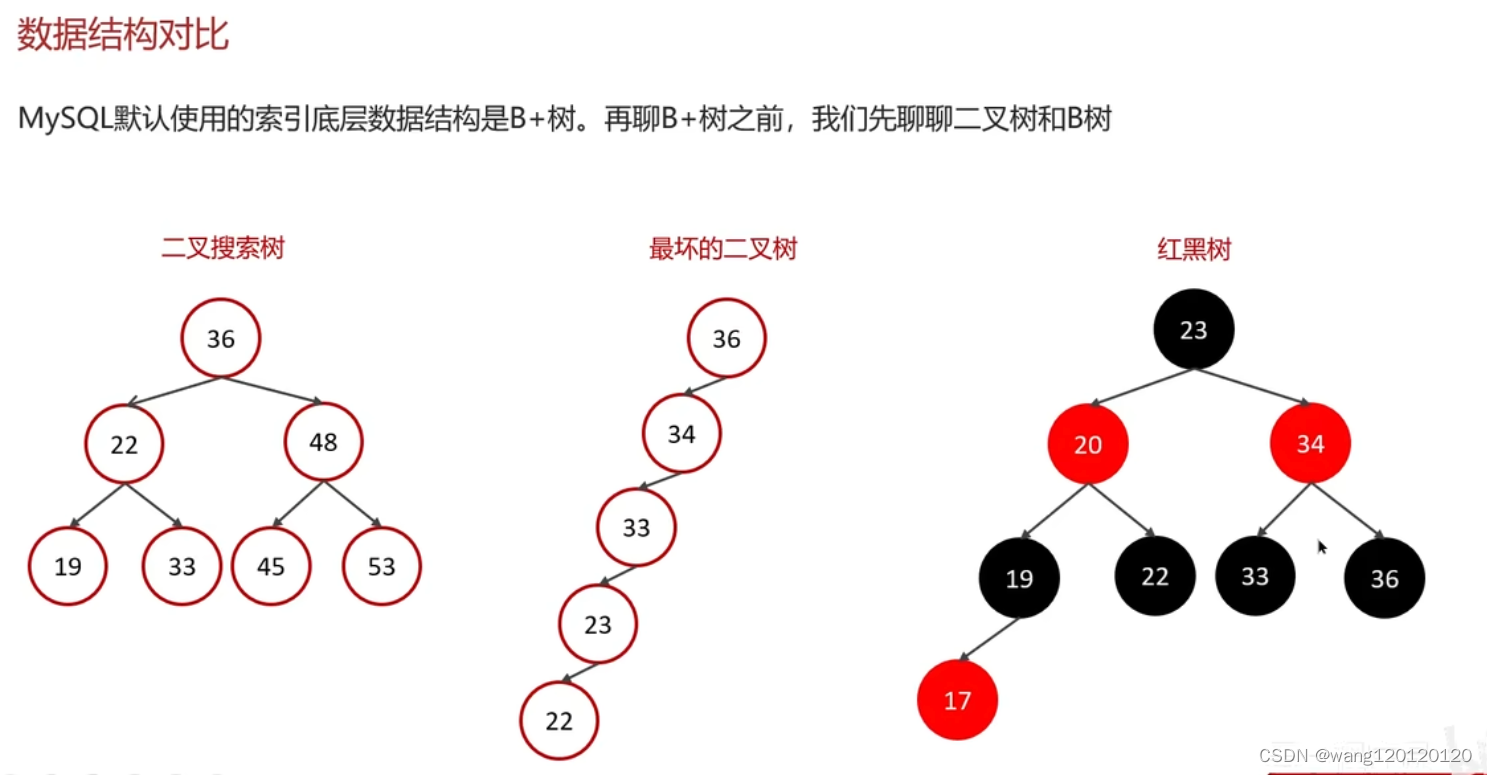
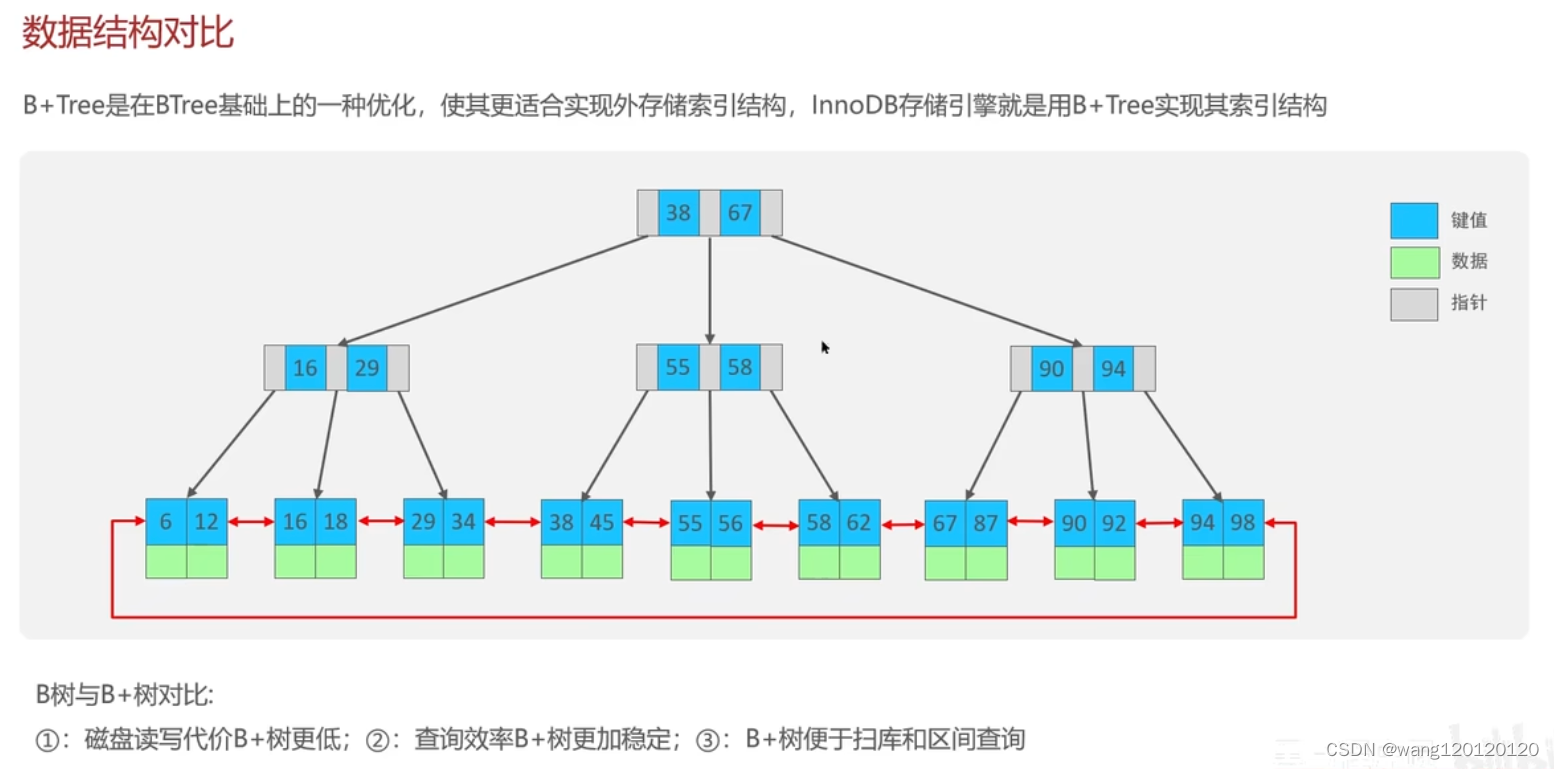
为什么使用B+树
二叉树,红黑树都是二叉的,效率都不高
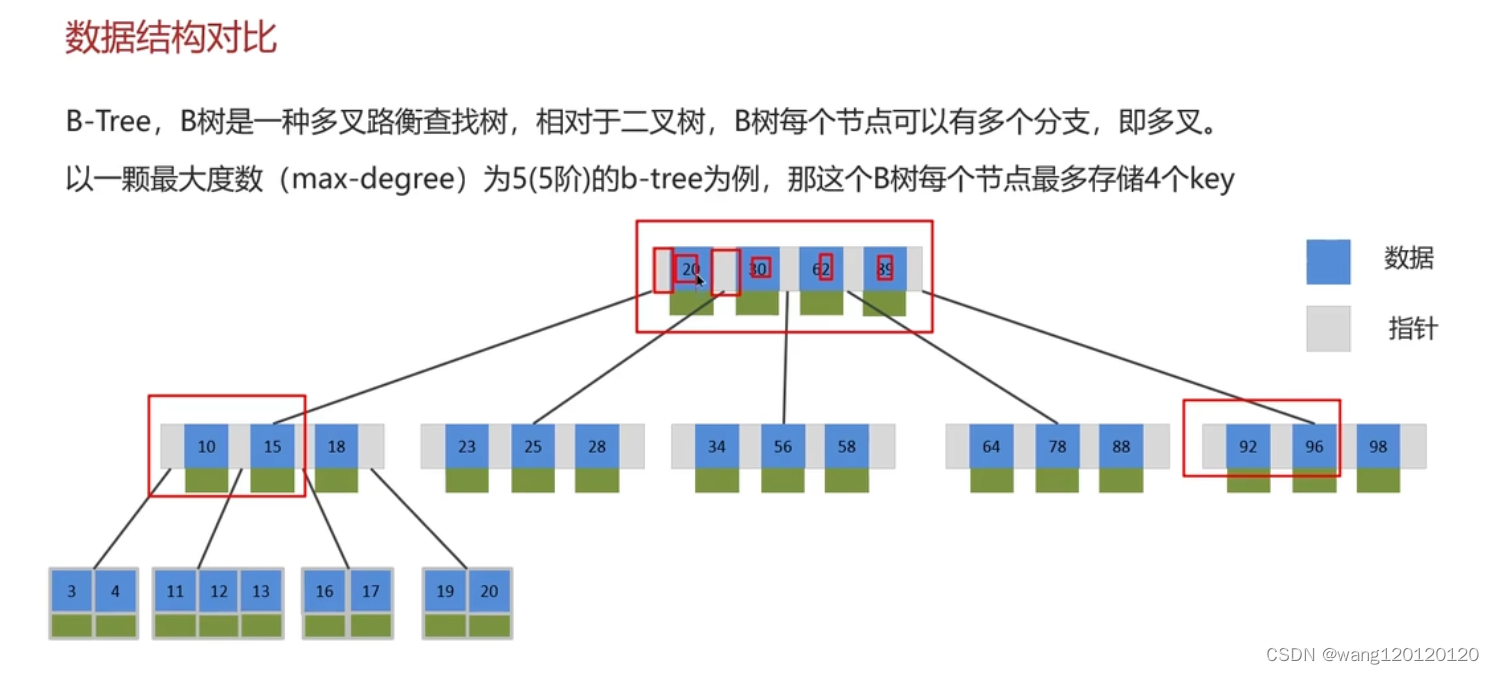
B树 也就是 B-树
灰色的是指针,蓝色的是数据 绿色部分就是索引对应的数据
也就是非叶子节点也存储数字
B+树
1、因为非叶子节点不存数据,所以不用把数据取出来,而B-树在非叶子节点有数据,需要进行数据的比较,需要读数据,所以磁盘读写代价要高些
2、B+树,多次查询都是差不多的查找路径
3、叶子节点都是通过双向指针连接的,更适合区间查询


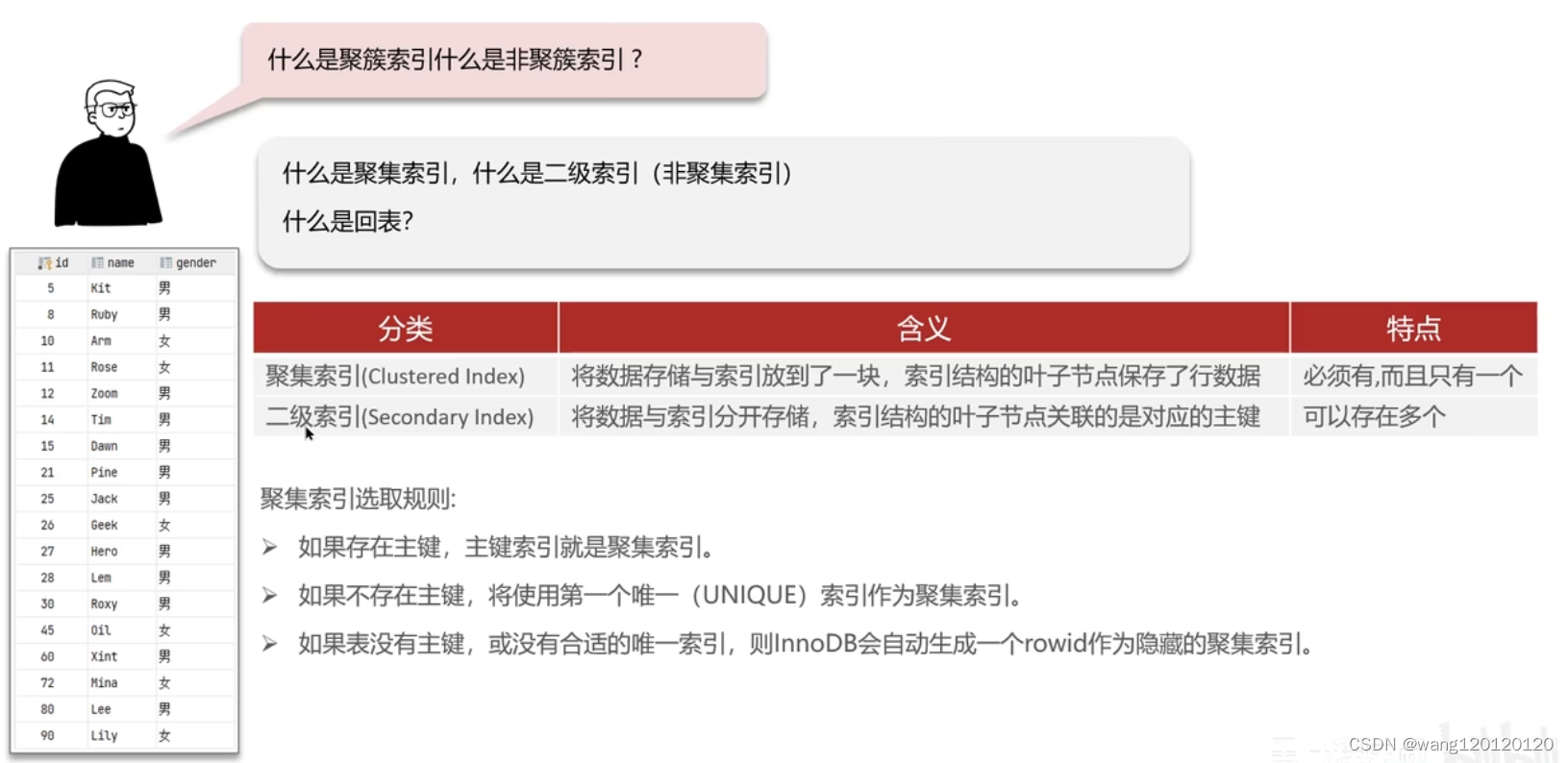
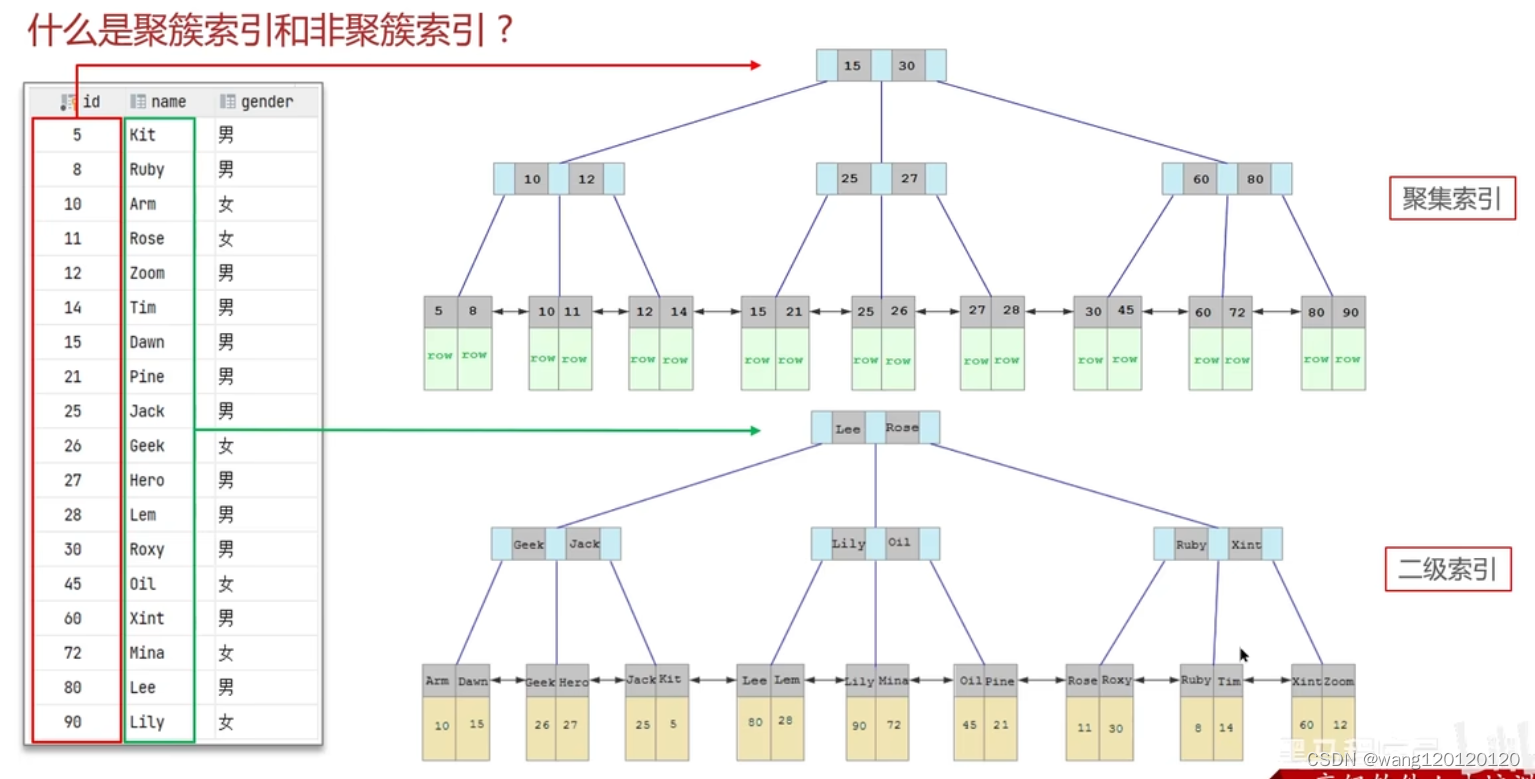
4、聚簇索引&非聚簇索引&回表查询
聚簇索引也叫聚集索引,非聚簇索引也叫二级索引
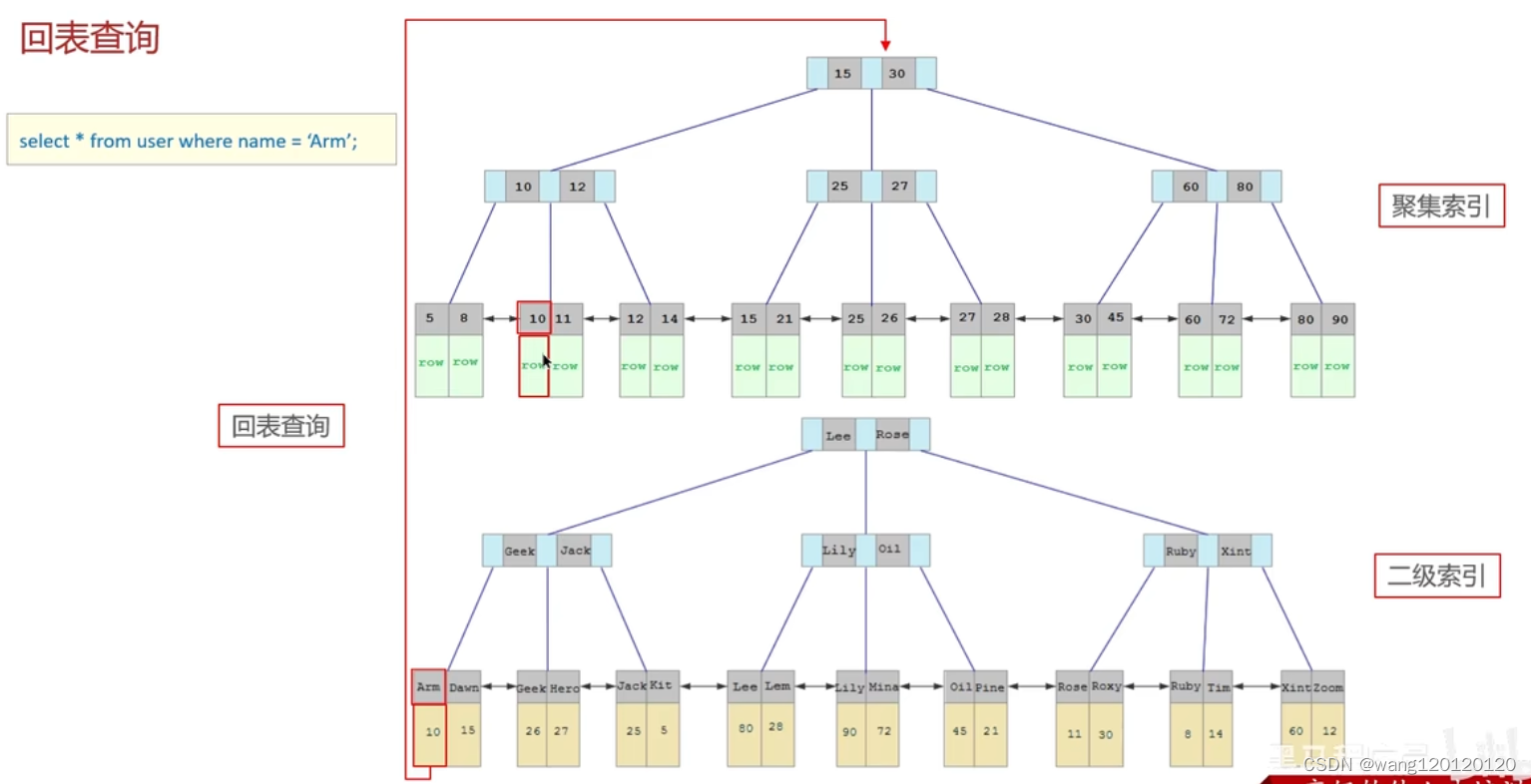
回表查询
先通过二级索引找到主键值,然后再到聚簇索引中拿到行数据
总结:


5、覆盖索引&超大分页面优化

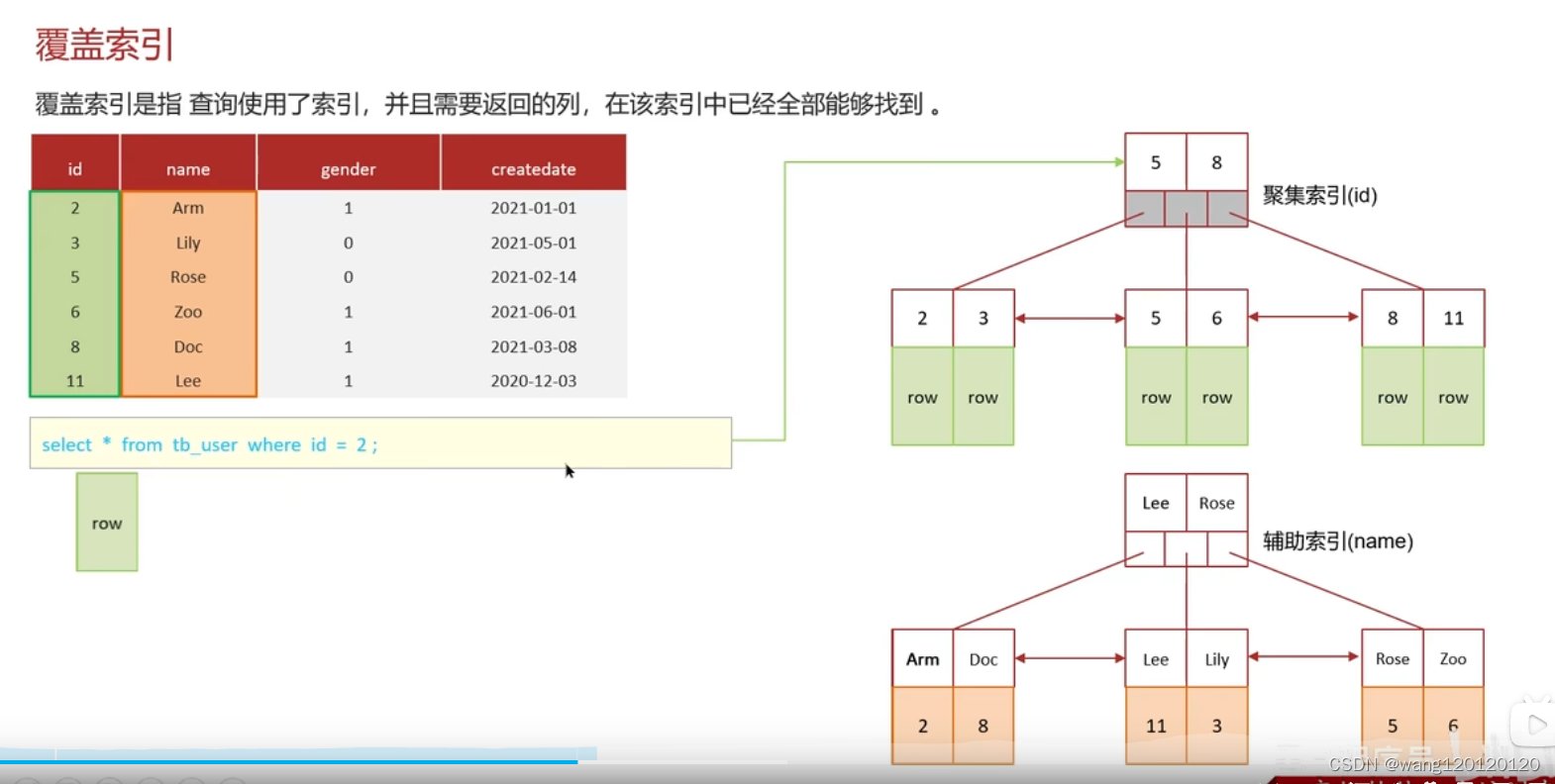
第二个sql,name是二级索引
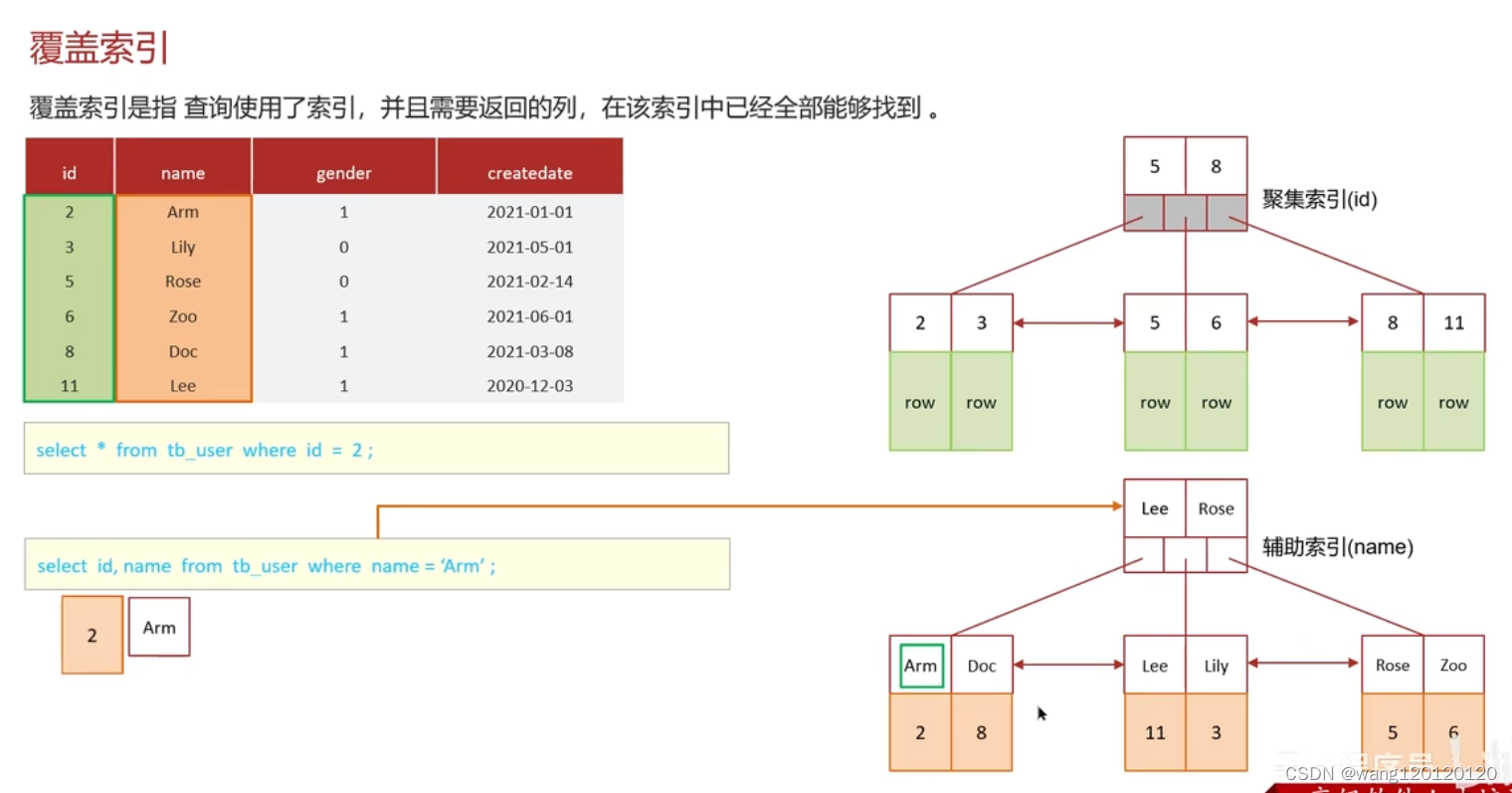
第三个sql,产生了回表查询
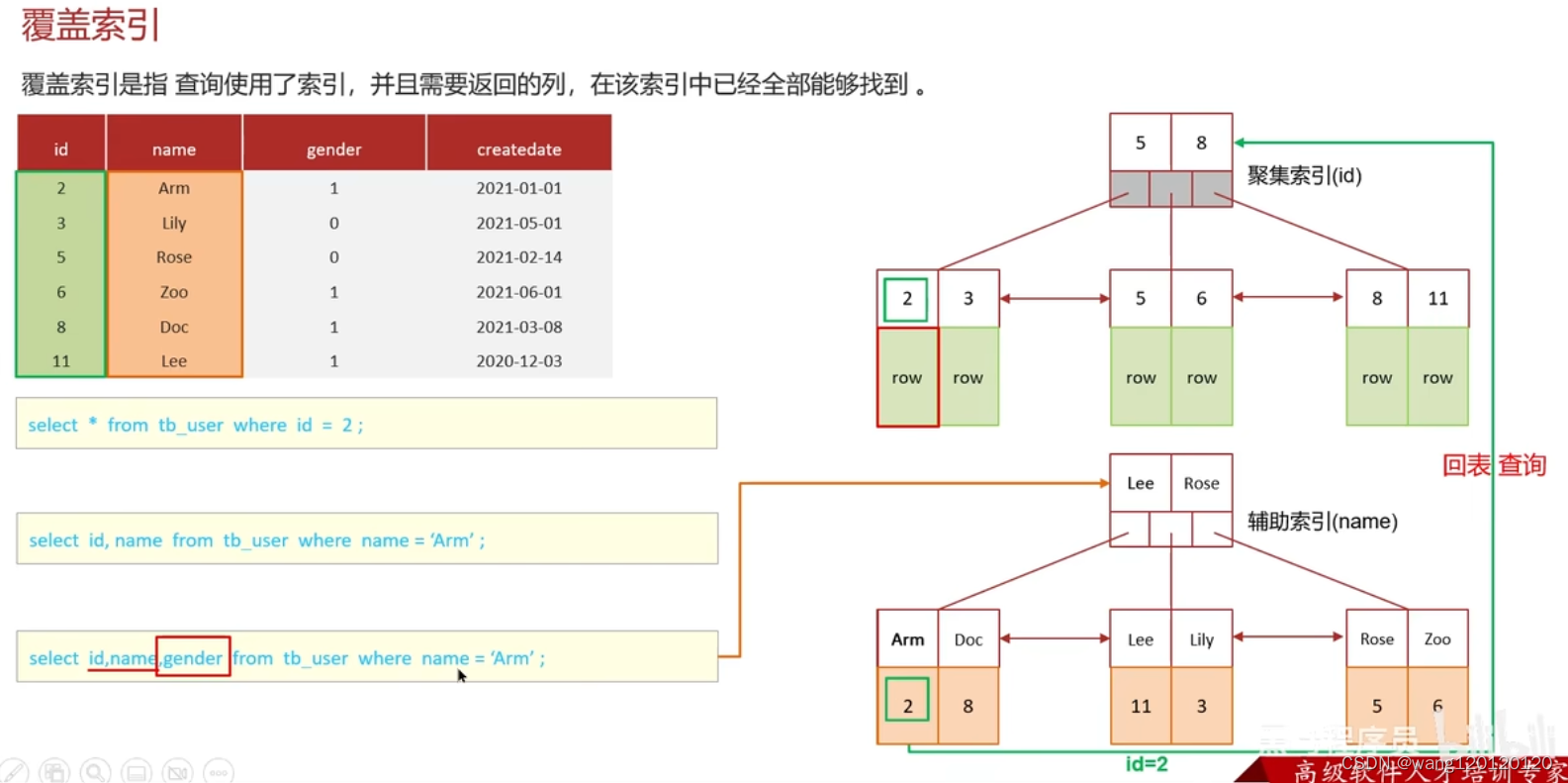
超大分页问题:可以用覆盖索引来解决
使用limit进行分页查询时,越往后,分页效率就越低

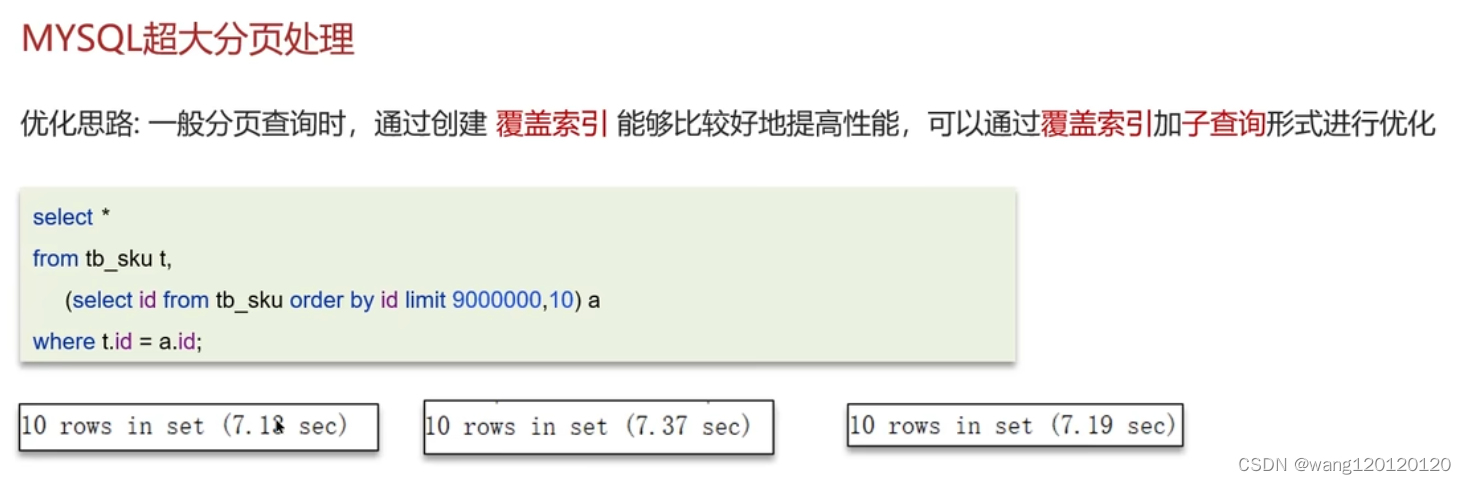
总结:


6、索引创建原则



添加前缀索引示例:
ALTER TABLE table_name
ADD INDEX idx_column_prefix (column_name(length));
这里的table_name是你想要添加索引的表名,column_name是要为其创建前缀索引的字段名,而length是所要索引的前缀长度。
例如,假设有一个用户表 users,其中包含一个非常长的 description 字段,你可能希望对前100个字符创建一个索引:
ALTER TABLE users
ADD INDEX idx_description_prefix (description(100));
这将在 description 列上创建一个仅包含每个记录前100个字符的索引。当然,选择合适的前缀长度需要根据实际业务场景和数据分布来确定。
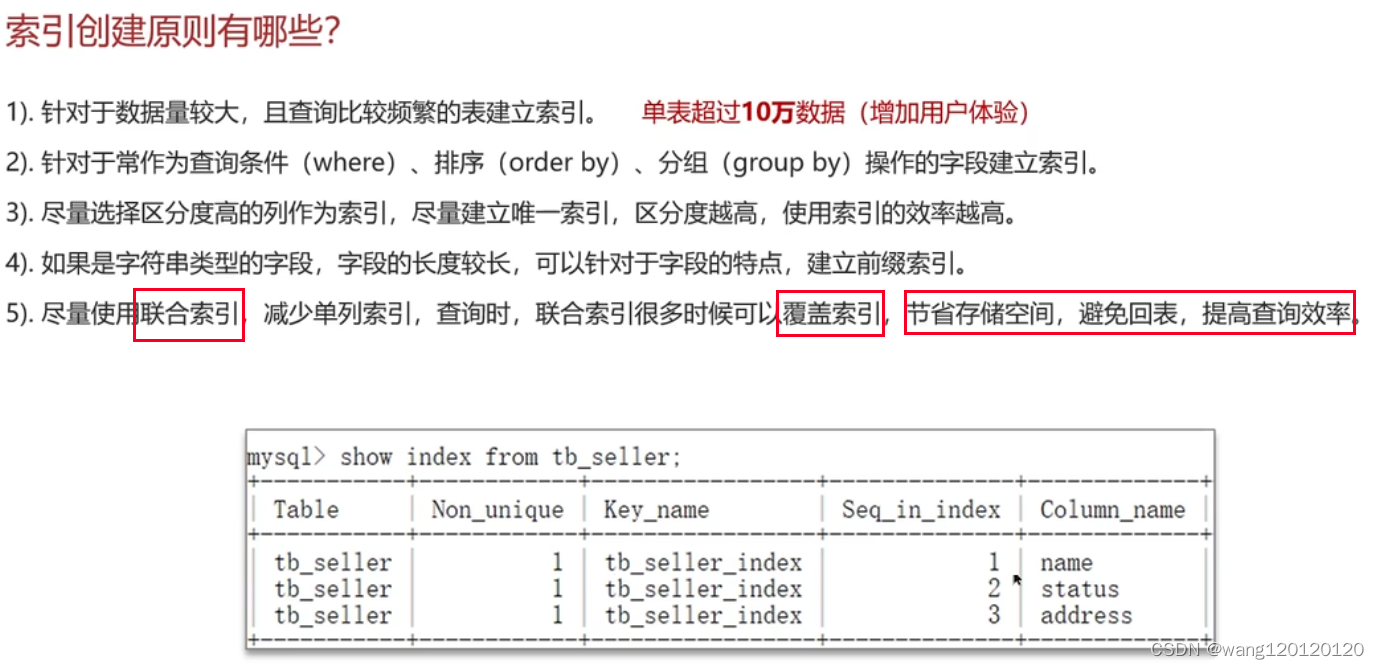

总结:


7、索引失效场景
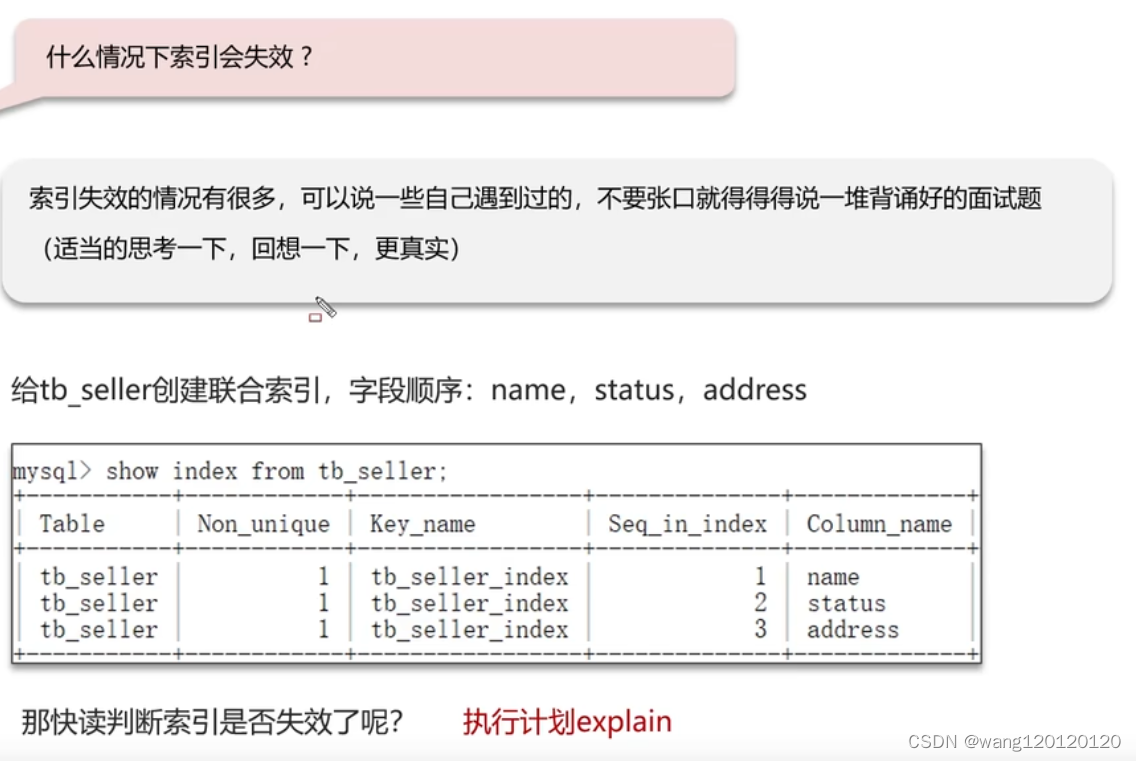

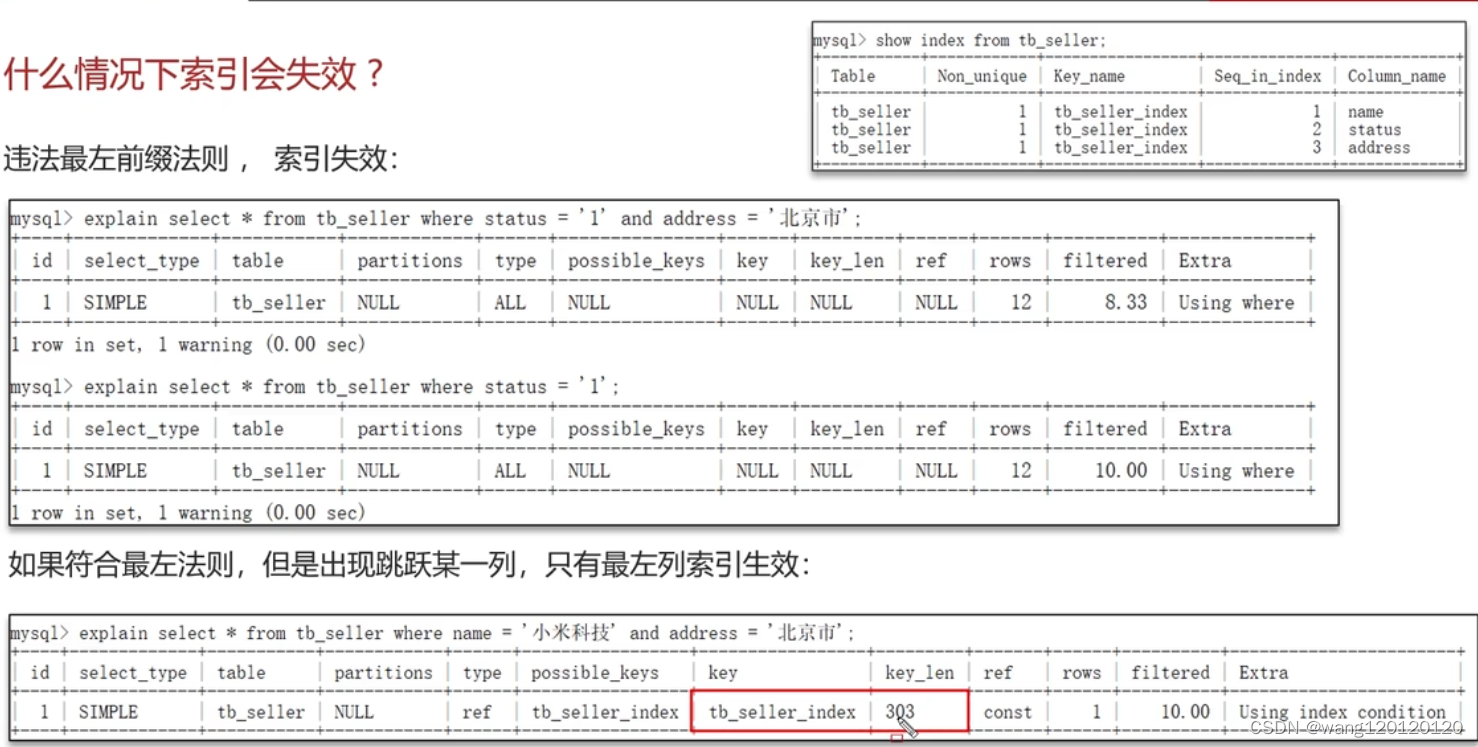

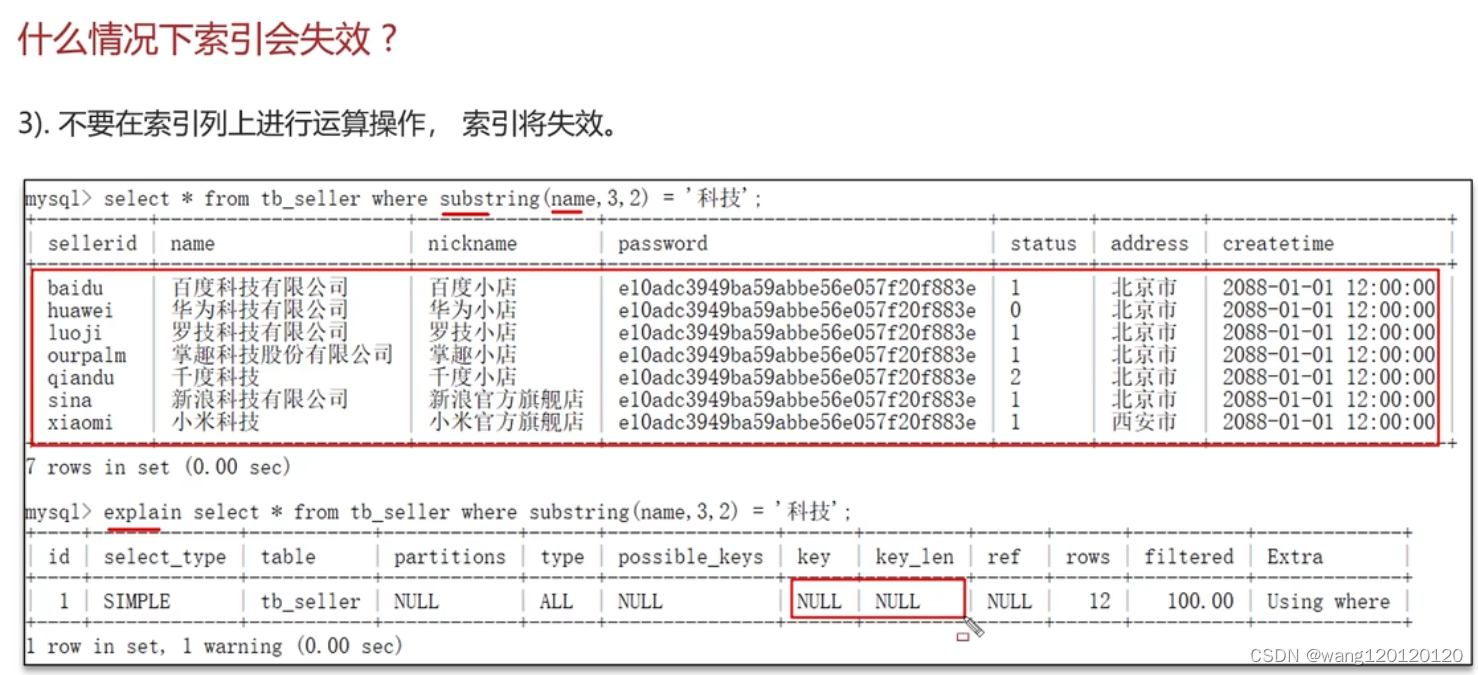

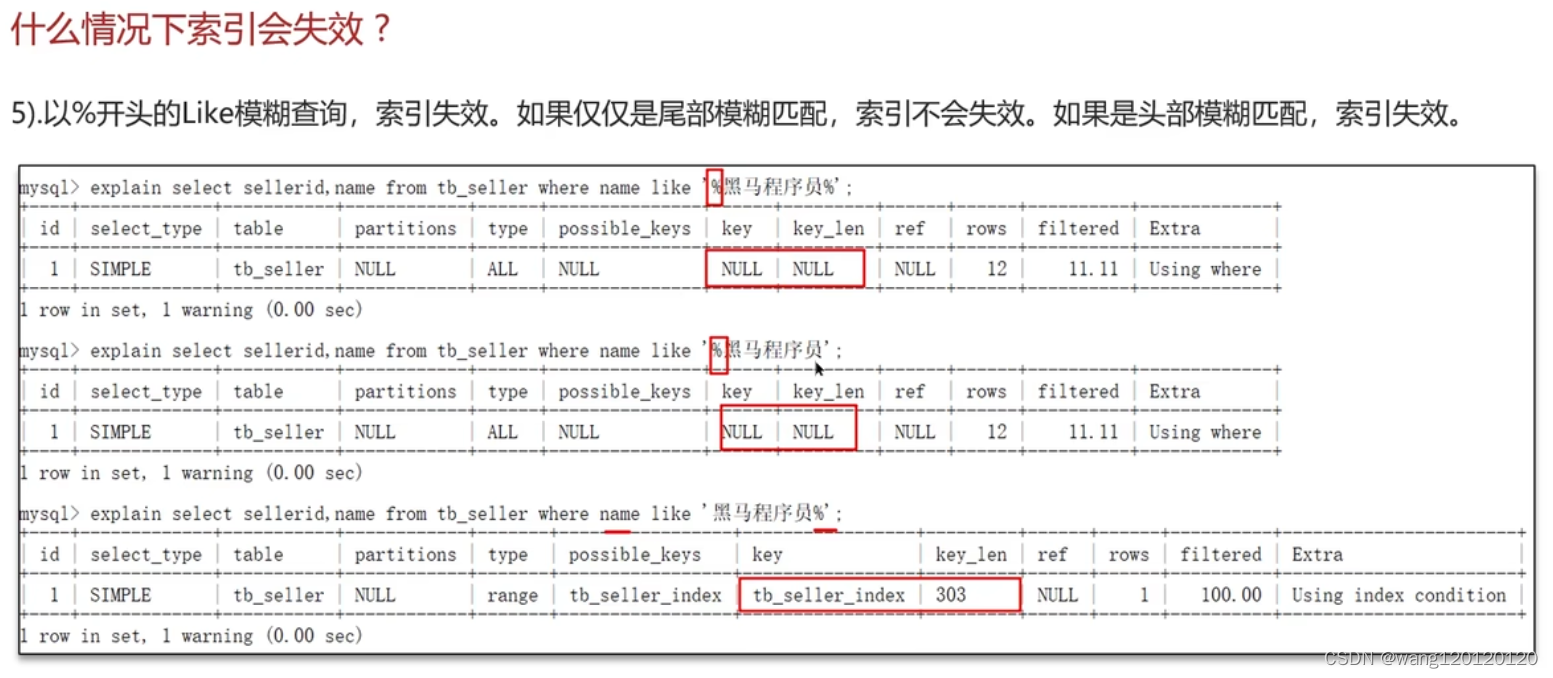
总结:


8、sql优化经验
从三方面 表设计 sql语句优化 主从复制、读写分离

表设计优化 sql语句优化

union all 代替 union union all 查询出来的即使有重复数据,也会展示出来
union会帮你过滤掉

第五条:以小表为驱动
外面的小循环就相当于是一个小表,里面的小循环就是相当于一个大表
把小循环放到外面就相当于小循环有3次的连接,在里面分别执行1000次操作即可
把小循环放到里面就相当于小循环有1000次的连接,在里面分别执行3次操作即可
所以小表放外面会更好点

主从复制、读写分离
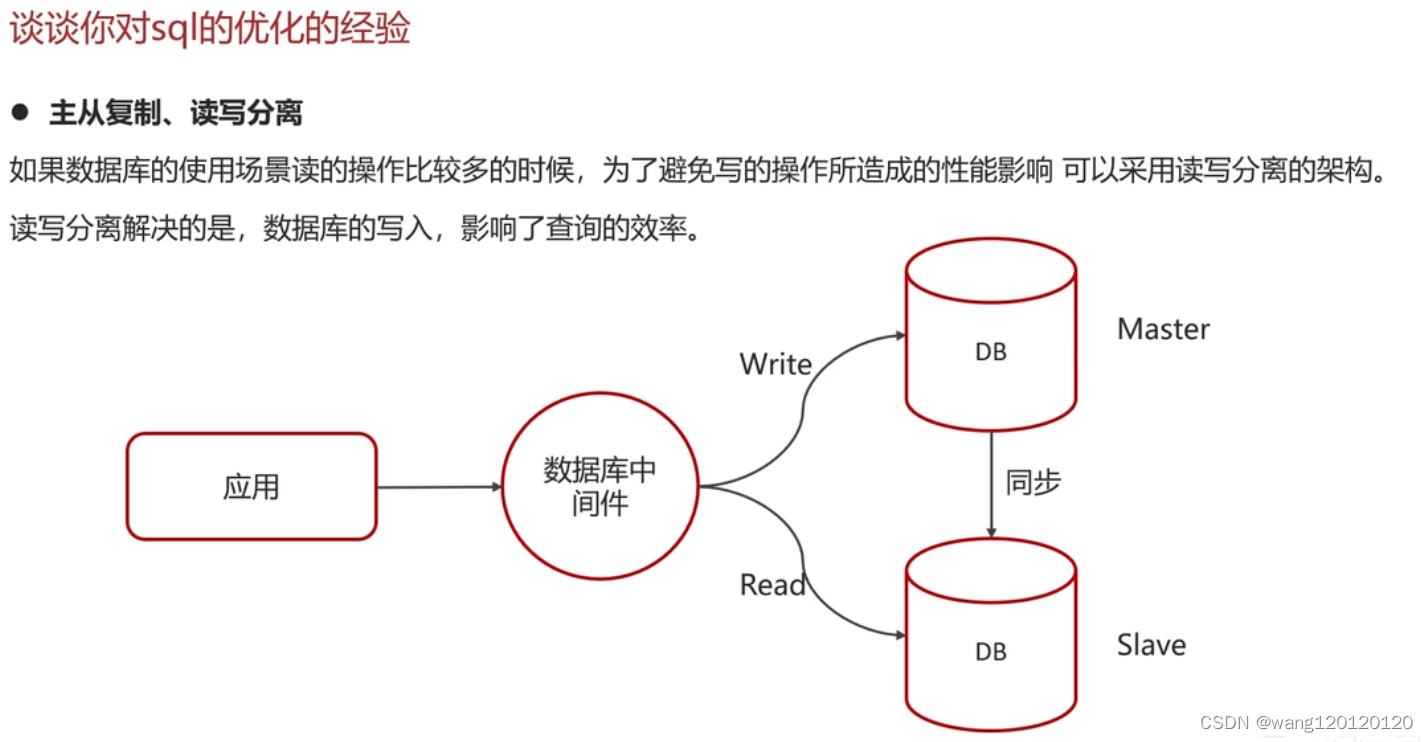
总结:


9、事务的特性


10、并发事务问题&隔离级别

脏读:
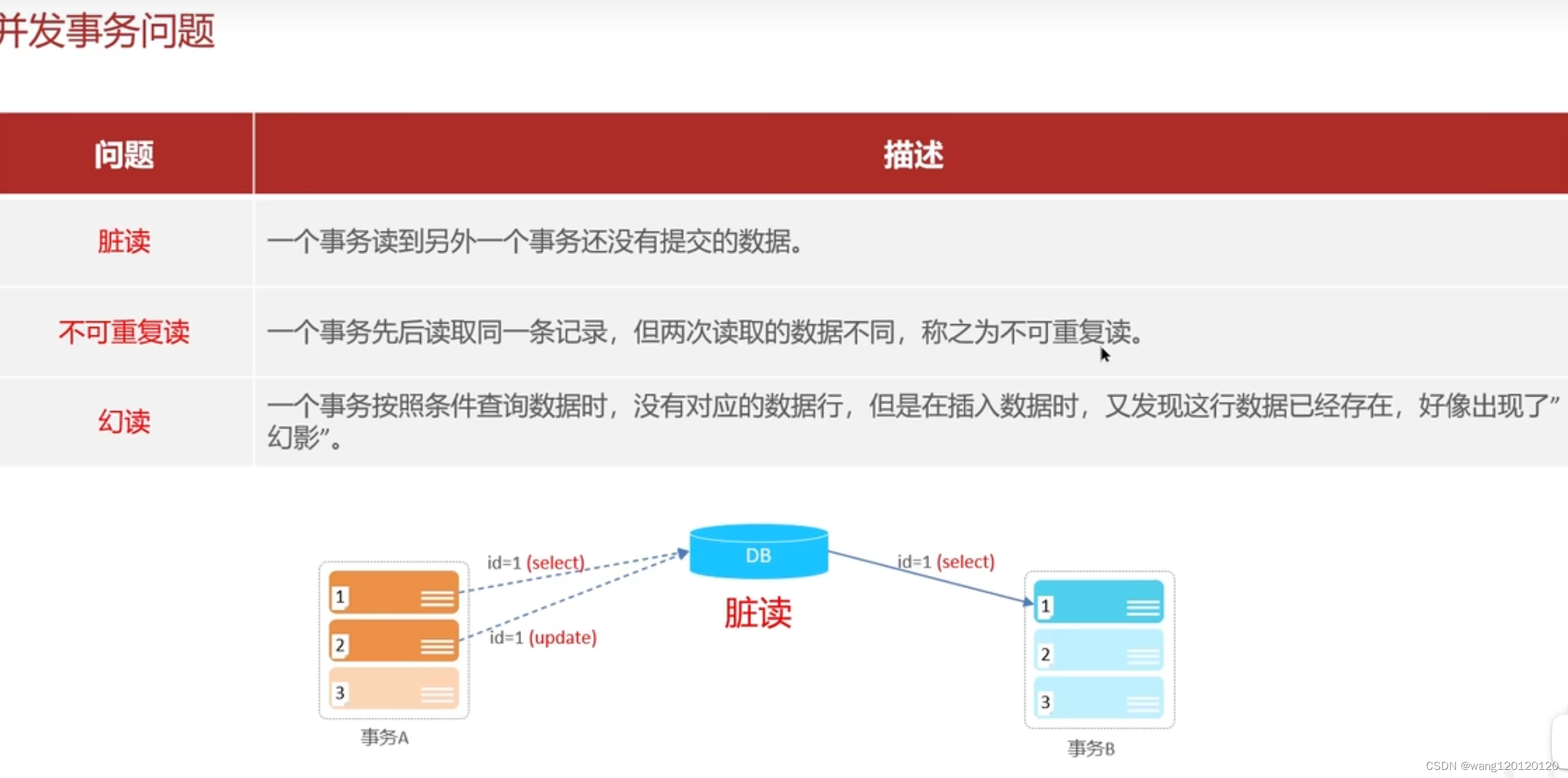
不可重复读:
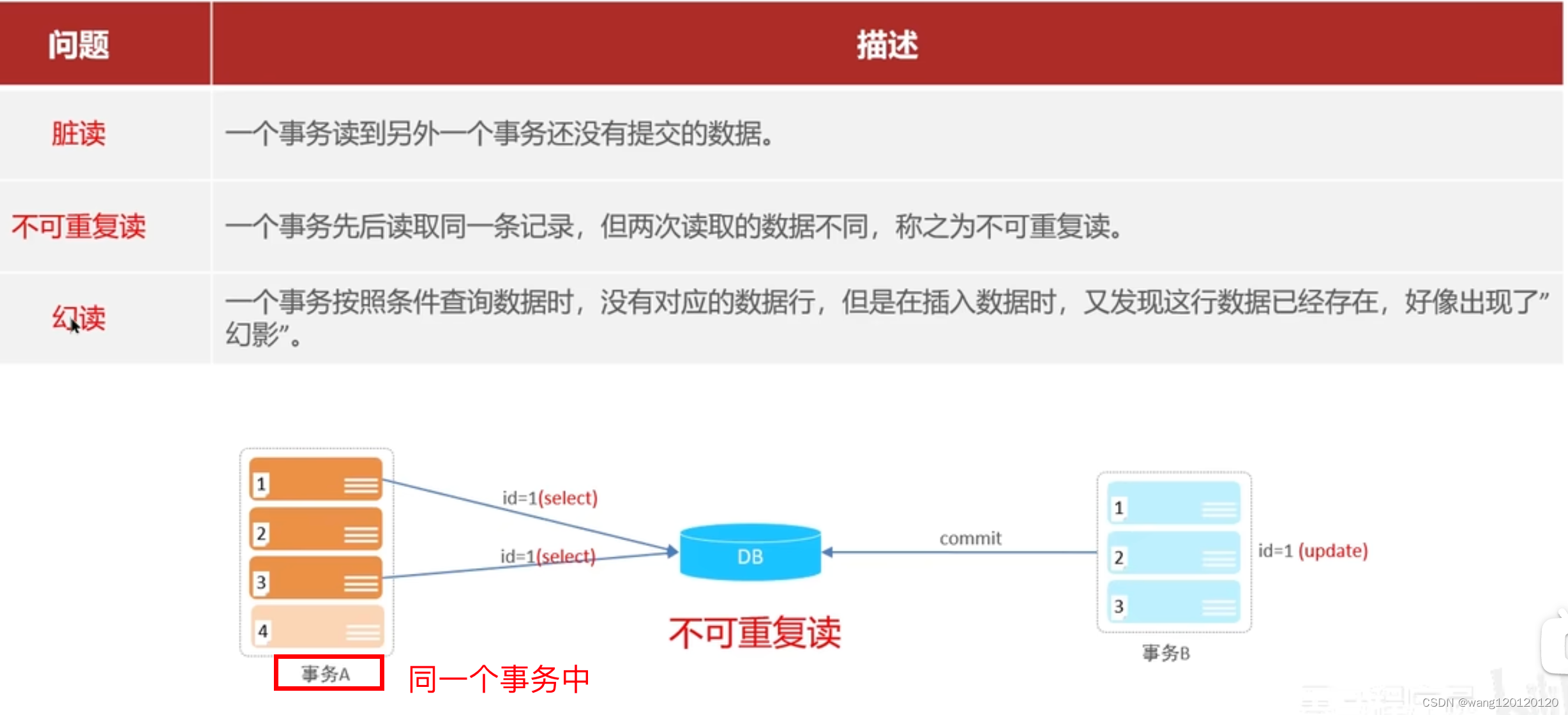
幻读:
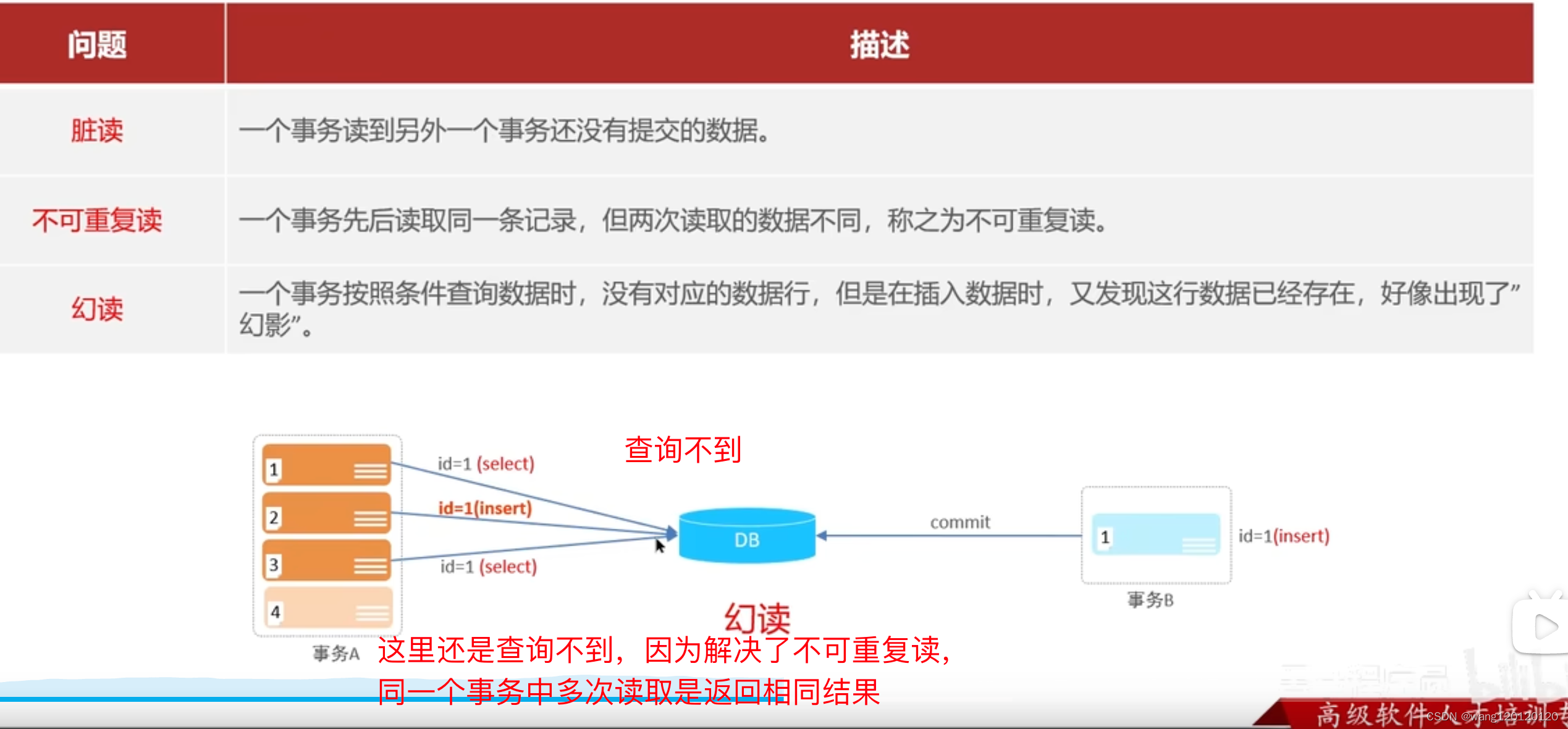
但是插入时又报错,说数据库中已经存在该数据了
事务的隔离级别:
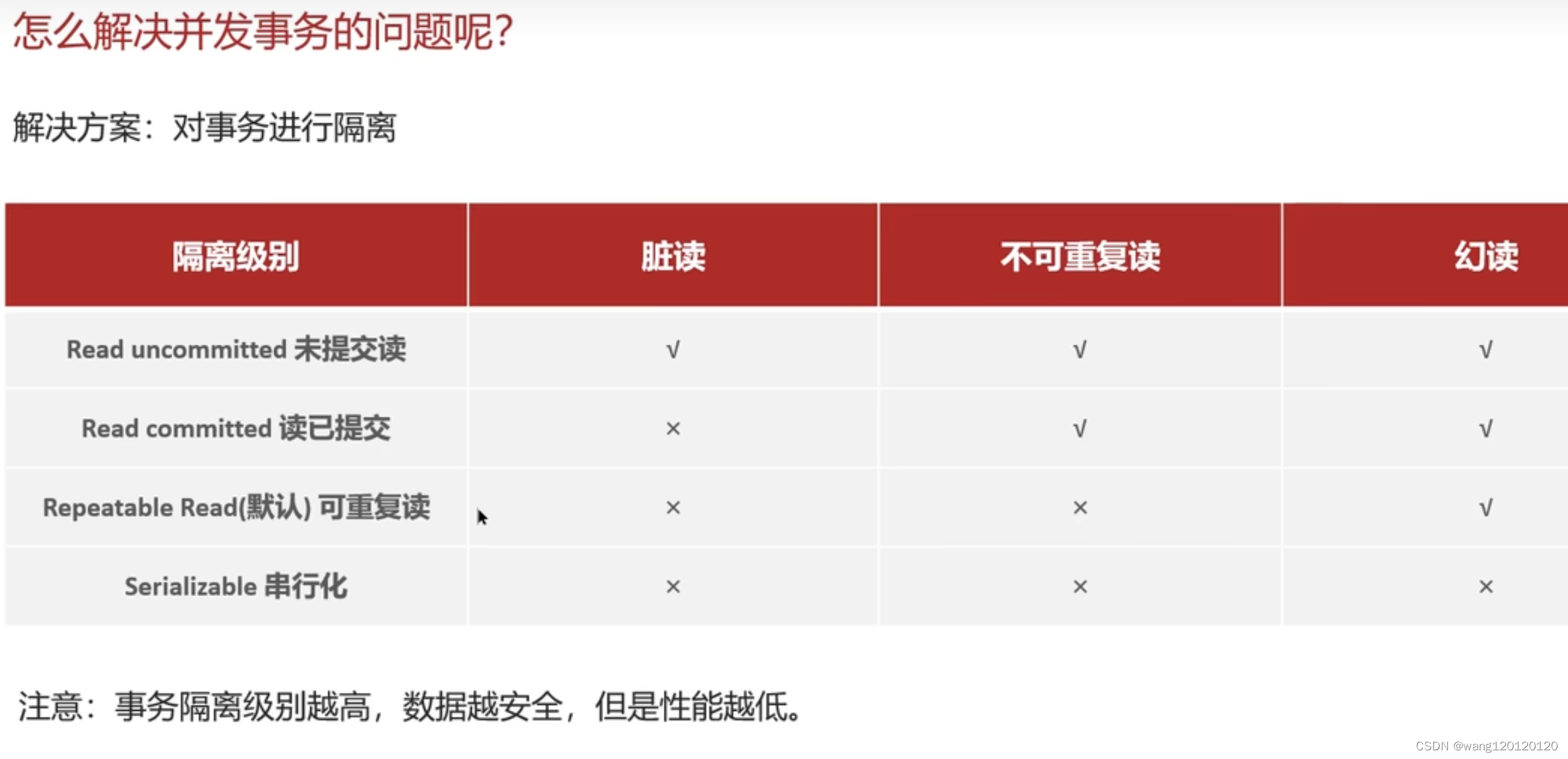
总结:


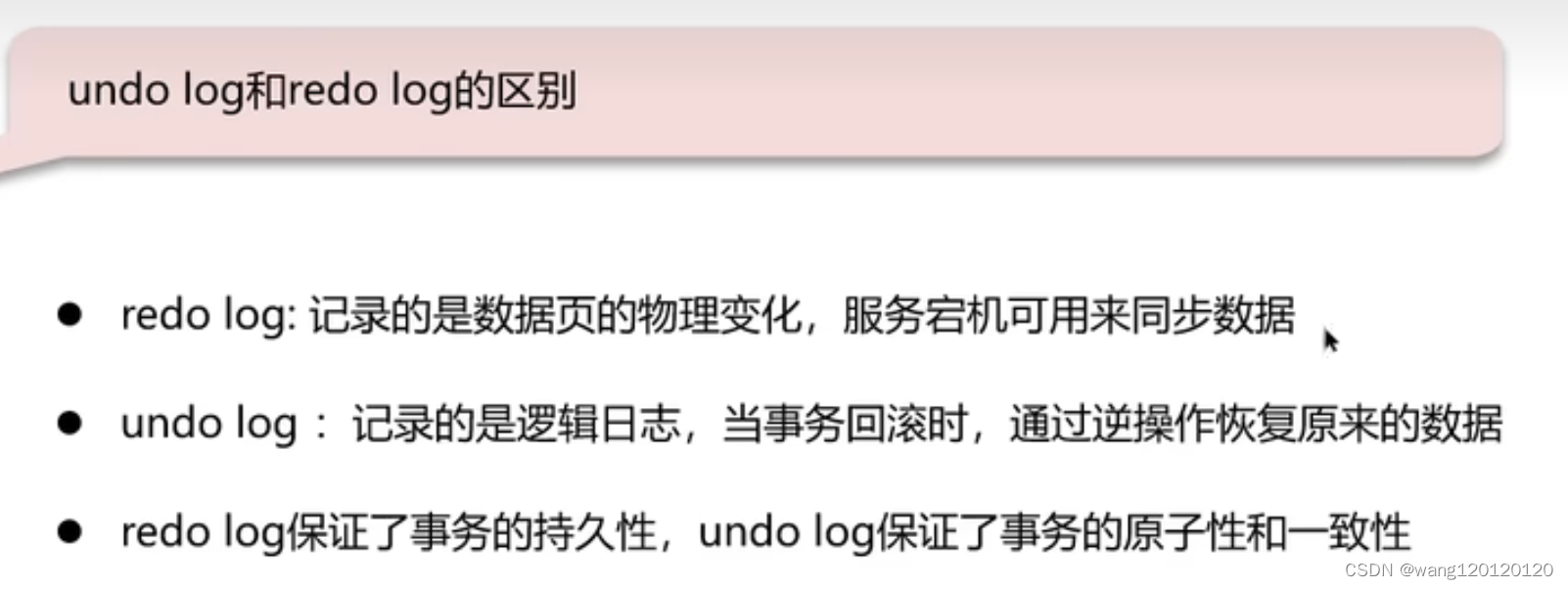
11、事务- undo log 和redo log的区别
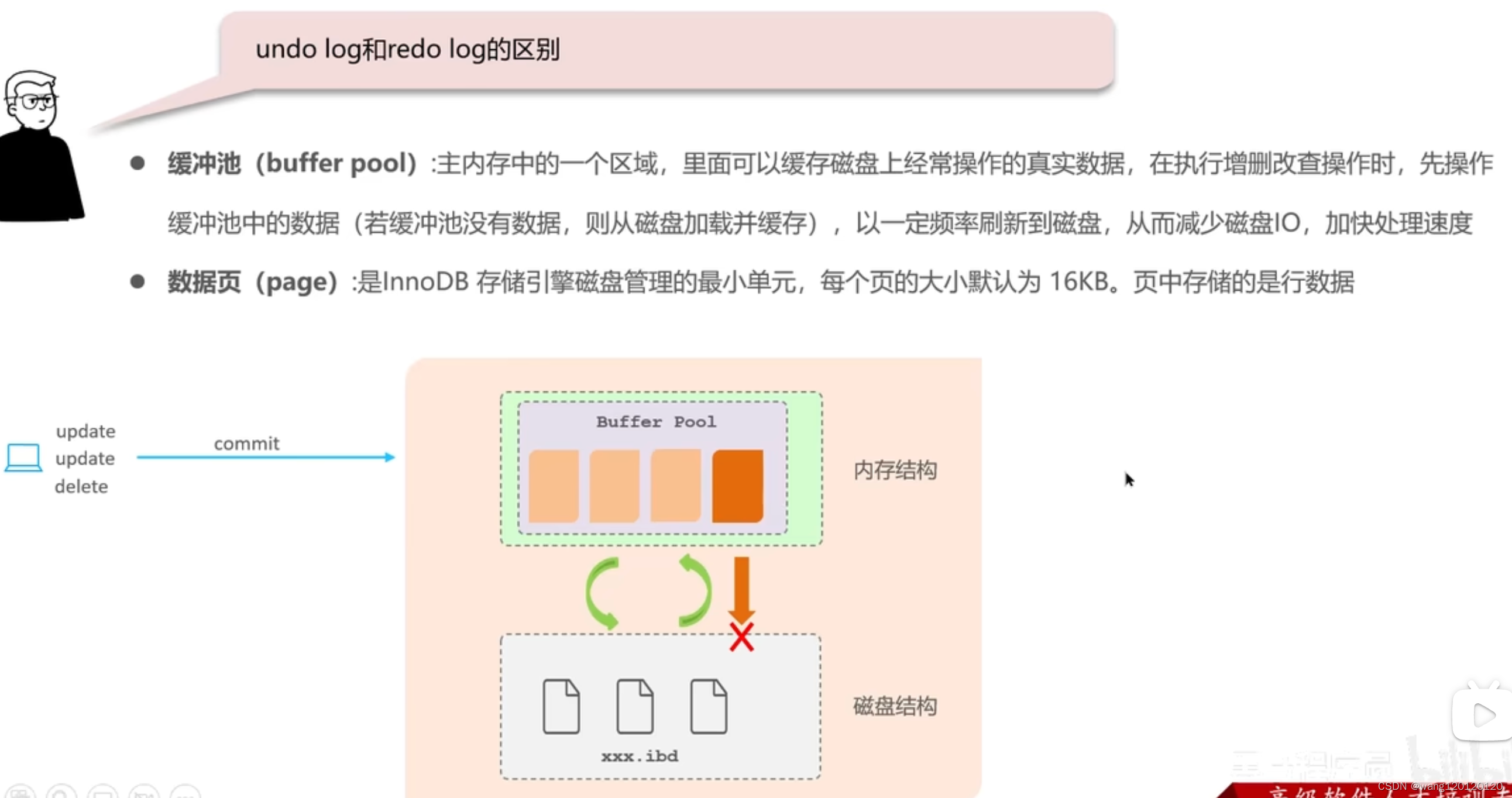
如果缓冲池中的数据没有刷新到磁盘中,中途出错了,会导致数据的丢失,解决方法:redo log
当可以正常的将缓冲次的数据刷新到磁盘中,redofile就没什么用,每隔一段时间就将redofile重置,redo log file 在磁盘有两份,可以互相同步数据
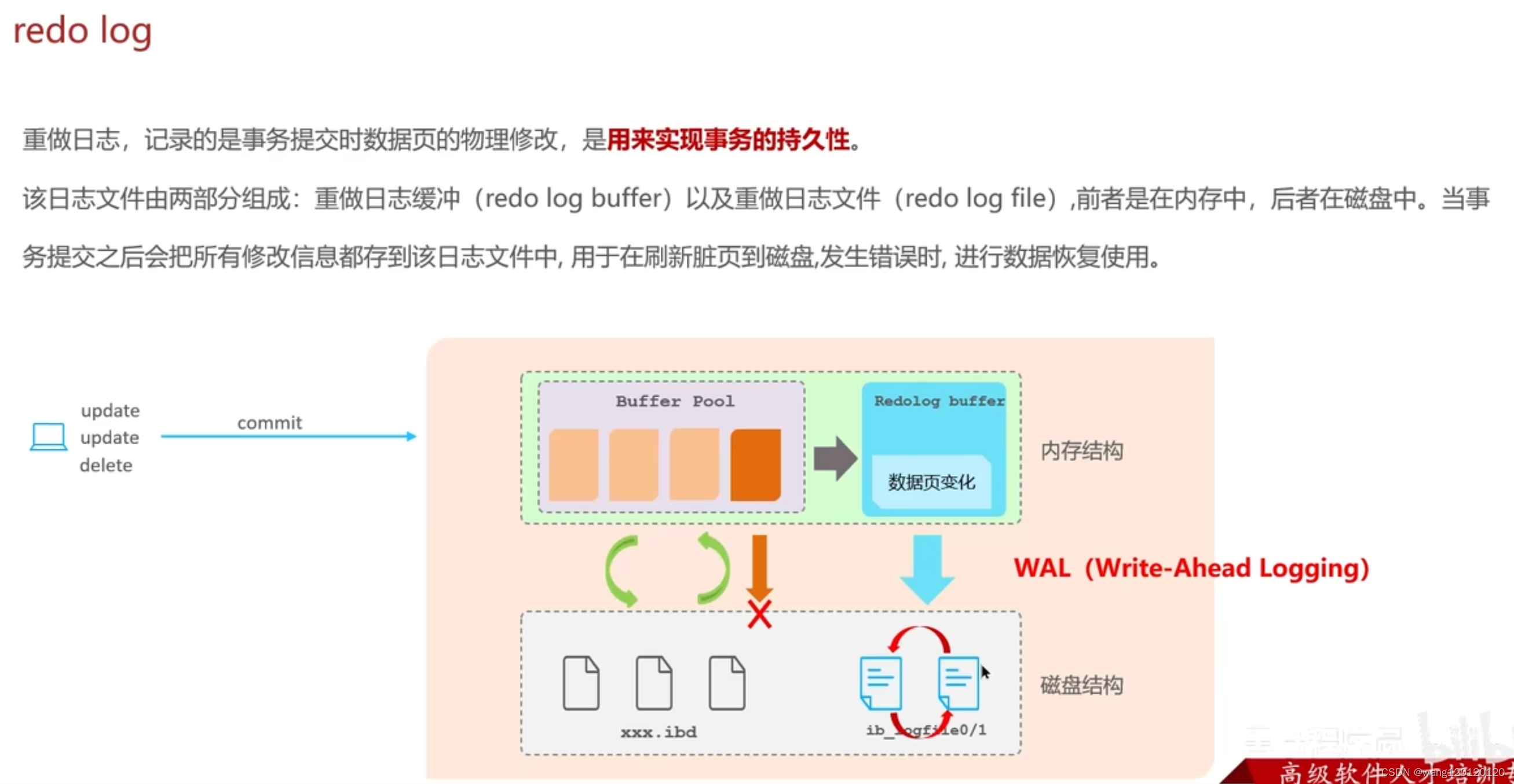
另外一种做法:undo log

总结:

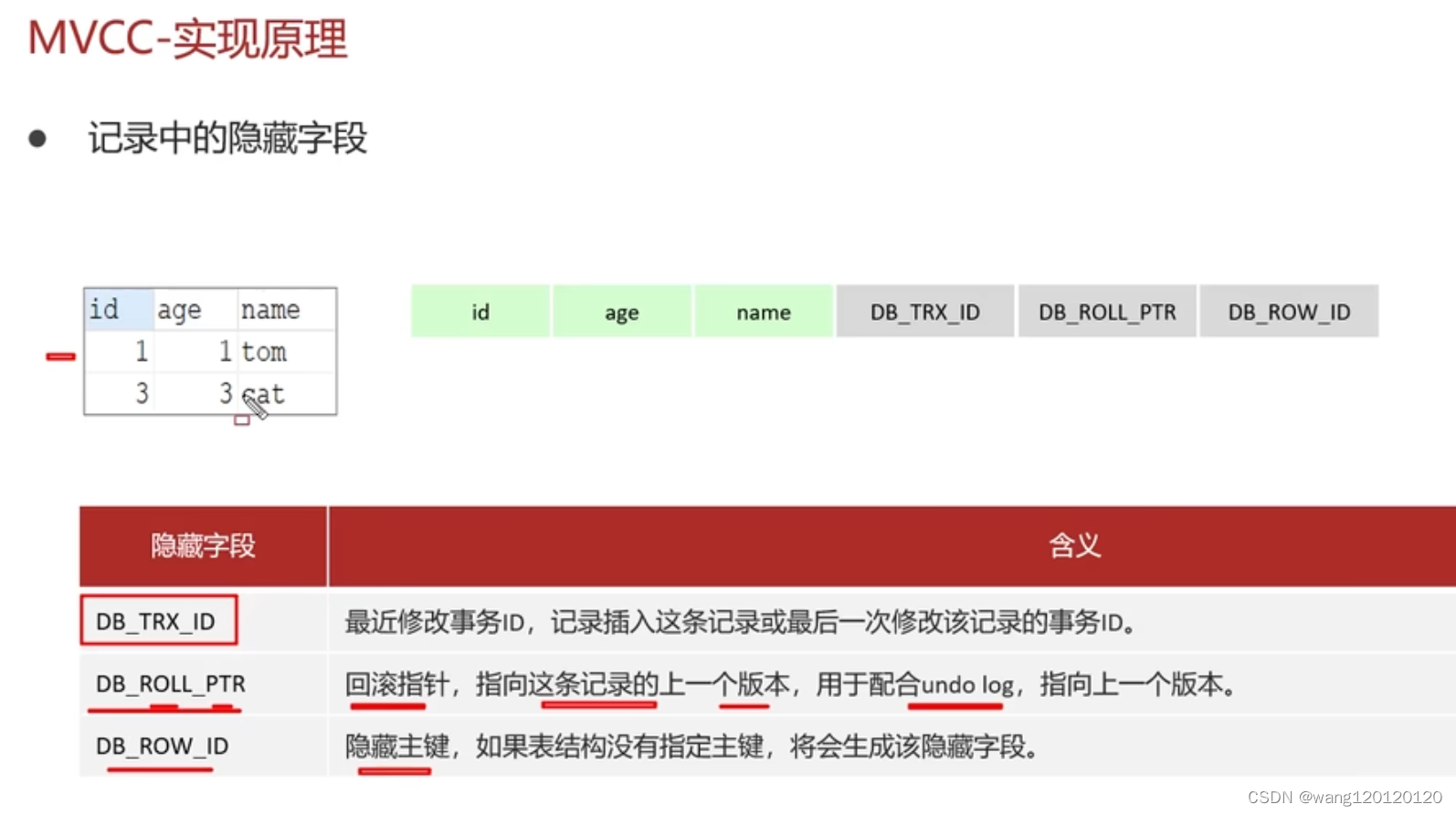
12、事务mvcc


第二个ptr 是指 pointer

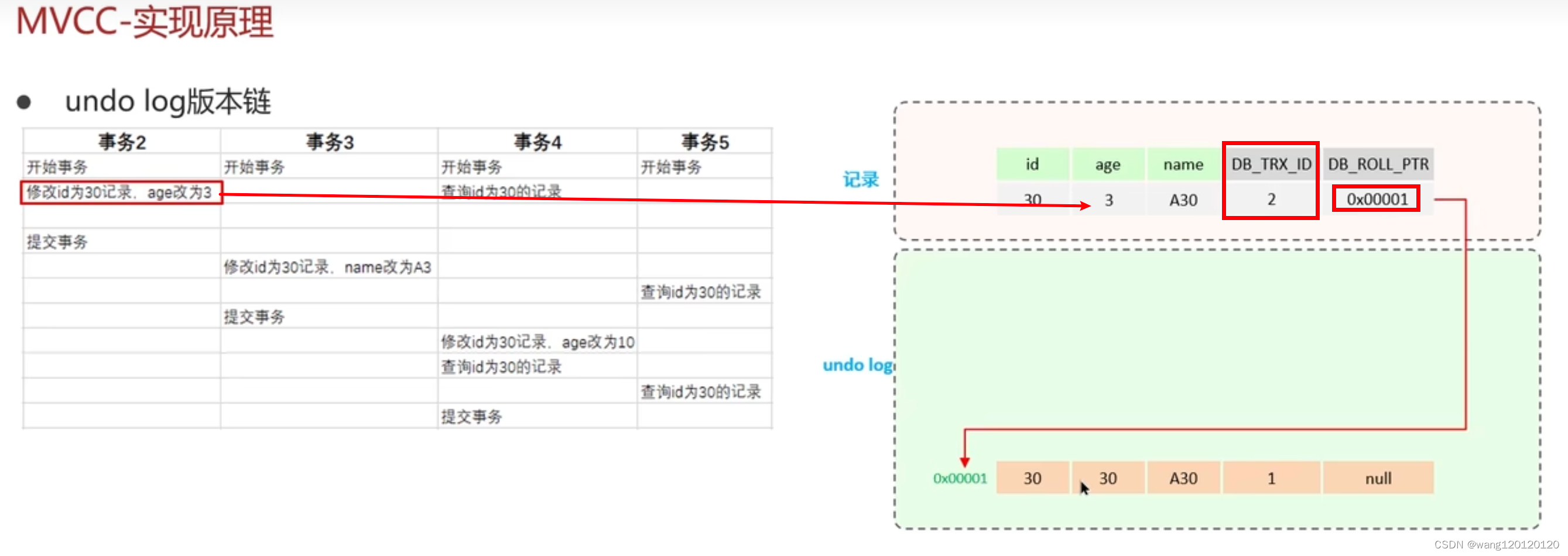
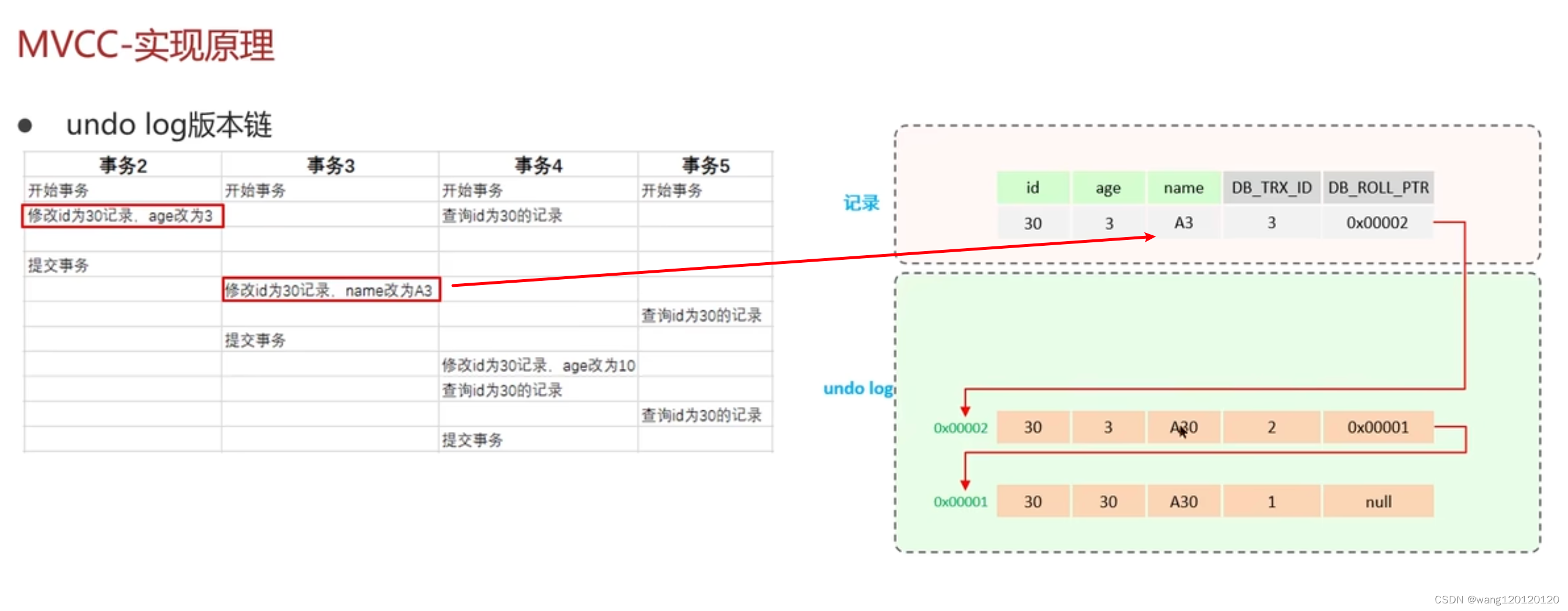
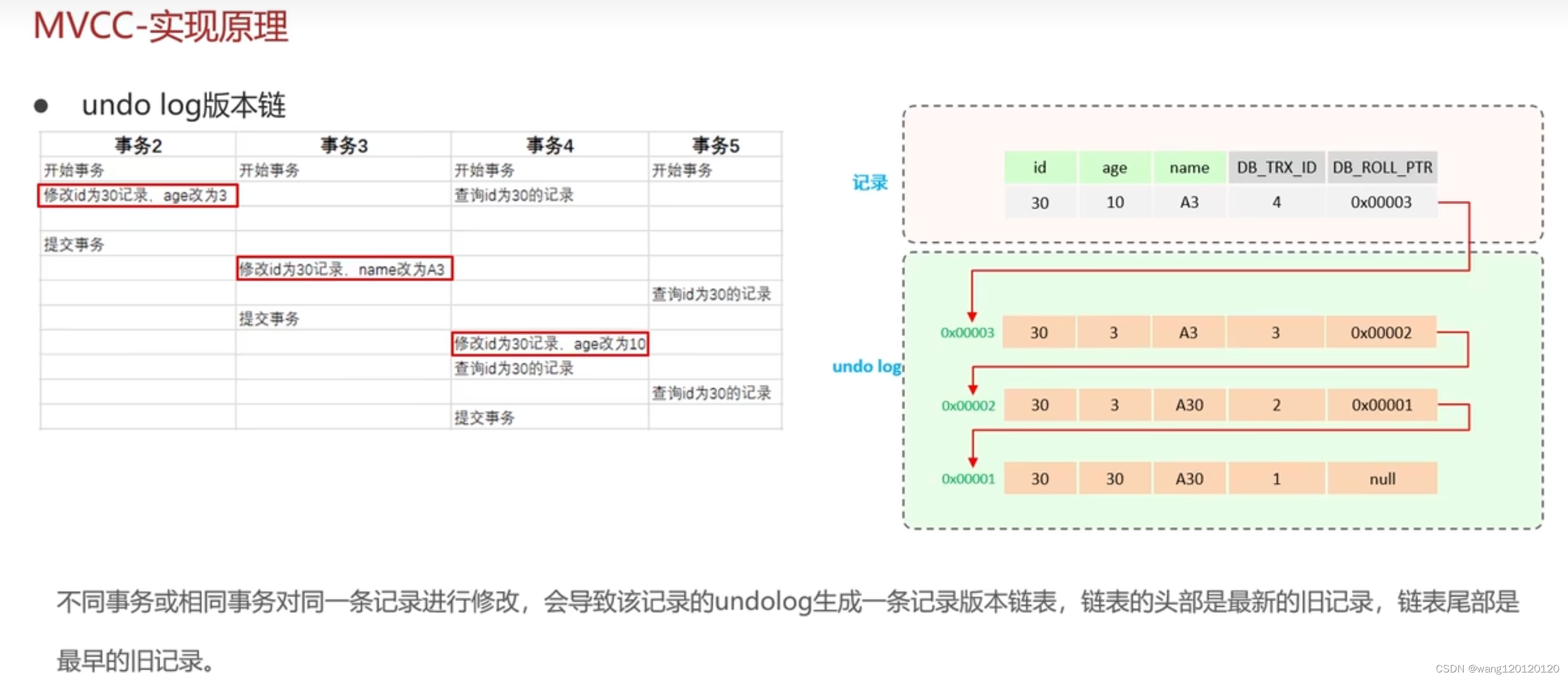
undo log 版本链:
记录undolog日志

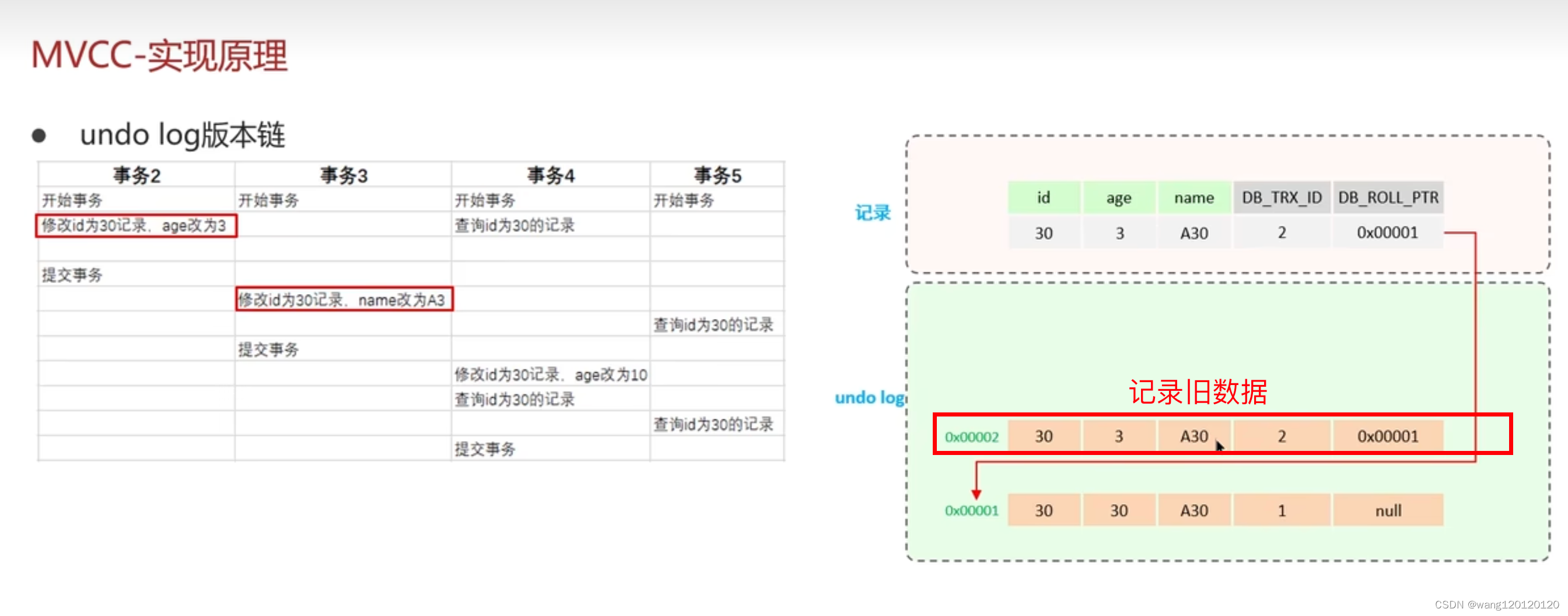
事务3修改动作导致:又产生了一条事务日志,新的事务日志记录指针指向上一条的地址
事务4操作的结果导致:又产生一条事务日志
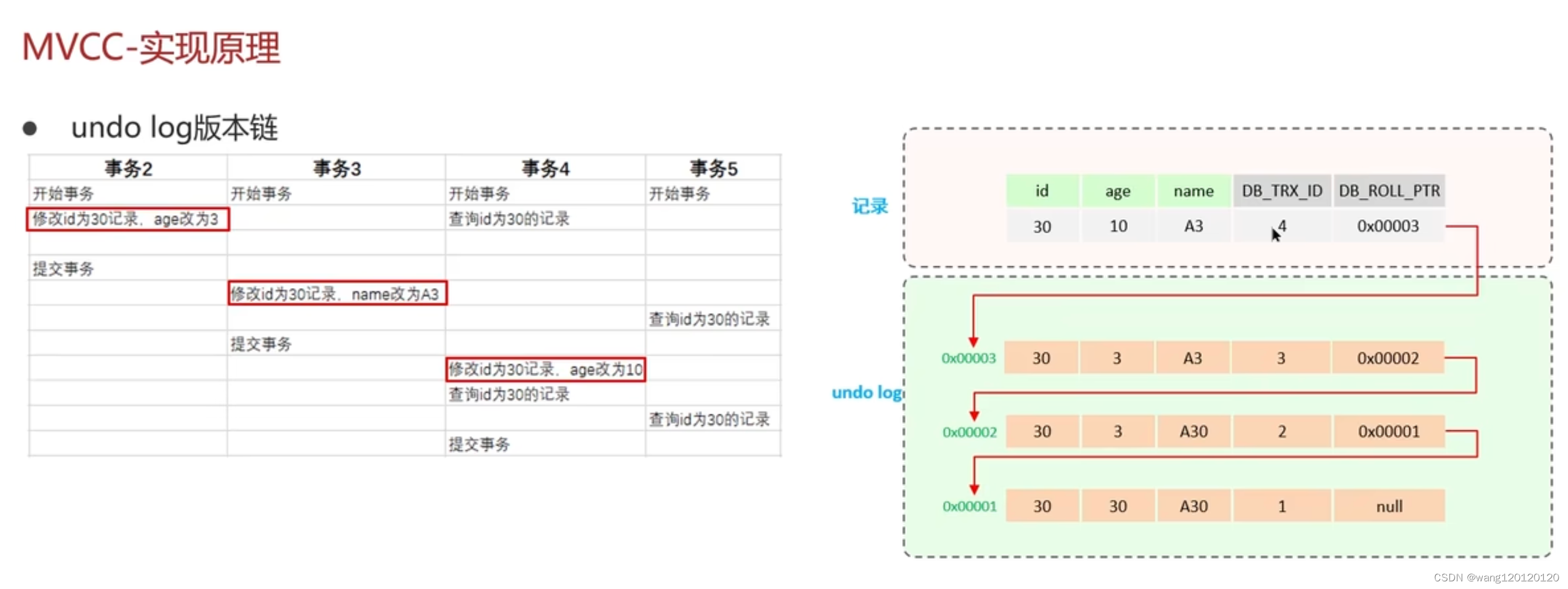
结果:
MVCC最后一块内容:readview

当前读:

快照读:
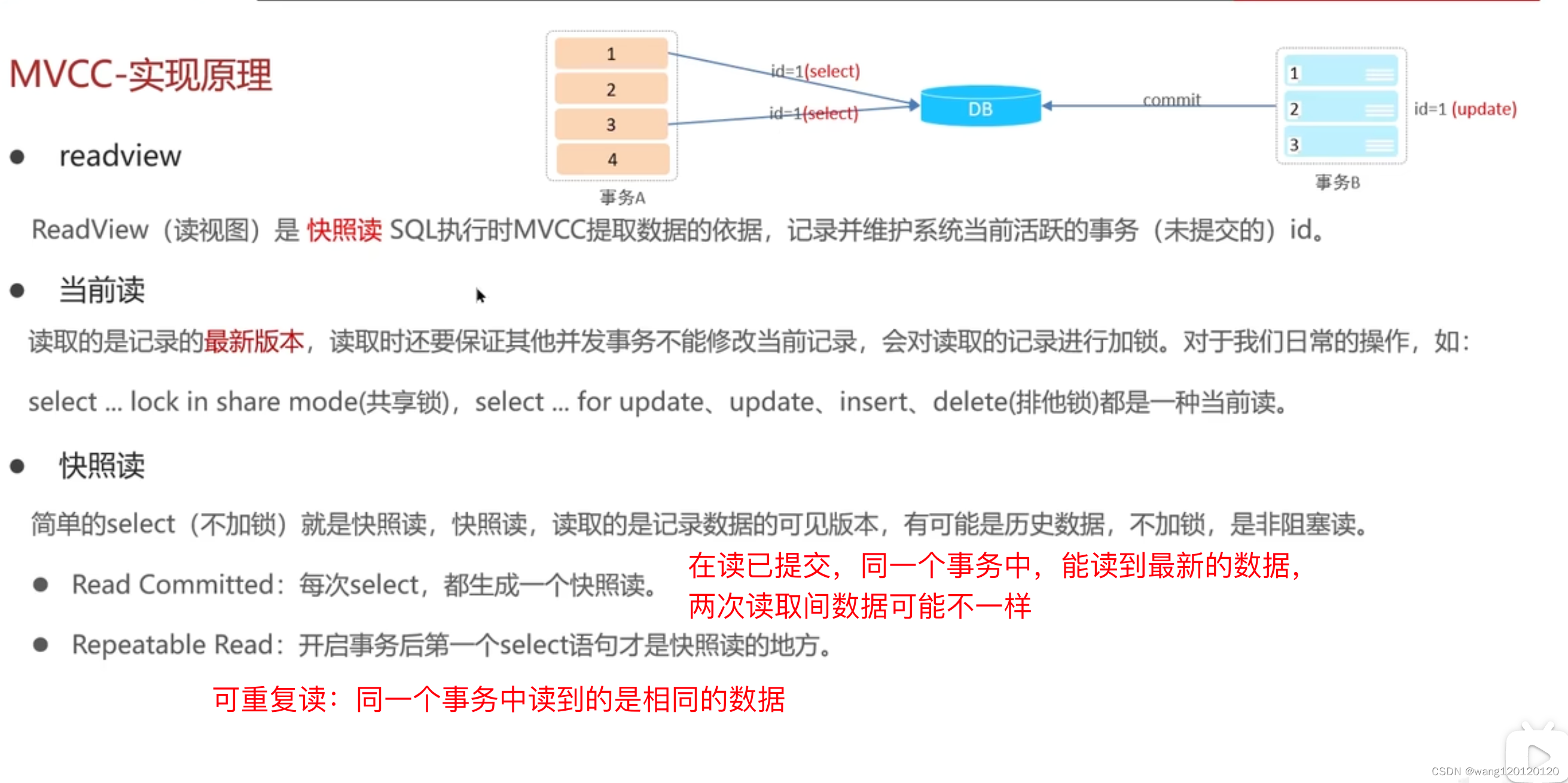
ReadView 读视图
预分配事务id就是5+1
readview创建者的事务id:就是5
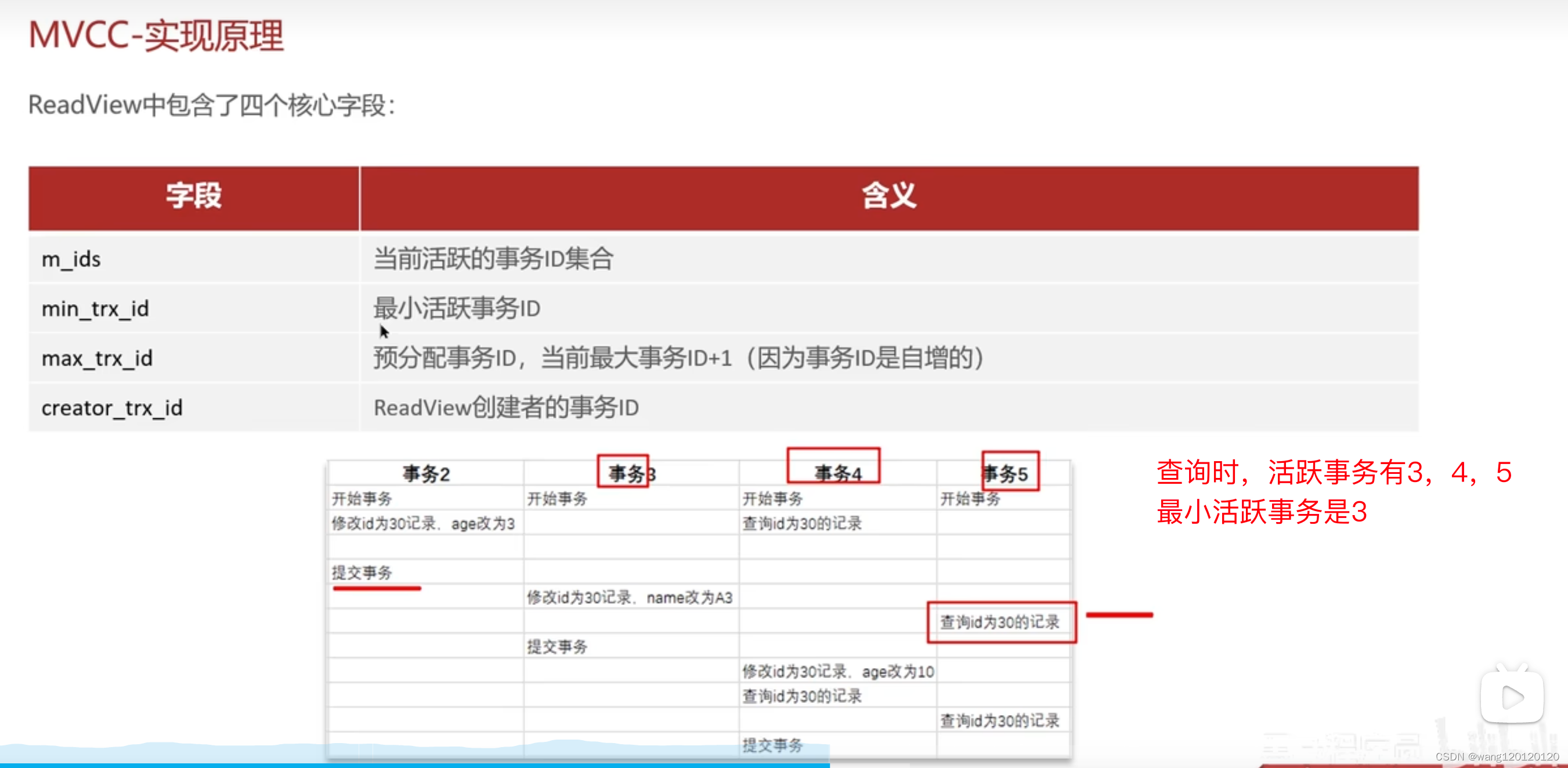

在RC read committed 隔离级别下:
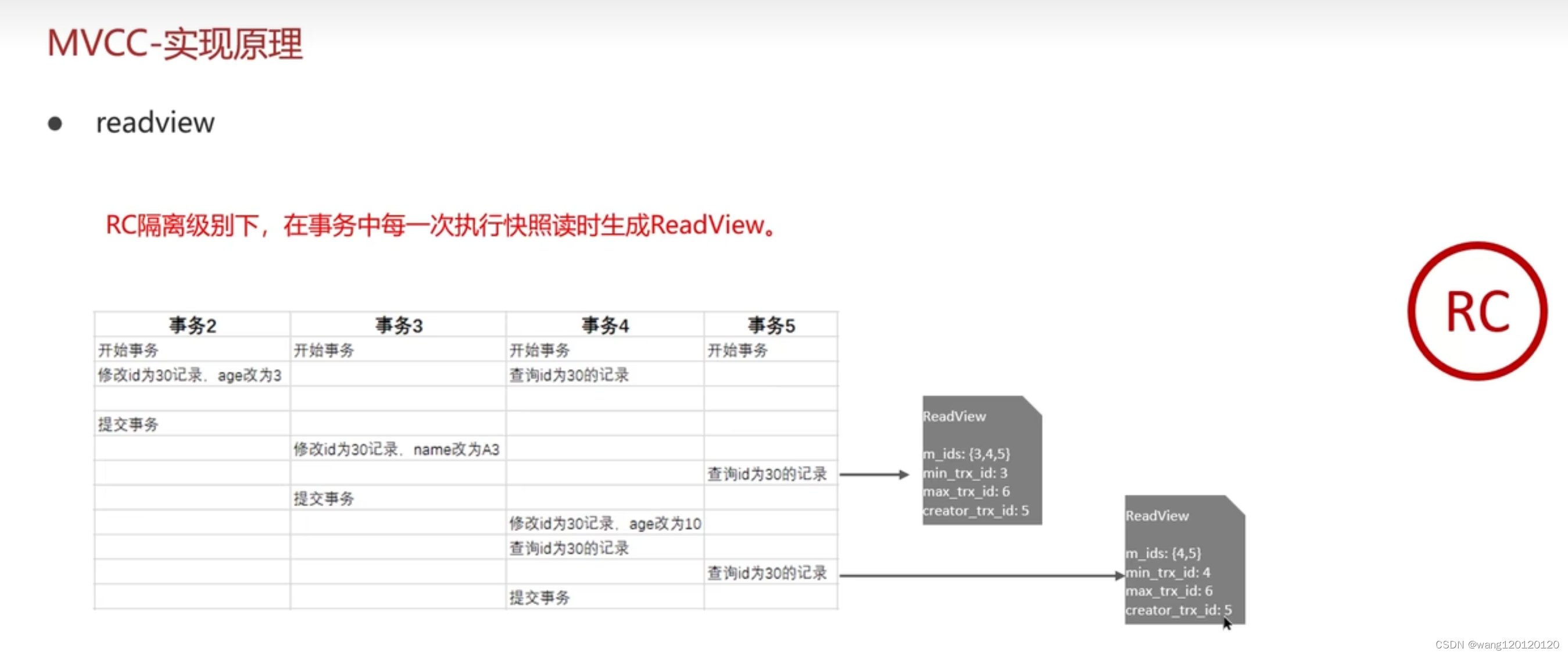
分析:
第一个读视图得到的条件:
版本链共有4个
4 4不满足右边的条件
3,3不满足右边的条件
2,2不满足右边的条件,第一个读视图得到的条件
所以在事务5的第一个读视图中可以读到事务2的数据
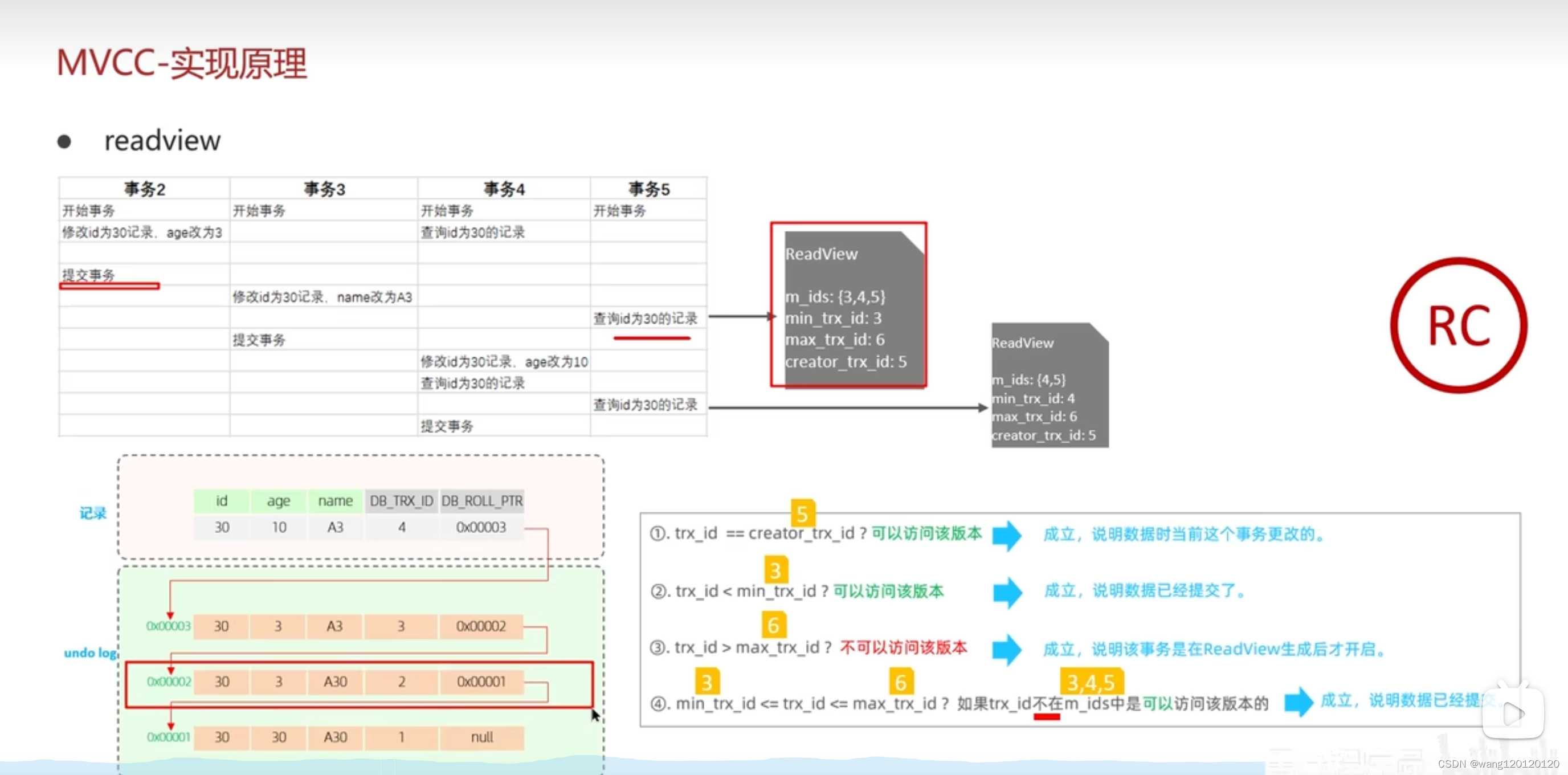
第二个读视图的结果:
事务5的第二个读视图,在版本链中事务4不满足右边的条件
事务3满足右边的条件
也就是说事务5的第二个读视图可以读取到事务3的数据 ,也就是说事务5第二个查询拿到的结果就是第3条
也就是说在read committed 情况下,会存在相同查询得到不同结果的情况。
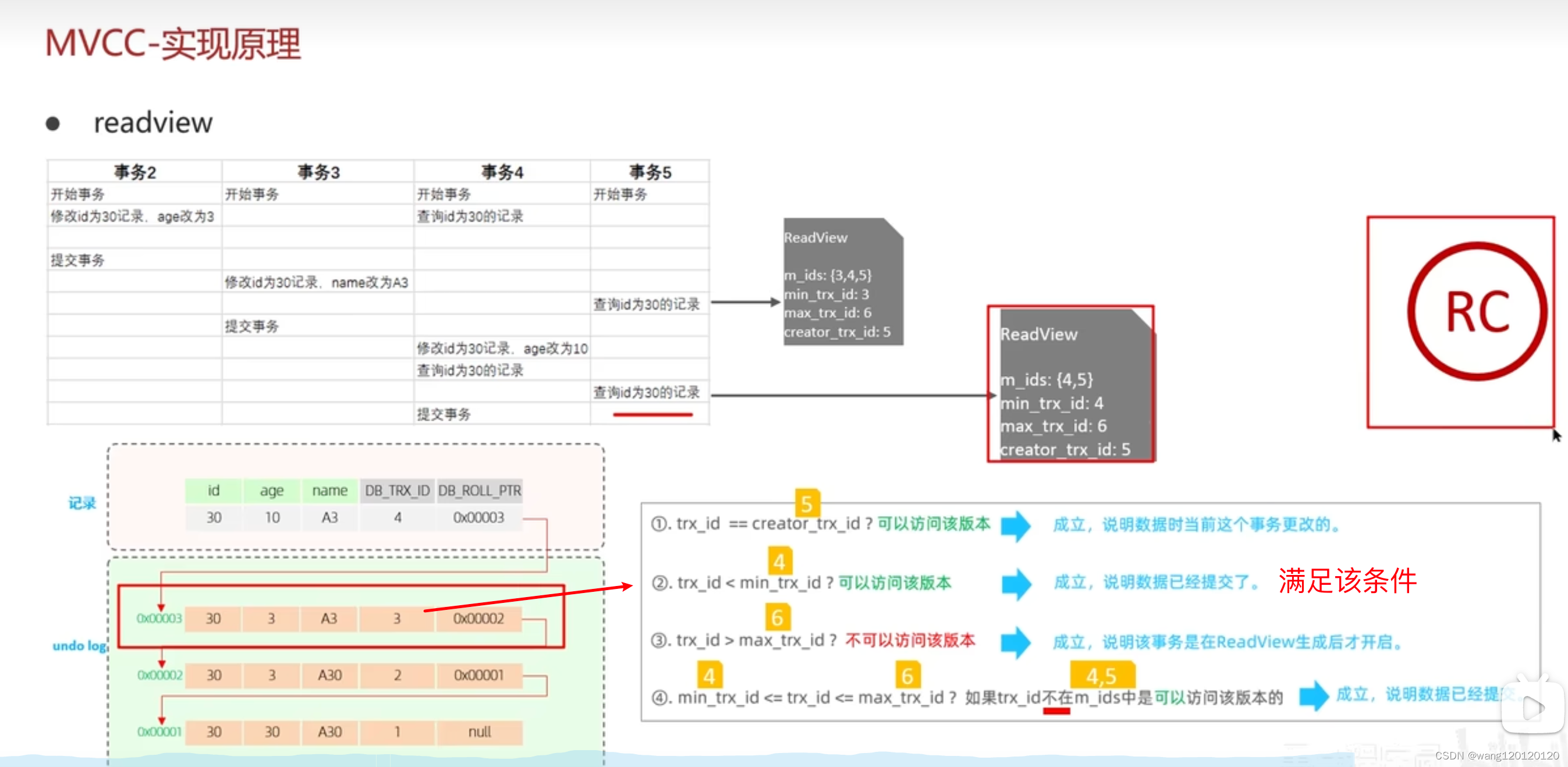
以上就是在RC级别下 read committed 是如何获取历史版本记录的
然后就是在RR级别下 repeatable read 读视图又是什么样子的?
在RR级别下,事务5的第一个读视图,根据上面的推导知道可以访问事务2的提交数据
后面的复用该ReadView,也就是说事务5查询到的都是事务2 提交时的数据,也就是读取到相同的数据
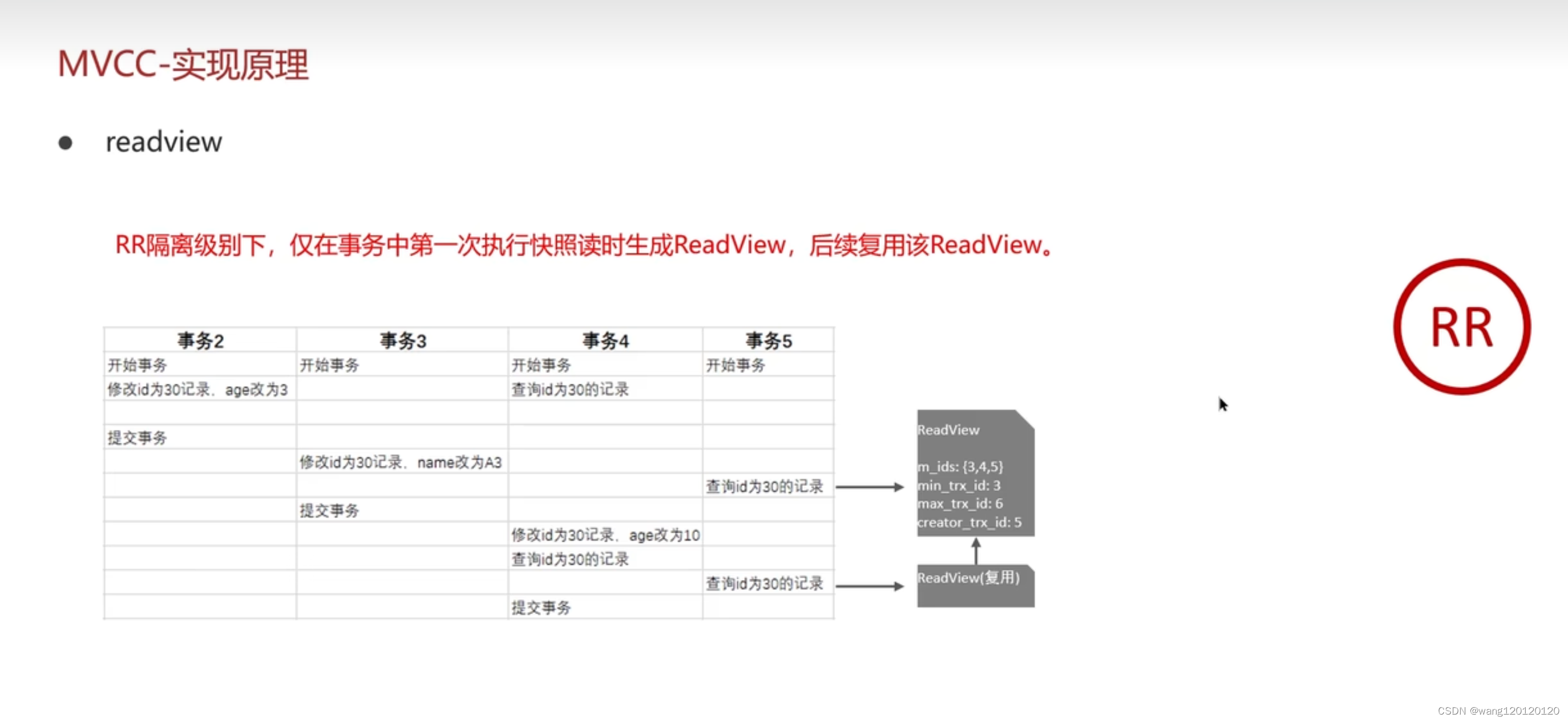
总结:


13、MySQL主从同步原理
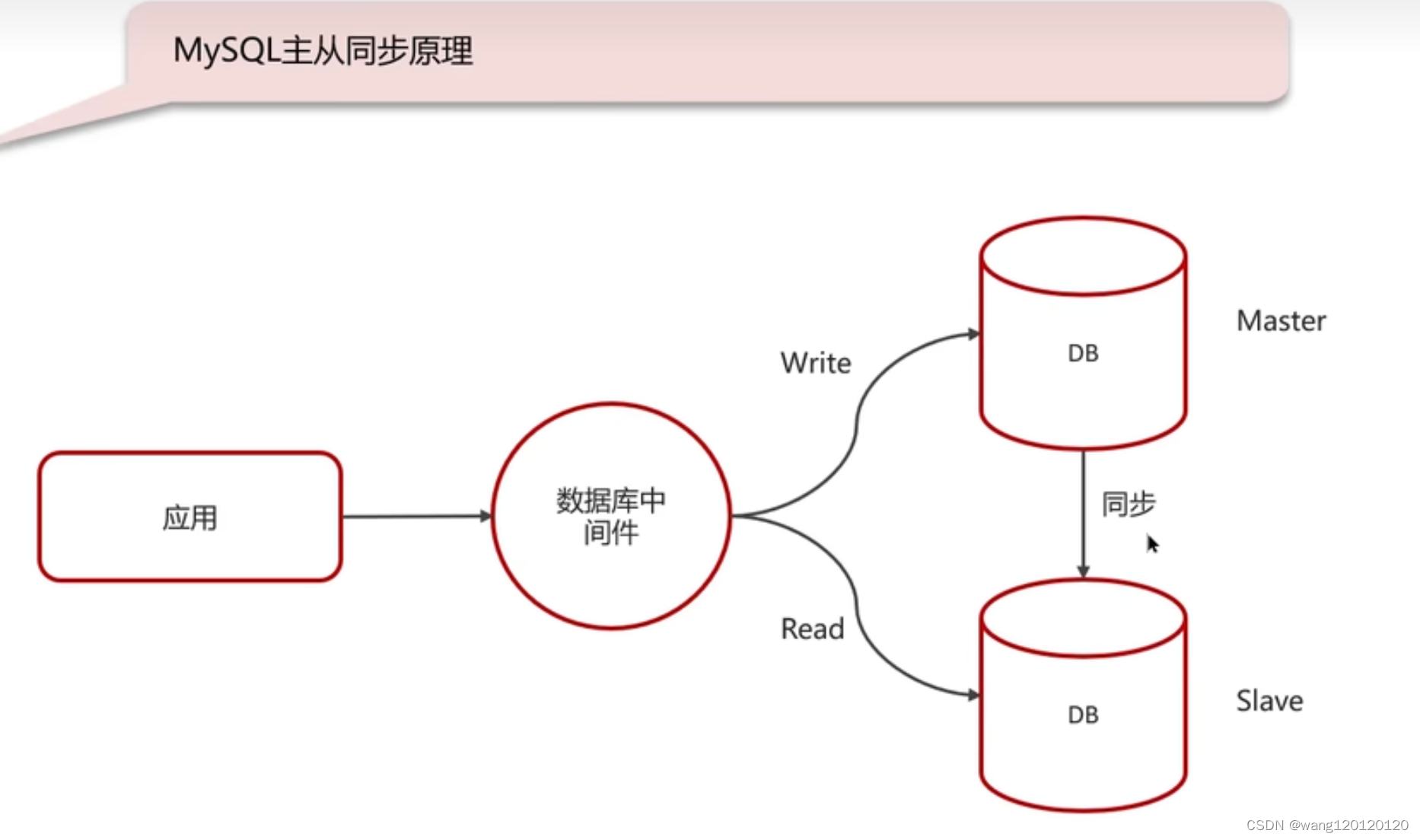
二进制日志 binlog
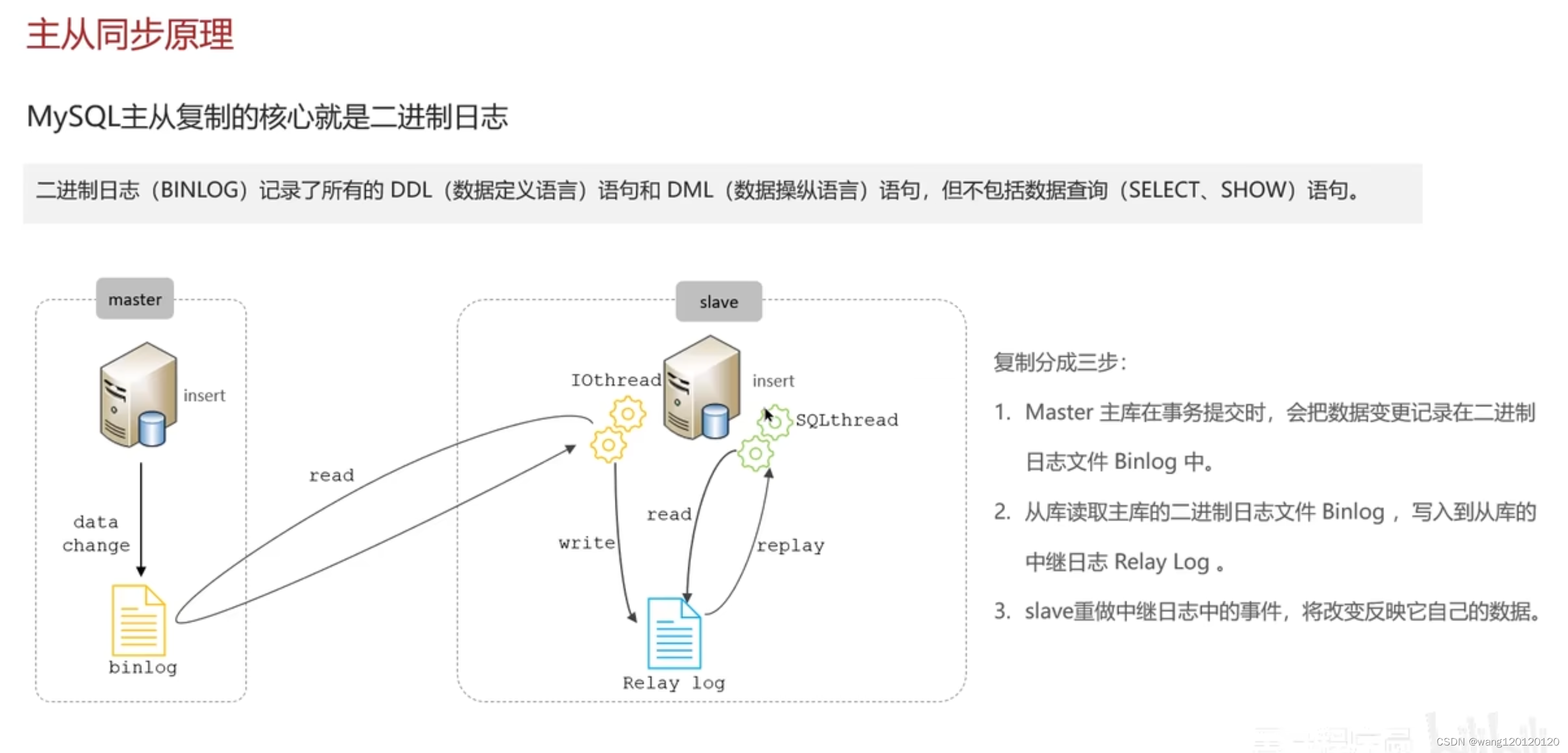
总结:


14、MySQL分库分表
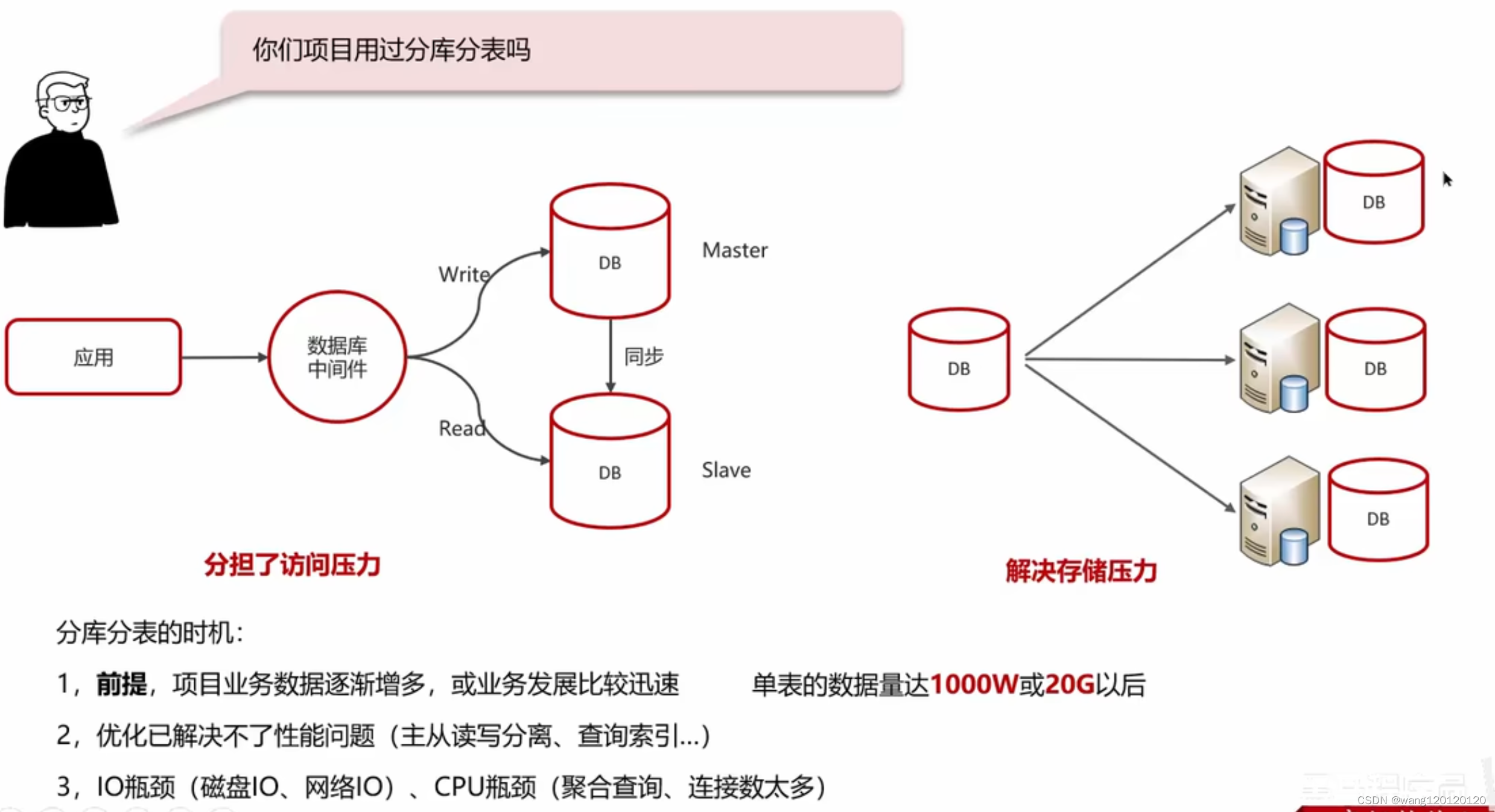
拆分策略:
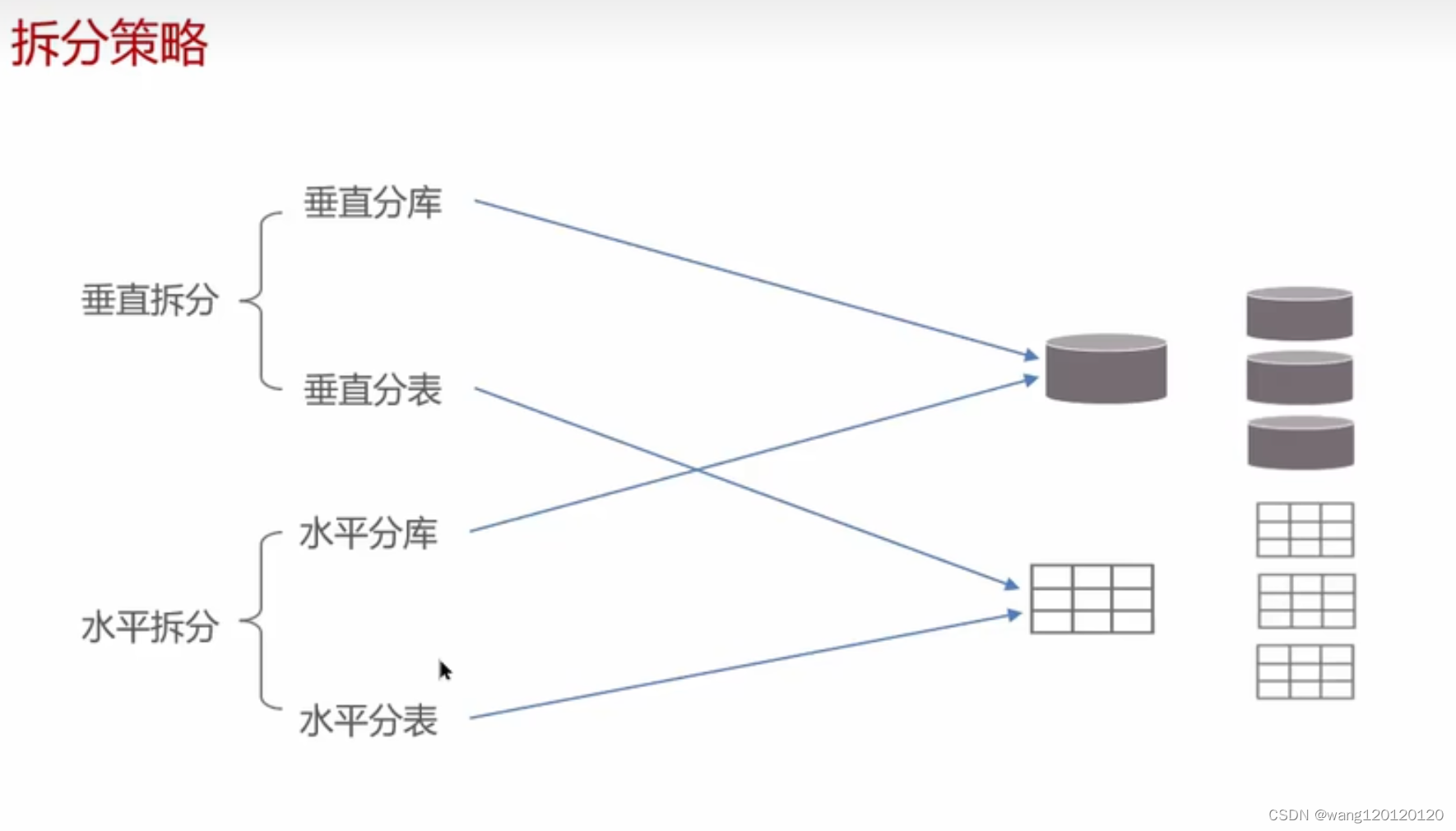
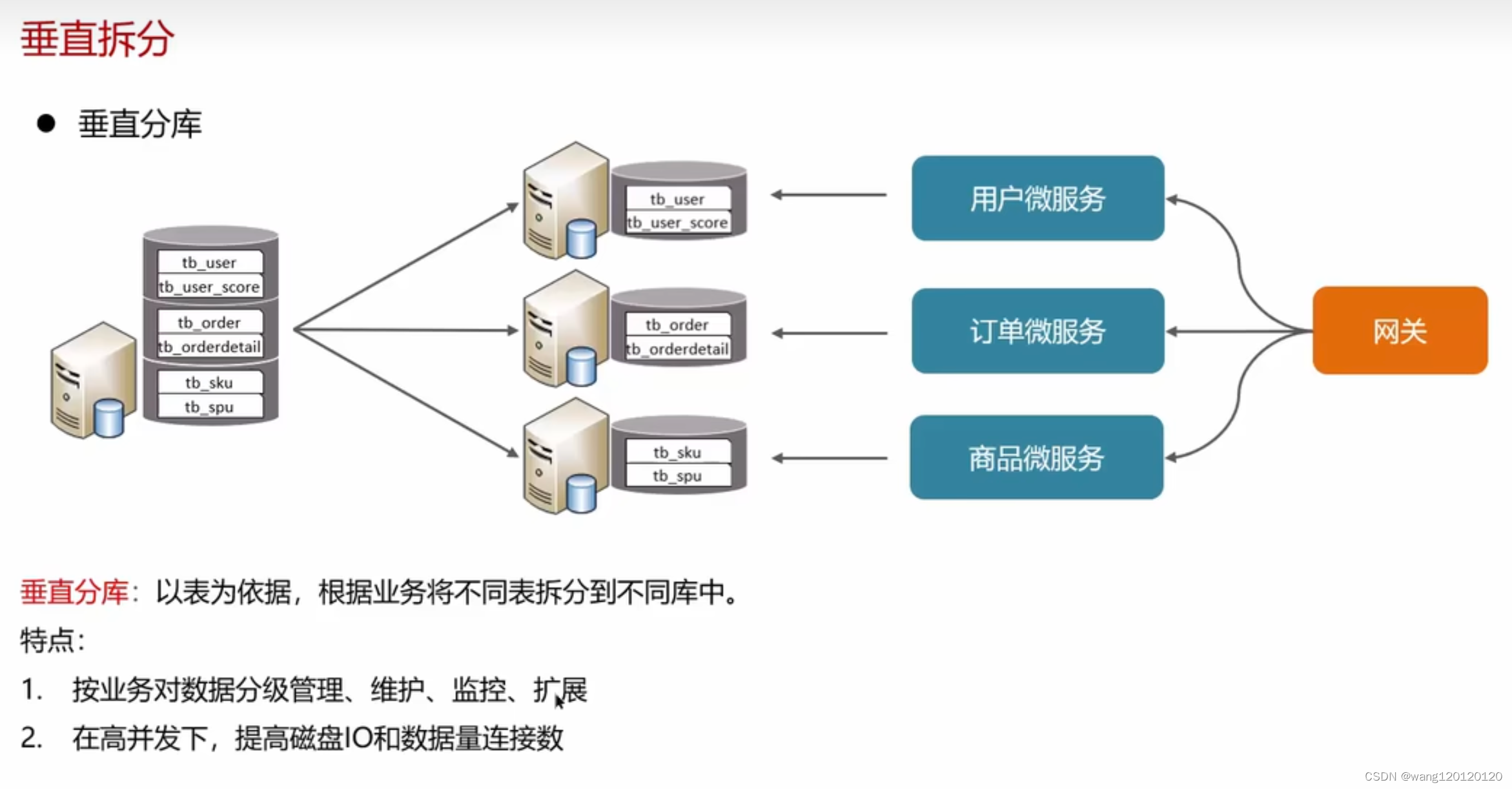
垂直分库:
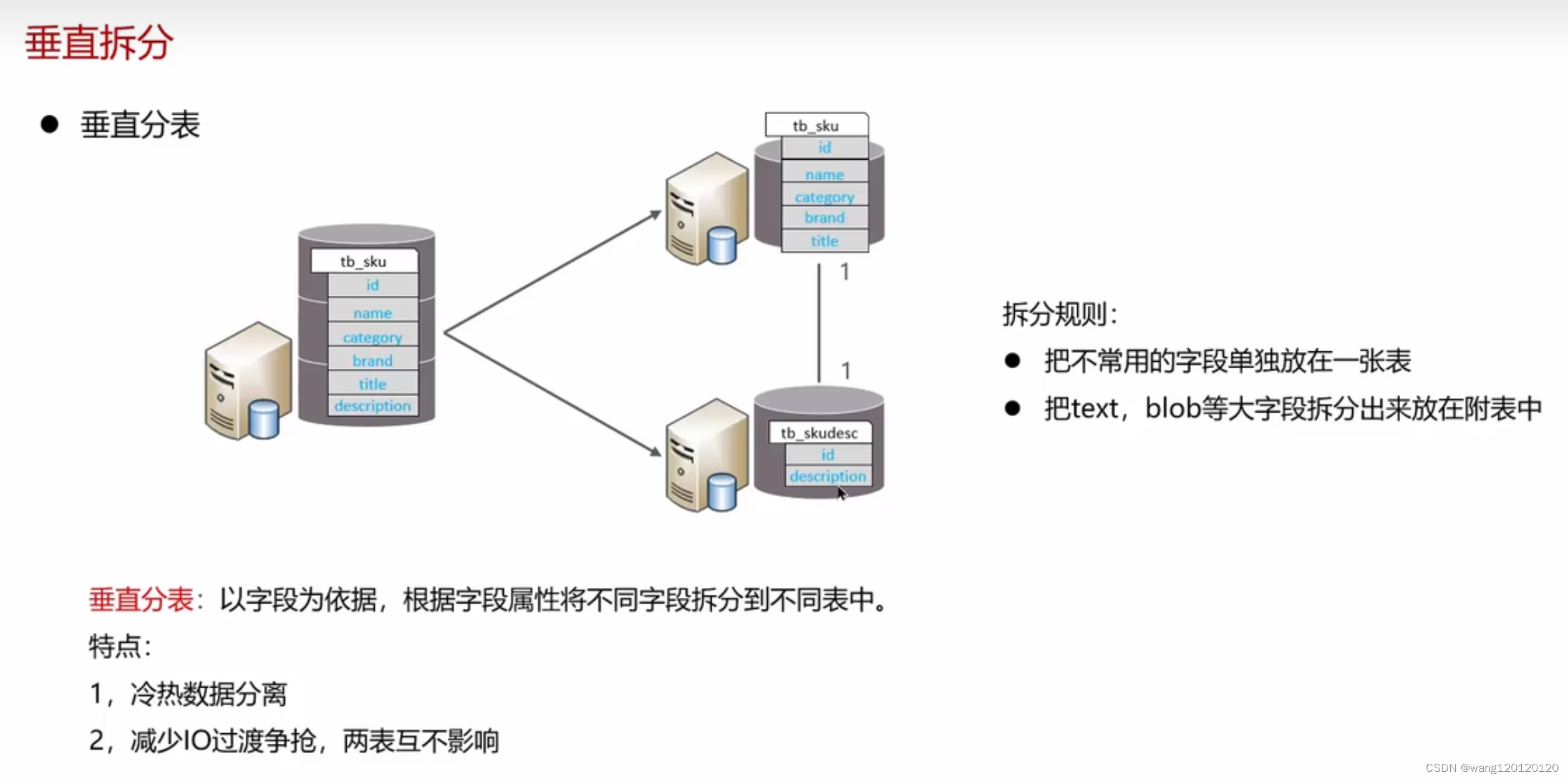
垂直分表:
分表也可能是在一个库里,并不一定是放到不同库
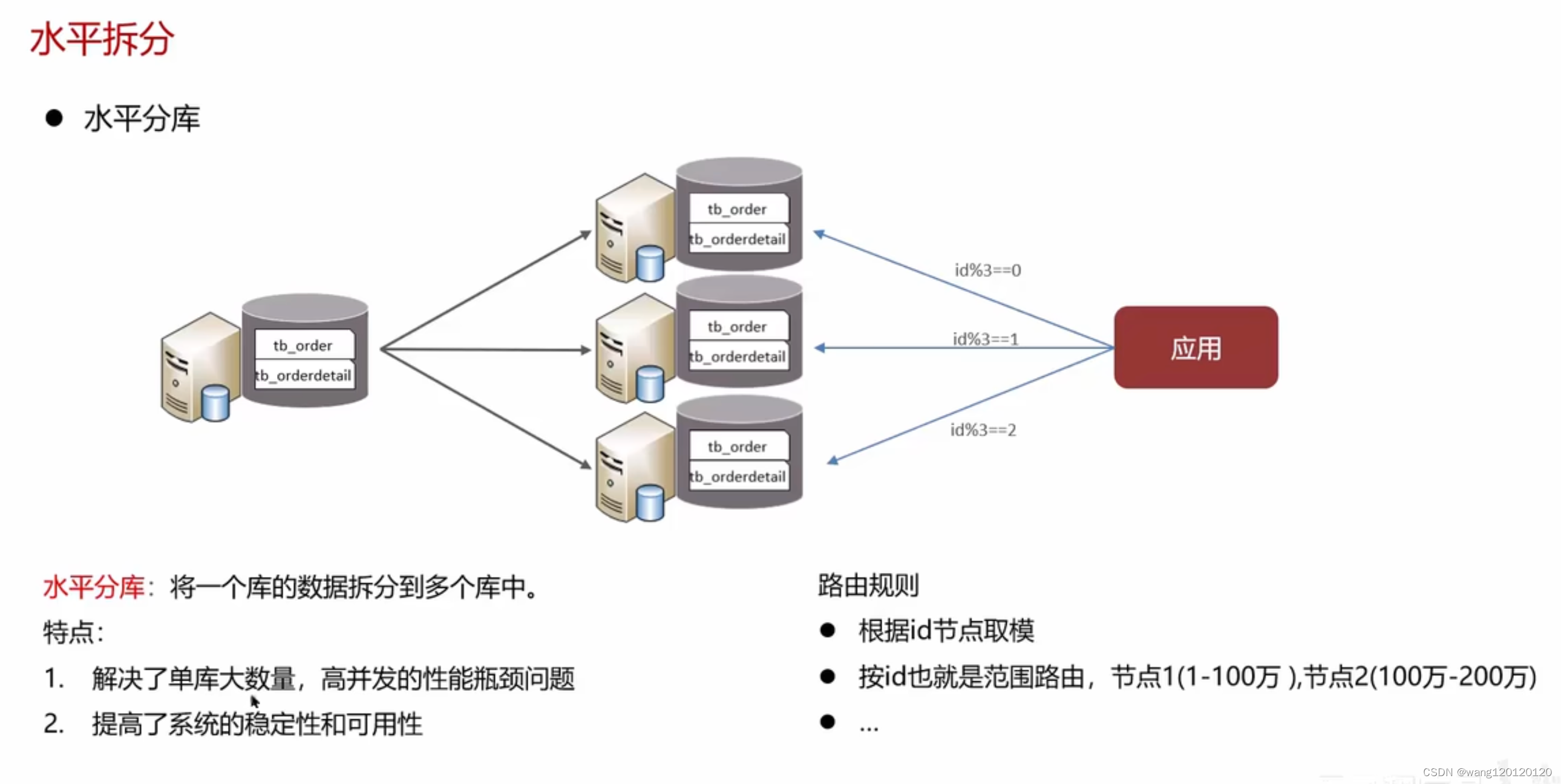
水平分库:
水平分表:
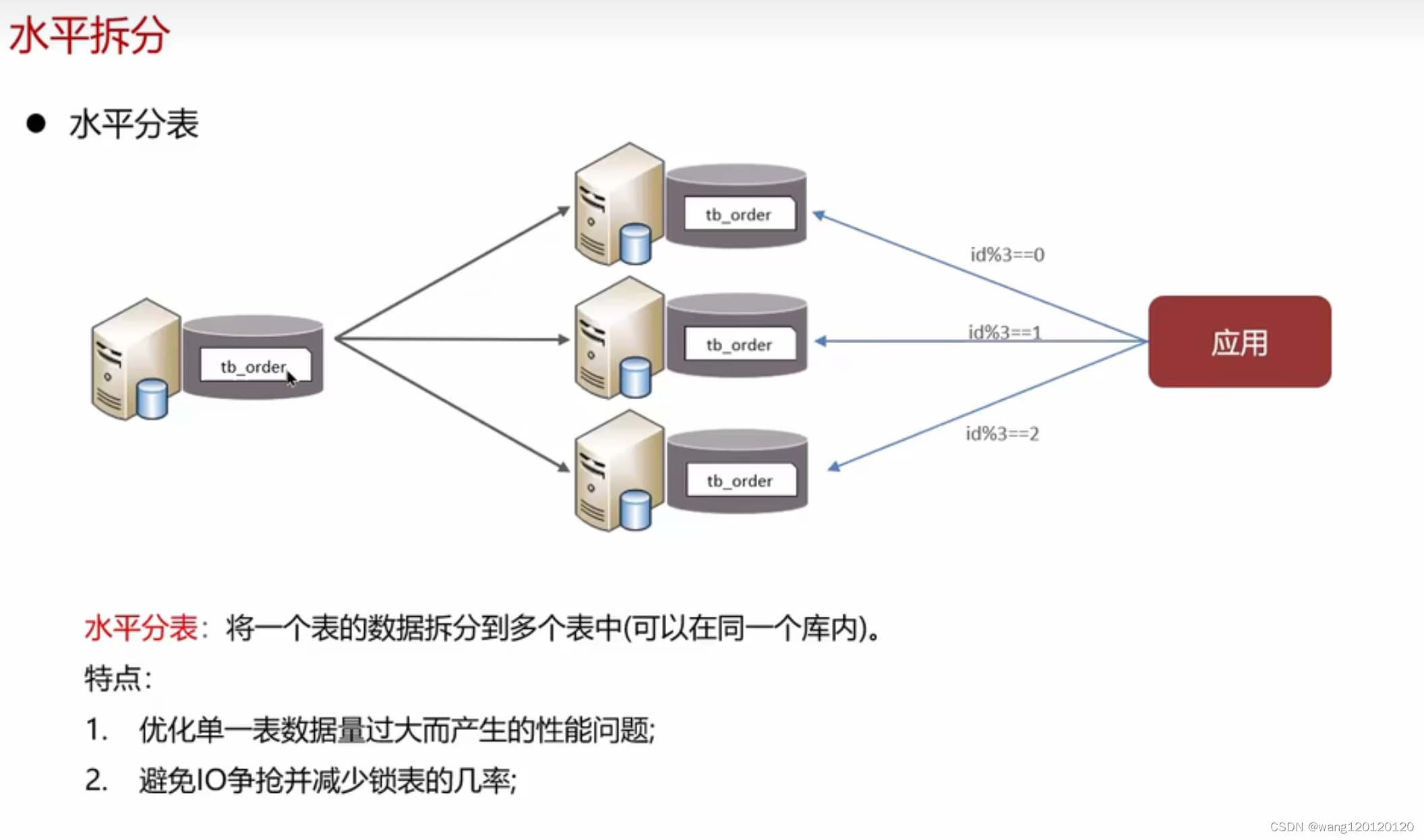
新的问题和技术:
分库分表中间件可以有效的帮助我们解决刚才提出的分库分表的问题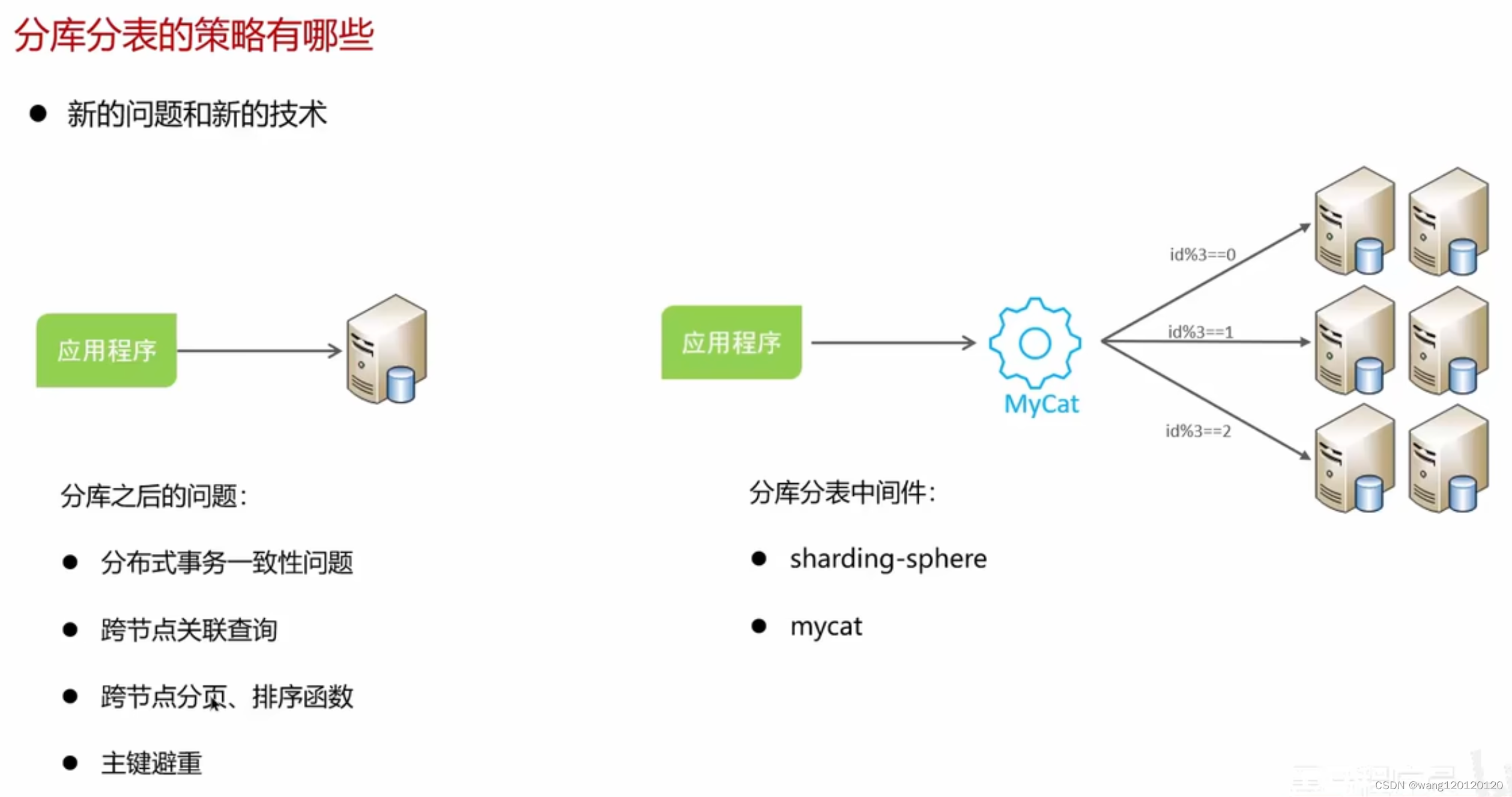
总结:

最后:
精通mysql


















 3万+
3万+



 到【灌水乐园】发言
到【灌水乐园】发言







