







 本文详细介绍了如何使用Heritrix进行断点续爬操作,包括创建Job、保存断点信息、恢复任务以及注意事项。对于大量网页爬取需求,此功能尤其实用。
本文详细介绍了如何使用Heritrix进行断点续爬操作,包括创建Job、保存断点信息、恢复任务以及注意事项。对于大量网页爬取需求,此功能尤其实用。
使用Heritrix爬取网页时,我们往往希望能够将一次爬取工作分次进行,在下次启动时继续上次没有完成的工作,特别面对需要爬取大量网页的需求时更是如此。Heritrix(我使用的是1.14.4版本)为我们提供了这种功能。
首先我们先建立一个Job:
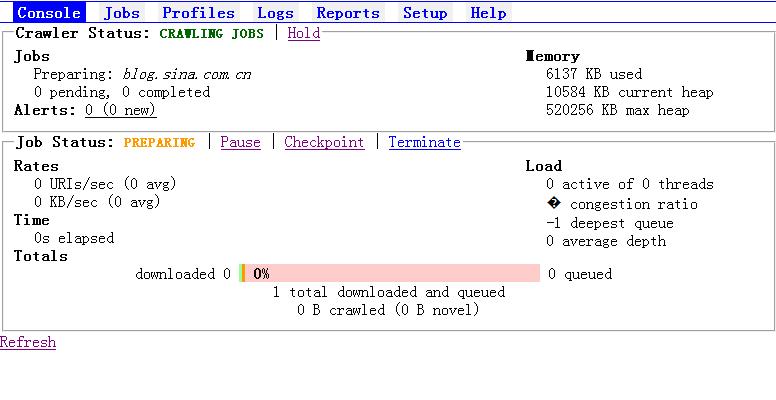
当需要对工作断点时,先点击Pause:
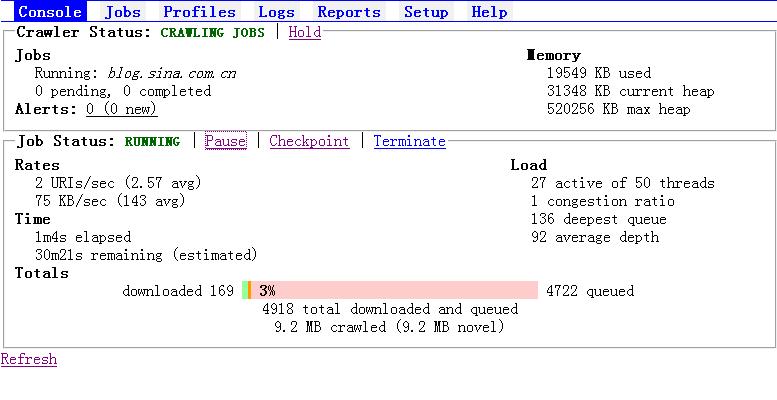
注意:点击Pause后先等一阵子,让正在作保存处理的URL全都完成了才能真正暂停(注意图中最下面的那个数值,点击Pause时是9.2M,而真正Pause后是12M)。
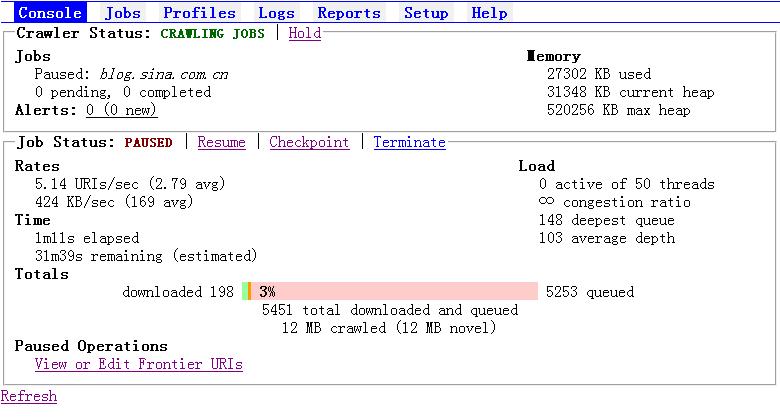
接下来我们就要保存断点信息了,只需点击Checkpoint。如果后台控制台显示
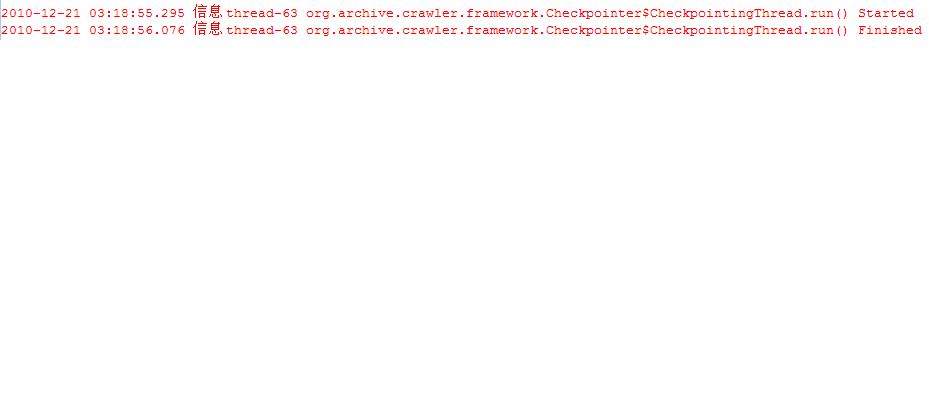
则表示断点信息已经保存起来了。接下来就可以点击Terminate终止任务,然后关掉Heritrix,或者关机。值得一提的是,往往我们点了Checkpoint之后,后台的控制台只显示第一句:
org.archive.crawler.framework.Checkpointer$CheckpointingThread.run() Started,第二句却没有弹出来。
这时候请给一点耐性,因为可能是你作业中要保存的备份信息比较多,所以Checkpoint的执行会比较慢,稍等一下就会弹出第二句了。
在下一次启动Heritrix时,我们需要让断点任务继续往下执行,我们在Heritrix的控制台页面上点击Jobs,然后选择Based on a recovery,可以看到上次断点的任务:
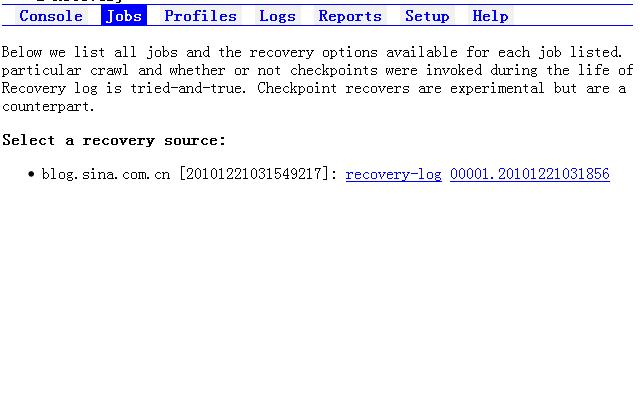
点击recovery-log后面的那个连接:00001.20101221031856,进入作业设置页面:
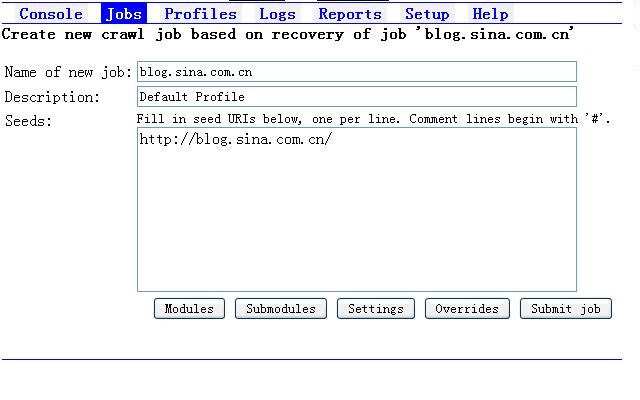
这时我们直接选择Submitjob,并点击Start,可以看到作业在上次的地方继续爬取:

最后提一下,每次给断点任务作恢复,都会在Heritrix的jobs目录下生成一个新的作业目录,该新目录就是用来存放断点恢复后爬取的网页。所以如果一个作业做了多次断点,就会在jobs目录下对应产生多个该作业的目录,这些目录里头存放爬到的网页可都各不相同的,所以马大哈的朋友可千万不要胡乱删除哦!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









