







一、背景
市面上有众多JSON工具,FastJSON GJson Jackson Simple-Json等等。
这些工具为什么会有性能差异?
分别适用于哪些场景?
如何优化自己项目的JSON性能?
什么是pull或push模式?
要回答这些问题,需要先搞明白 JSON原理——即如何进行序列化 反序列化的
二、JSON解析原理
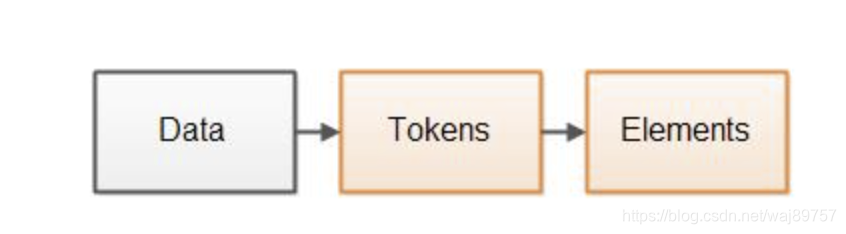

解析原理和任何文本解析模式类似,先普及几个专有名词。
Data:原始数据
Token:解析中间态
Element: 最终对象
解析流程:Data -> 分析器 -> tokens (令牌) -> 解析器 -> 对象
简单解析器:
https://github.com/jjenkov/parsers-in-java
下面是解析这段文本为Json的代码
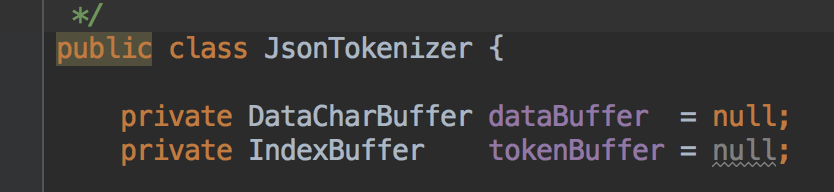

Data:DataCharBuffer 就是{xxxxx}
Token:IndexBuffer 是这个字符串的解释 也就是所有token 包括token的起始位置 类型 长度
Element:是对token的解析 最终转化成某个对象
i:tokenIndex
IndexBuffer.position[i] 该token在DataCharBuffer的游标
IndexBuffer.length[I] 该token在DataCharBuffer的长度
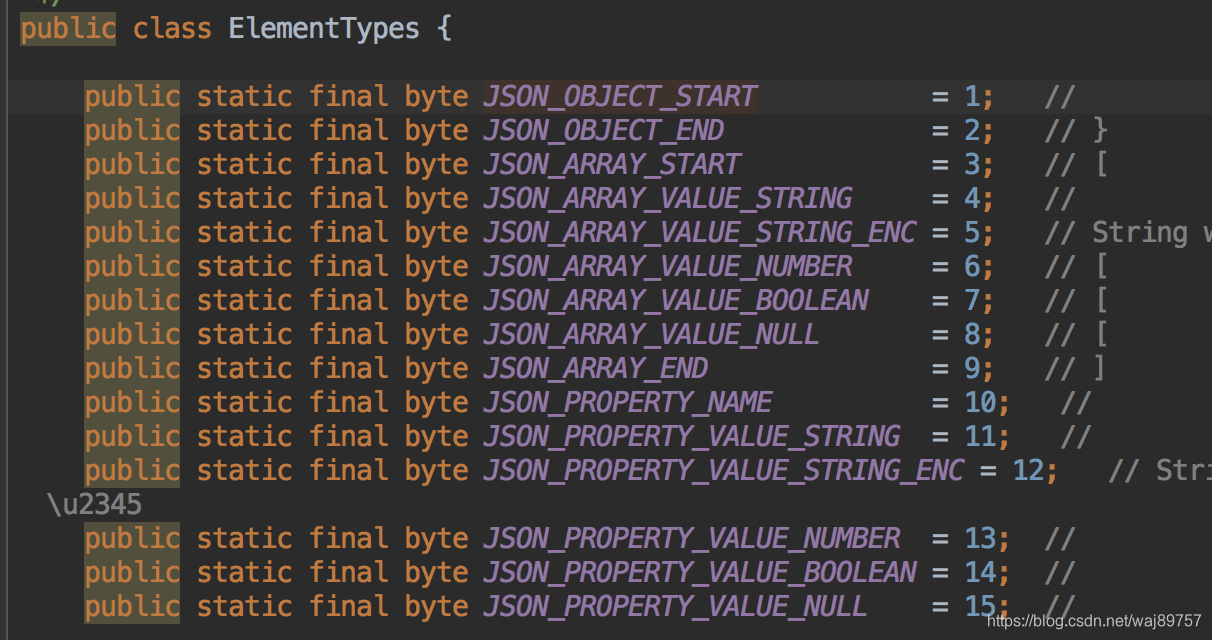
IndexBuffer.type[i] 该token类型
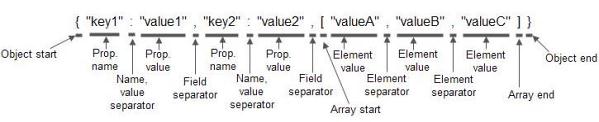
一段Json解析代码
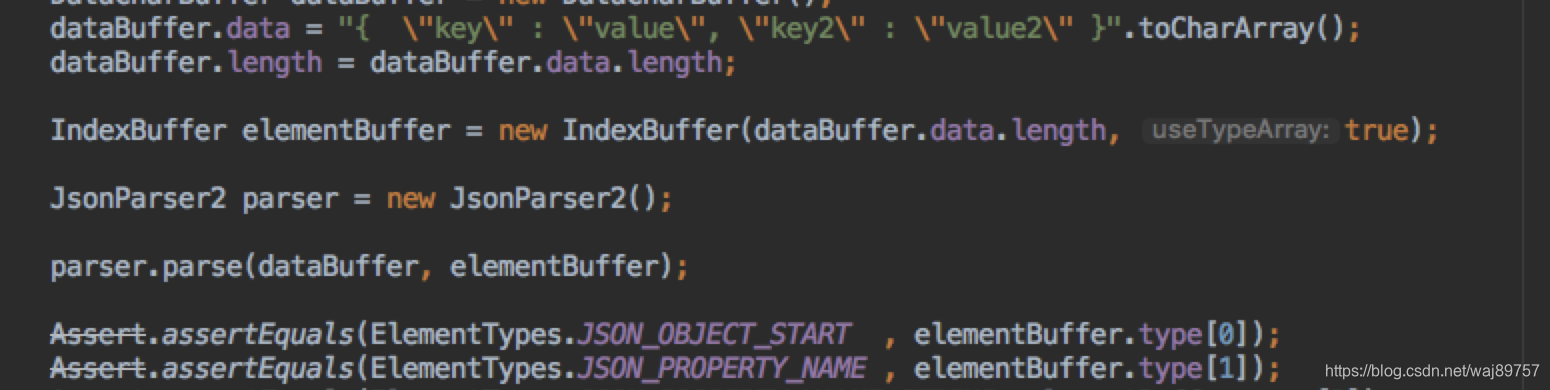
token分析的举例:
DataCharBuffer ["{","a",":","x","x","}"]
tokenIndex=0 是“{”
IndexBuffer.position[0] = 0
IndexBuffer.length[0] = 1
IndexBuffer.type[0] = JSON_OBJECT_START
token解释 ----> Element
也就是对DataCharBuffer 和IndexBuffer的遍历,来装配到对应的Object对象里,方法很多。
1.反射法 Gson
2.setter方式 JSONObject
小结:
上述说明了json字符串是如何解析的。
token分析: 一堆字符 通过遍历方式 生成一个对应的tokenIndex
token解释:字符串配合tokenIndex 来注入具体的element
性能差异基本就在如何分析以及如何解析成Element上
三、PULL模式和PUSH模式
一般的我们是先把JSON全部反序列化为对象在用,但有些场景只需要部分JSON字段。这时如果可以流式处理,会大幅提高性能。是否可以流失处理分成两种模式:
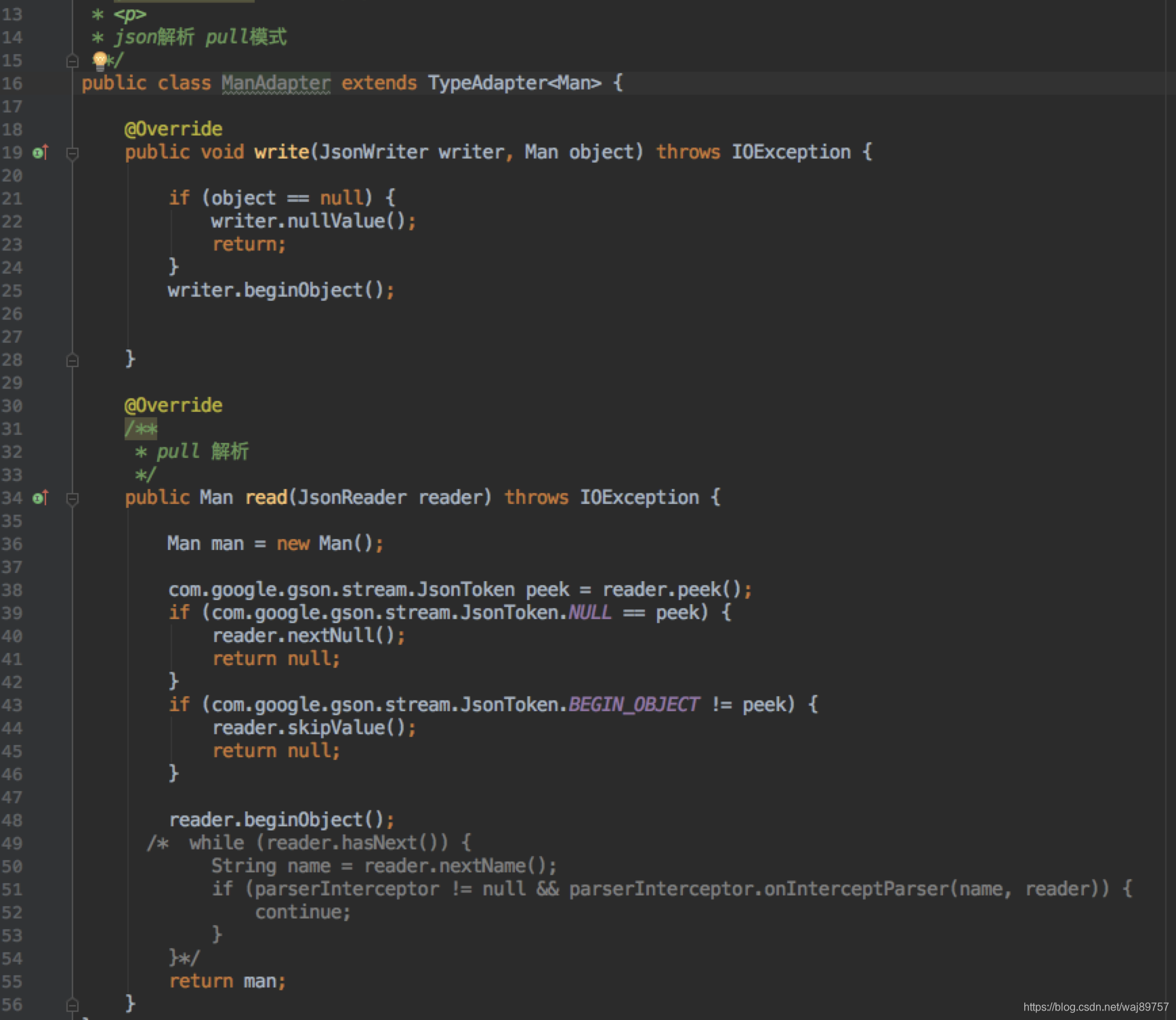
pull模式 用时解析。先整合成token,然后用时解析成对象
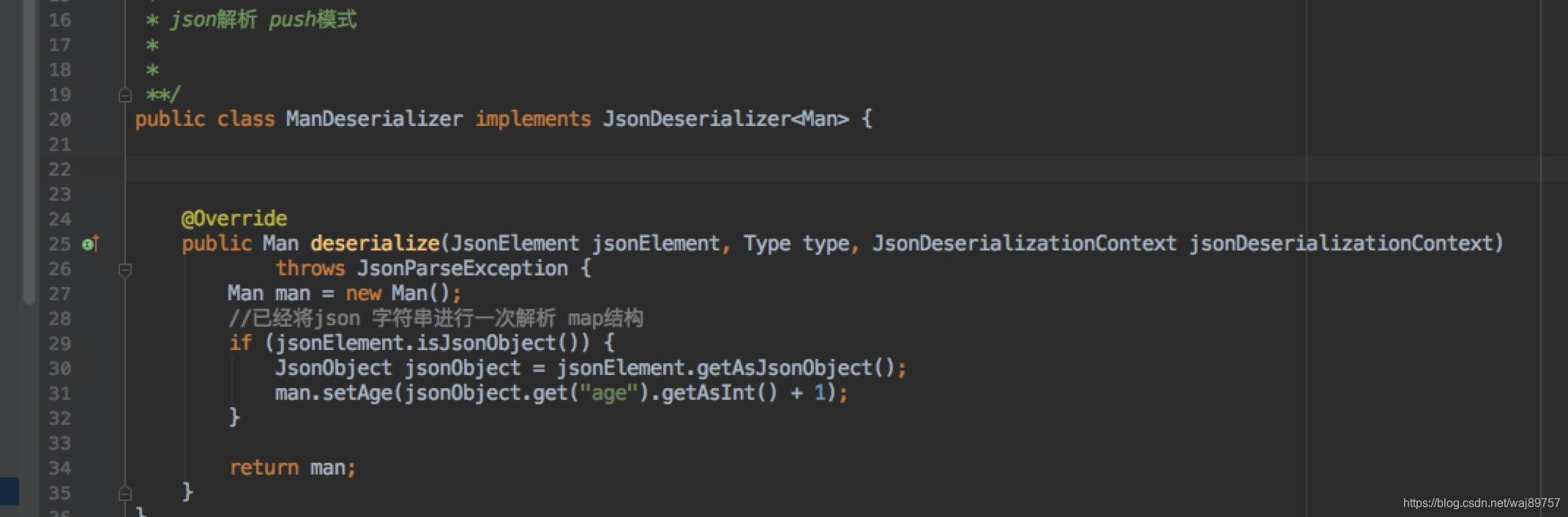
push模式 先把json字符串序列化为map 然后转对象
举例
Gson pull模式
Gson push模式





















 到【灌水乐园】发言
到【灌水乐园】发言







