 Java泛型与Map实现类详解
Java泛型与Map实现类详解





 本文介绍了Java中泛型的作用和使用方式,强调了泛型提供的安全性和便利性。接着详细讲解了Map接口的常见实现类HashMap、LinkedHashMap、HashTable和TreeMap,包括它们的特点、工作原理和使用注意事项。特别讨论了Java 7和8中HashMap的区别,以及如何在多线程环境中使用线程安全的Map。最后提到了Set与Map的关系,Collections工具类的功能,以及迭代器的正确使用方法。
本文介绍了Java中泛型的作用和使用方式,强调了泛型提供的安全性和便利性。接着详细讲解了Map接口的常见实现类HashMap、LinkedHashMap、HashTable和TreeMap,包括它们的特点、工作原理和使用注意事项。特别讨论了Java 7和8中HashMap的区别,以及如何在多线程环境中使用线程安全的Map。最后提到了Set与Map的关系,Collections工具类的功能,以及迭代器的正确使用方法。
泛型
-
为什么使用泛型
- 存在一些问题:
- 取集合元素的时候,取出来的是Object类型,需要使用的时候只能强转
- 添加元素的时候,缺乏规范,导致类型转换异常
- 设计原则:不要写重复的代码
- 存在一些问题:
-
泛型: 一种数据的约束 jdk 1.5之后出来的,提供编译时期的安全检查机制,给我们提供了自动的强制类型转换,安全
-
如何使用泛型?
-
常见字母
- T ——type
- K V —— key value
- E —— Element
-
使用
-
使用在类上
//一个类使用一个泛型 public class Student<T> { private T age; public T getAge() { return age; } public void setAge(T age) { this.age = age; } } //一个类使用多个泛型 public class Student<T,T2> { private T2 address; private T age;
-
-
-
接口的使用
-
public interface Usb <T>{ void use(T t); } -
方法泛型的使用功能
public static<T> void print(T t){
System.out.println(t);
}
泛型的继承
//继承多个泛型
public class Computer<T,T2> implements Usb<T,T2>{
@Override
public void use(T t) {
}
}
//继承单个班型 要指定另外一个的类型
public class Computer<T> implements Usb<T,String>{
@Override
public void use(T t,String s) {
}
}
- 泛型的总结(泛型是一个语法塘,底层还是使用的强制类型转换)
- 泛型的嵌套
Map
-
map概述。元素是成对出现的,每个元素是由 键(Key)与 值(value)两部分组成的,是双列集合。
- 里面的Key不能重复,重复就会被覆盖。
- value 是可以重复的。
-
map 最常用的实现类(HashTable(已被替代),HashMap, LinkedHashMap, Properties, ConcurrentHashMap)
-
map的常用方法:
//添加元素
V put(K key, V value);
//获取元素
V get(Object key);
//keySet方法 :获取key的集合
Set<K> keySet();
//获取键值对 对象
Set<Map.Entry<K, V>> entrySet();
HashMap
hashmap结构图:
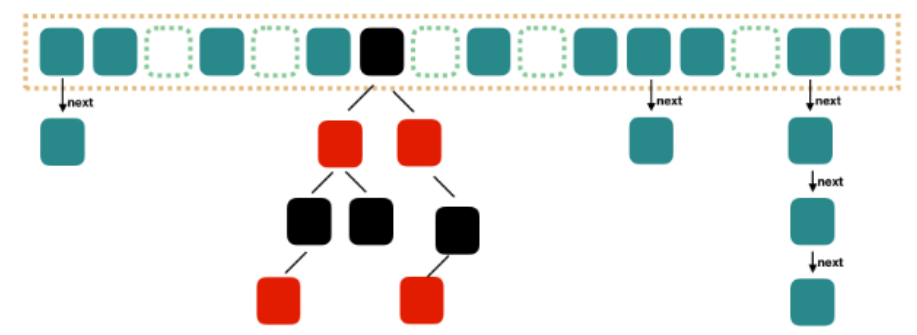
-
HashMap put方法的实现原理
//key 使用了hash 算法 hash(key) //如果 key 通过hash算法得到的值是一样的时候,需要用链表存储 next node,超过八个,红黑树 -
HashMap get方法的原理
Has(key)
如果不是树节点,直接循环遍历,next --> next
如果是树节点,直接去找书的孩子的算法
-
面试:java7 和 java8 HashMap的区别:树节点的引进,八个元素就会用红黑树存储
-
使用:
- key – String
- key --对象(重写equals方法以及hashcode)
- 当嵌套的时候
- 存,从内往外存
- 取,从外往内取
//原始的HashMap集合
Map<String,Map<String, List<Integer>>> map2 = new HashMap();
//第一层里面的 HashMap
Map<String,List<Integer>> m1=new HashMap();
//第二层里面的 List集合
List<Integer> list1 = new ArrayList();
list1.add(111);
list1.add(222);
list1.add(333);
m1.put("list1数据",list1);
//第二层里面的 List集合
List<Integer> list2 = new ArrayList();
list2.add(555);
list2.add(666);
list2.add(777);
m1.put("list2数据",list2);
map2.put("最外层的key",m1);
//遍历原始map集合
Set<Map.Entry<String, Map<String, List<Integer>>>> entries = map2.entrySet();
for (Map.Entry<String, Map<String, List<Integer>>> entry : entries) {
Map<String, List<Integer>> value = entry.getValue();
Set<Map.Entry<String, List<Integer>>> entries1 = value.entrySet();
for (Map.Entry<String, List<Integer>> stringListEntry : entries1) {
List<Integer> value1 = stringListEntry.getValue();
for (Integer integer : value1) {
System.out.println(integer);//111 222 333 555 666 777
}
}
}
LinkedHashMap
-
是按照添加顺序记录的,是HashMap的子类(Hash算法,链表)
public class Test { public static void main(String[] args) { LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); map.put("林青霞",23); map.put("张三丰",33); map.put("霍元甲",44); map.put("陈怎",24); Set<Map.Entry<String, Integer>> entries = map.entrySet(); for (Map.Entry<String, Integer> entry : entries) { Integer value = entry.getValue(); System.out.println(entry.getKey()+":"+value); // } System.out.println("-----------------------------------"); HashMap<String, Integer> hashMap = new HashMap(); hashMap.put("林青霞",23); hashMap.put("张三丰",33); hashMap.put("霍元甲",44); hashMap.put("陈怎",24); Set<Map.Entry<String, Integer>> entries1 = hashMap.entrySet(); for (Map.Entry<String, Integer> stringIntegerEntry : entries1) { Integer value = stringIntegerEntry.getValue(); System.out.println(stringIntegerEntry.getKey()+":"+value); } } // 林青霞:23 // 张三丰:33 // 霍元甲:44 // 陈怎:24 // ----------------------------------- // 林青霞:23 // 陈怎:24 // 张三丰:33 // 霍元甲:44 }
HashTable
- 使用 synchronized 就变成了线程安全的
- 使用HashMap替代
TreeMap集合
- 需求:String str = “dsaaffwaegadafafafehwje”; 按照字母顺序进行排序
public static void main(String[] args) {
String str = "dsaaffwaegadafafafehwje";
char[] chars = str.toCharArray();
Map<Character,Integer> map = new TreeMap<>();
for (char aChar : chars) {
//判断集合里面是否存在元素
if(map.containsKey(aChar)){
Integer count = map.get(aChar);
map.put(aChar,++count);
}else {
//没存在,就存一个键值对进去
map.put(aChar,1);
}
}
System.out.println(map);
//{a=7, d=2, e=3, f=5, g=1, h=1, j=1, s=1, w=2}
}
- TreeMap可以实现自动排序,底层使用红黑树算法
- 实现排序: key通过 comparator 接口下面的compare(k1,k2)算法排序
Map的总结:
- HashMap是最常使用的
Set 和Map之间的关系
-
HashSet 的底层使用的 HashMap
- HashSet里面存储用的HashMap,并且里面的value是一个空对象(不会开辟新空间)
-
Set的底层基本都是使用,Map实现的
| Set | Map | 算法 |
|---|---|---|
| HashSet | HashMap | 哈希表 |
| TreeSet | TreeMap | 红黑树 |
| LinkedHashSet | LinkedHashMap | 链表+哈希表 |
- Set里面的Map的Value永远都是一块内存空间,不占内存
private static final Object PRESENT = new Object();
Collections工具类
- 获取线程安全的ArrayList-----(synchronizedList)
List<Object> list = Collections.synchronizedList(new ArrayList<>());
-
获取线程安全的HashMap
Map<Object, Object> map1 = Collections.synchronizedMap(new HashMap<>()); -
其他常用的方法
//空集合创建 Collections.EMPTY_LIST; Collections.EMPTY_MAP; Collections.EMPTY_Set; -
Collections 和 Collection 的区别
- Collections 封装了List Map Set的操作工具方法
- Collection
迭代器的使用讲解
-
需求:新建一个list,并且添加abcde几个元素,删除 c 元素。
-
产生的问题:
- ConcurrentModificationException 并发的修改异常
-
如何才能够删除集合里面的元素还不会报错
-
如何使用迭代器?
-
获取迭代器对象 Iterator iterator = list.iterator();
public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("A"); list.add("B"); list.add("C"); list.add("D"); list.add("E"); Iterator<String> iterator = list.iterator(); while (iterator.hasNext()){ String next = iterator.next(); // System.out.println(next);迭代一次,值就不见了 if ("C".equals(next)){ iterator.remove(); } } for (String s : list) { System.out.println(s); } }
-
g> iterator = list.iterator();
while (iterator.hasNext()){
String next = iterator.next();
// System.out.println(next);迭代一次,值就不见了
if (“C”.equals(next)){
iterator.remove();
}
}
for (String s : list) {
System.out.println(s);
}
}
```

















 8414
8414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









