



1.配置主机名和IP地址映射
修改主机名(三个节点)
hostnamectl set-hostname hadoop1
hostnamectl set-hostname hadoop2
hostnamectl set-hostname hadoop3
设置ip地址(三个节点)
nmcli connection modify ens33 ipv4.address 192.168.121.160
nmcli connection down ens33
nmcli connection up ens33
nmcli connection modify ens33 ipv4.address 192.168.121.161
nmcli connection down ens33
nmcli connection up ens33
nmcli connection modify ens33 ipv4.address 192.168.121.162
nmcli connection down ens33
nmcli connection up ens33
配置主机名与IP映射(三个节点)
vim /etc/hosts
添加3行
192.168.121.160 hadoop1
192.168.121.161 hadoop2
192.168.121.162 hadoop3
2.配置免密登录,让主节点(hadoop1)可以免密登录其他节点
ssh-keygen #生成密钥对(hadoop1)
ssh-copy-id hadoop1 #拷贝公钥到hadoop1,2,3
ssh-copy-id hadoop2
ssh-copy-id hadoop3
3.配置Java环境(三个节点)
#解压jdk到当前目录
tar -zxf jdk-8u202-linux-x64.tar.gz
#编辑/etc/profile文件,添加 2行
export JAVA_HOME=/opt/software/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
java -version #查看java版本信息如下

将hadoop1的java目录和profile文件拷贝到hadoop2和hadoop3对应的位置
scp -r /opt/software/jdk1.8.0_202 hadoop2:/opt/software/
scp -r /opt/software/jdk1.8.0_202 hadoop3:/opt/software/
scp /etc/profile hadoop2:/etc
scp /etc/profile hadoop3:/etc
source /etc/profile # (hadoop2,hadoop3上执行),现在hadoop1,2,3上都具有java环境了
4.hadoop伪分布式模式部署
1.解压hadoop
tar -zxf hadoop-3.3.0.tar.gz
2.配置环境变量
vim /etc/profile
export HADOOP_HOME=/opt/software/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
运行命令如下:
3.编辑hadoop配置文件
hadoop-env.sh 添加:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/opt/software/jdk1.8.0_202
core-site.xml 添加:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/tmp</value>
</property>
4.格式化名称节点
hdfs namenode -format
5.启动hadoop集群
start-all.sh
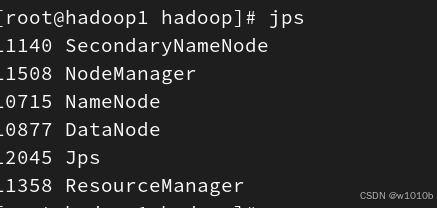
进程信息如下代表伪分布式集群启动成功

















 2848
2848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









