







 本文介绍如何使用IntelliJ IDEA快速搭建Spark开发环境,包括安装IDEA和Scala插件、创建Spark项目、编写示例代码及打包程序。并提供部署程序包的方法。
本文介绍如何使用IntelliJ IDEA快速搭建Spark开发环境,包括安装IDEA和Scala插件、创建Spark项目、编写示例代码及打包程序。并提供部署程序包的方法。
本篇是
Spark1.0.0 开发环境快速搭建
中关于客户端IDE部分的内容,将具体描述:
至于如何运行程序包,请参见 应用程序部署工具spark-submit 。
注意 ,客户端和虚拟集群中hadoop、spark、scala的安装目录是一致的,这样开发的spark应用程序的时候不需要打包spark开发包和scala的库文件,减少不必要的网络IO和磁盘IO。当然也可以不一样,不过在使用部署工具spark-submit的时候需要参数指明classpath。
1:IDEA的安装
官网jetbrains.com下载IntelliJ IDEA,有Community Editions 和& Ultimate Editions,前者免费,用户可以选择合适的版本使用。
根据安装指导安装IDEA后,需要安装scala插件,有两种途径可以安装scala插件:
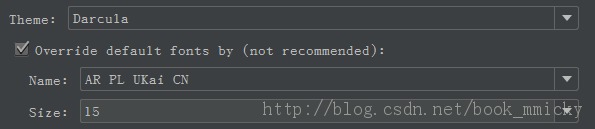
如果你想使用那种酷酷的黑底界面,在File -> Settings -> Appearance -> Theme选择Darcula,同时需要修改默认字体,不然菜单中的中文字体不能正常显示。
2:建立Spark应用程序
下面讲述如何建立一个Spark项目week2( ,正在录制视频),该项目包含3个object:
,正在录制视频),该项目包含3个object:
A:建立新项目

B:编写代码
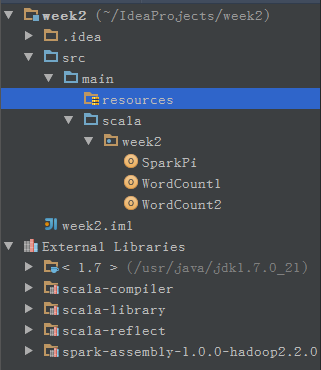
在源代码scala目录下创建1个名为week2的package,并增加3个object(SparkPi、WordCoun1、WordCount2):
C:生成程序包
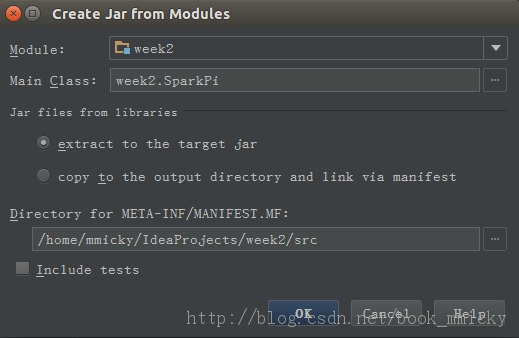
生成程序包之前要先建立一个artifacts,File -> Project Structure -> Artifacts -> + -> Jars -> From moudles with dependencies,然后随便选一个class作为主class。
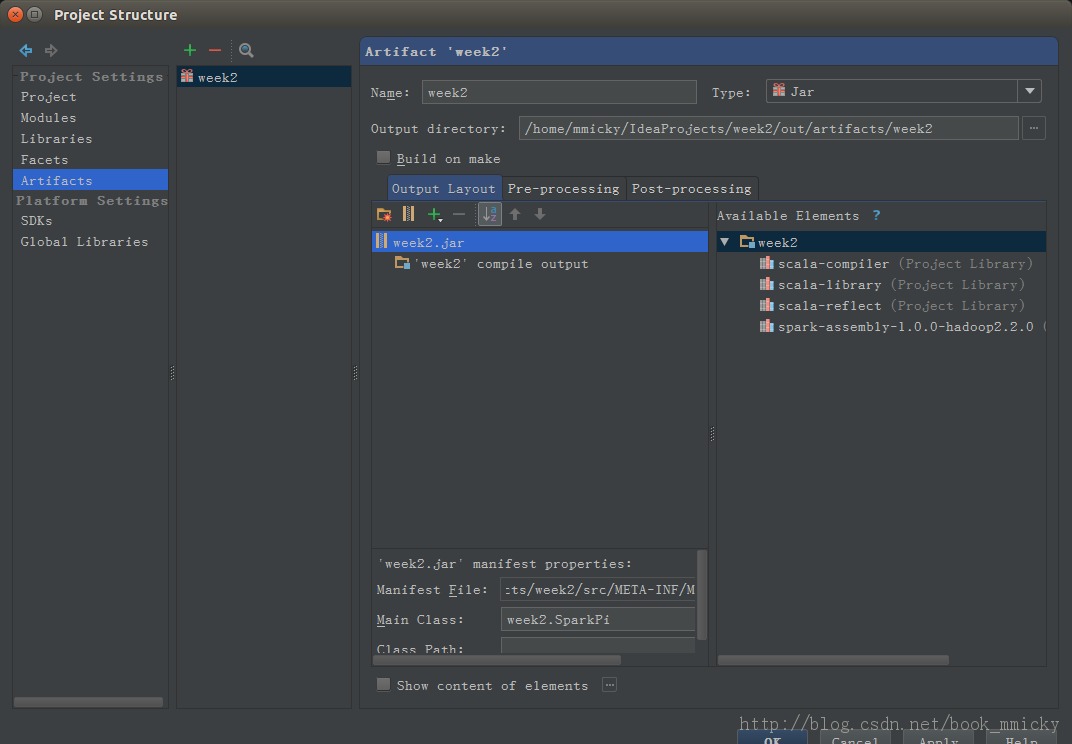
按OK后,对artifacts进行配置,修改Name为week2,删除Output Layout中week2.jar中的几个依赖包,只剩week2项目本身。
按OK后, Build -> Build Artifacts -> week2 -> rebuild进行打包,经过编译后,程序包放置在out/artifacts/week2目录下,文件名为week2.jar。
3:Spark应用程序部署
将生成的程序包week2.jar复制到spark安装目录下,切换到用户hadoop,然后切换到/app/hadoop/spark100目录,进行程序包的部署。具体的部署参见 应用程序部署工具spark-submit 。
- 如何安装scala开发插件
- 如何创建项目和配置项目属性
- 如何编写源代码
- 如何将生成的程序包
至于如何运行程序包,请参见 应用程序部署工具spark-submit 。
注意 ,客户端和虚拟集群中hadoop、spark、scala的安装目录是一致的,这样开发的spark应用程序的时候不需要打包spark开发包和scala的库文件,减少不必要的网络IO和磁盘IO。当然也可以不一样,不过在使用部署工具spark-submit的时候需要参数指明classpath。
1:IDEA的安装
官网jetbrains.com下载IntelliJ IDEA,有Community Editions 和& Ultimate Editions,前者免费,用户可以选择合适的版本使用。
根据安装指导安装IDEA后,需要安装scala插件,有两种途径可以安装scala插件:
- 启动IDEA -> Welcome to IntelliJ IDEA -> Configure -> Plugins -> Install JetBrains plugin... -> 找到scala后安装。
- 启动IDEA -> Welcome to IntelliJ IDEA -> Open Project -> File -> Settings -> plugins -> Install JetBrains plugin... -> 找到scala后安装。
如果你想使用那种酷酷的黑底界面,在File -> Settings -> Appearance -> Theme选择Darcula,同时需要修改默认字体,不然菜单中的中文字体不能正常显示。
2:建立Spark应用程序
下面讲述如何建立一个Spark项目week2(
- 取自spark examples源码中的SparkPi
- 计词程序WordCount1
- 计词排序程序WordCount2
A:建立新项目
- 创建名为dataguru的project:启动IDEA -> Welcome to IntelliJ IDEA -> Create New Project -> Scala -> Non-SBT -> 创建一个名为week2的project(注意这里选择自己安装的JDK和scala编译器) -> Finish。
- 设置week2的project structure
- 增加源码目录:File -> Project Structure -> Medules -> week2,给week2创建源代码目录和资源目录,注意用上面的按钮标注新增加的目录的用途。
- 增加源码目录:File -> Project Structure -> Medules -> week2,给week2创建源代码目录和资源目录,注意用上面的按钮标注新增加的目录的用途。
- 增加开发包:File -> Project Structure -> Libraries -> + -> java -> 选择
- /app/hadoop/spark100/lib/spark-assembly-1.0.0-hadoop2.2.0.jar
- /app/scala2104/lib/scala-library.jar可能会提示错误,可以根据fix提示进行处理
B:编写代码
在源代码scala目录下创建1个名为week2的package,并增加3个object(SparkPi、WordCoun1、WordCount2):
- SparkPi代码
- WordCount1代码
- WordCount2代码
C:生成程序包
生成程序包之前要先建立一个artifacts,File -> Project Structure -> Artifacts -> + -> Jars -> From moudles with dependencies,然后随便选一个class作为主class。
按OK后,对artifacts进行配置,修改Name为week2,删除Output Layout中week2.jar中的几个依赖包,只剩week2项目本身。
按OK后, Build -> Build Artifacts -> week2 -> rebuild进行打包,经过编译后,程序包放置在out/artifacts/week2目录下,文件名为week2.jar。
3:Spark应用程序部署
将生成的程序包week2.jar复制到spark安装目录下,切换到用户hadoop,然后切换到/app/hadoop/spark100目录,进行程序包的部署。具体的部署参见 应用程序部署工具spark-submit 。

















 6057
6057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









