




 本文详细介绍SPSS软件中数据排序、重复个案识别、数据文件拆分、变量计算及个案选择的操作方法,帮助读者掌握高效的数据处理技能。
本文详细介绍SPSS软件中数据排序、重复个案识别、数据文件拆分、变量计算及个案选择的操作方法,帮助读者掌握高效的数据处理技能。
字数:608 ,基础级别,难度一个星,建议阅读时长60秒:
写在前面:接下来的几篇都是与spss操作相关的内容,将自己曾经有困惑或者使用频率较高的内容介绍出来,最后一篇将会是Airbnb相关实战分析 ~~我也不知道能不能坚持到最后一篇~~
只是个小白,所以..欢迎大家纠错~
目录
数据排序的基本操作
1) 数据(Data)--个案排序(Sort Cases);
2) 右键按一次圈起来的区域。
值得注意的是:数据排序以后,原有数据排列次序被打乱,因此为了保留原有数据的原始排列,通常会在第一列加入编号列。
重复个案的识别
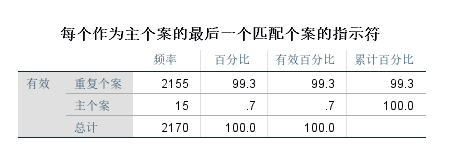
操作:数据(Data)-标识重复个案(Identify Duplicate Cases)
作用:通常会和删除重复个案连用;避免可能由重复录入引起的统计错误
数据文件的拆分
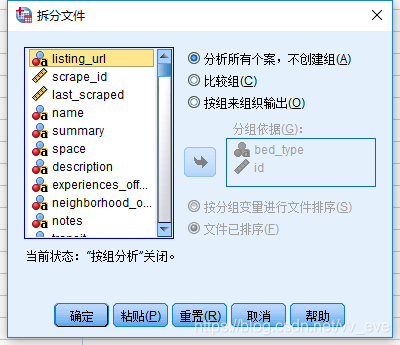
操作:数据-拆分文件(Split Files)
作用:分组统计,通常和其他方法(如描述统计)连用
异常:命令最多只能使用8个拆分文件变量。请注意,长字符串变量将算作多个拆分文件变量。

处理方法:修改该变量的宽度
结合使用例子:
恢复原状:
变量计算
操作:转换(Transform)-计算变量(Compute Variable)
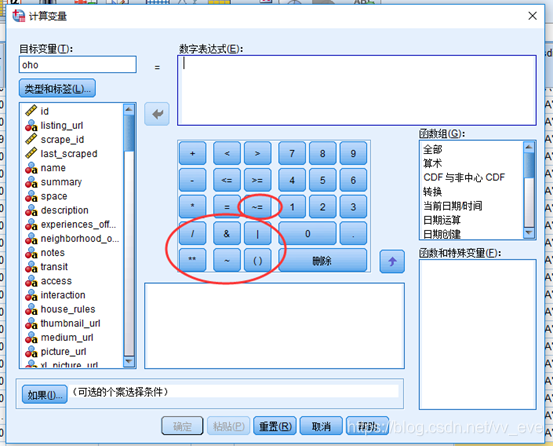
| 运算符 | 等价形式 | 含义 |
| ** | 乘方 | |
| ~=(关系运算符) | NT | 不等于 |
| & | AND | 与运算 |
| | | OR | 或运算 |
| ~ | NOT | 非运算 |
选择个案
操作:数据-选择个案(Select Cases)
原因:由于调研和实验得到的数据量一般都很大,根据抽样的方法选取一部分变量进行分析;数据处理之前需对数据进行筛选,筛选出有问题或无关紧要的额数据。
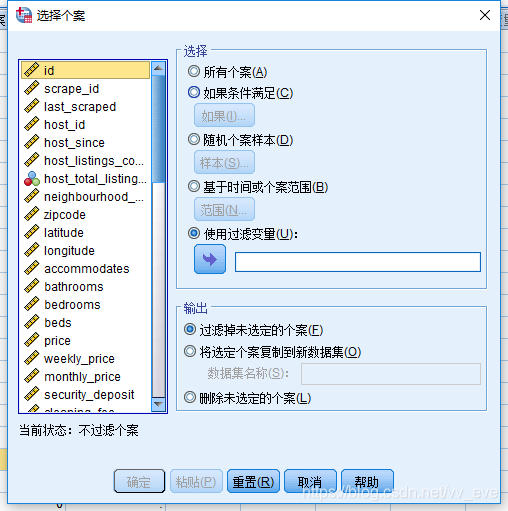
1)所有个案(All cases),表示全部个案
2)如果条件满足(If condition is satisfied),表示根据自定的逻辑关系表示式选择数据。
3)随机个案样本(Random sample of cases),表示随机选取数据。
下一篇预告:表格+图形创建


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









