




作者:vivo 互联网大数据团队- Qin Yehai
在离线混部可以提高整体的资源利用率,不过离线Spark任务部署到混部容器集群需要做一定的改造,本文将从在离线混部中的离线任务的角度,讲述离线任务是如何进行容器化、平台上的离线任务如何平滑地提交到混部集群、离线任务在混部集群中如何调度的完整实现以及过程中的问题解决。
一、在离线业务差异
互联网数据业务服务一般可以分为在线服务和离线任务两大类,在线服务是指那些长时间运行、随时响应对实时性要求高、负载压力随着接收流量起伏的服务,如电商、游戏等服务,离线任务是指运行周期短、可执行时间提交对实时性要求低、有一定容错性、负载压力基本可控的服务,如离线计算任务、模型训练等。一般在线服务在白天时段繁忙,离线任务在凌晨繁忙,两者的业务高峰期存在错峰现象,如果按传统方式在线和离线都是分别独立机器部署,业务高峰时期需要更多机器来支持,业务低峰期又存在部分机器空闲,整体资源利用率都不高。因此行业提出来在离线混部的解决方案,在线和离线业务通过混部系统部署在同一批机器,实现共享资源并错峰互补,提高整体的资源利用率。目前业内利用混部技术可以将数据中心的CPU利用率提升至40%左右,vivo在2023年混部平台投入生产也已经将部分混部集群的CPU利用率提升至30%左右,整体收益也是可观的。
混部系统需要有强大的隔离能力,绝大部分都是基于容器,所以混部的前提是在线和离线业务都容器化,对于容器管理工具如K8s来说是更适应于运行时间长、启停次数少、容器数量少的在线服务,在线服务也能比较容易地上容器,而对于运行时间短、启停频繁、容器数量大的离线任务,对K8s来说不是天然地适应,但容器化已是大势所趋,K8s也推出了性能更好的调度器、用于离线任务的控制器,Spark在2.3版本后也支持容器化,诸多技术的发展也推动离线任务实现容器化以及在离线混部的落地。
本文将从在离线混部中的离线任务的角度,讲述离线任务是如何进行容器化、平台上的离线任务如何平滑地提交到混部集群、离线任务在混部集群中如何调度的完整实现以及过程中的问题解决。
二、离线任务容器化
2.1 Spark Operator 方案
2.1.1 方案对比
vivo离线任务大部分任务是以Spark作为执行引擎,Spark任务运行在K8s上,目前业界有两种架构的方案:Spark on K8s及Yarn on K8s。两者部分优缺点对比如下:
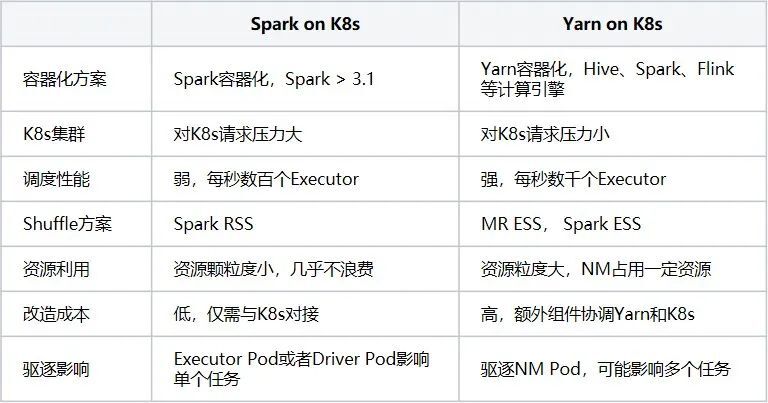
Spark on K8s是Spark容器化,由K8s直接创建Driver和Executor的Pod来运行Spark作业,Yarn on K8s是Yarn的容器化,由K8s创建RM和NM的Pod,Spark的Driver和Executor运行在NM Pod的container中,正是由于两种架构方案的区别,它们各自也会存在优缺点。
Yarn on K8s方案可以支持原生的Hive、Spark、Flink等引擎,它仅需要创建一定数量的NodeManager Pod来满足作业需求,Pod运行相对稳定因此对K8s的压力比较小,本身Yarn支持调度性能和调度策略也是专门为离线任务设计的,调度性能比K8s的强很多。由于NodeManager ESS服务是对磁盘有容量和读写性能要求的,混部机器的磁盘一般难以满足,所以也需要能支持不同引擎的Remote Shuffle Service。在资源利用上,NodeManager需要满足多个作业的资源,最小单位是Container,Pod的资源粒度比较大,自身也会占用一些资源,如果资源粒度得不到有效地弹性伸缩,也会造成资源的浪费,因此需要引入额外的组件来协调,根据Kubernetes集群节点的剩余资源,动态调整NodeManager的CPU和内存,然而这也需要一定的改造成本。在资源紧张的情况下,NodeManager Pod如果被驱逐也就意味着整个NodeManager被销毁,将会影响多个任务。
Spark on K8s方案目前在Spark 3.1以上版本才正式可用,它需要频繁的创建、查询、销毁大量的Executor Pod,对K8s的ApiServer和ETCD等组件都会造成比较大的压力,K8s的调度器也不是专门为离线的大批量任务设计的,调度性能也比较弱。另一方面,Spark on K8s虽然只能支持Spark3.X的RSS,不过目前有较多的开源产品可选择。在资源利用上,最小单位是Driver和Executor的Pod,资源粒度小,可以填充到更多的碎片资源,调度时直接与K8s对接,资源的弹性调度更多由K8s来承担,不需要额外的组件,改造成本比较低。在资源紧张的情况下,Executor、Driver的Pod将依次逐个被驱逐,任务的稳定性会更高。
而对于Spark on K8s方案,还细分2种实现方案:Spark Submit on K8s和Spark Operator on K8s。
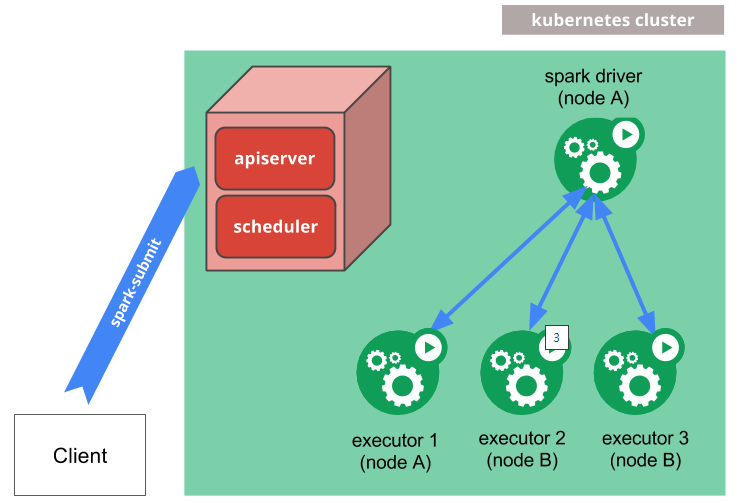
SparkOnK8s架构图
(图片来源:Spark官网)
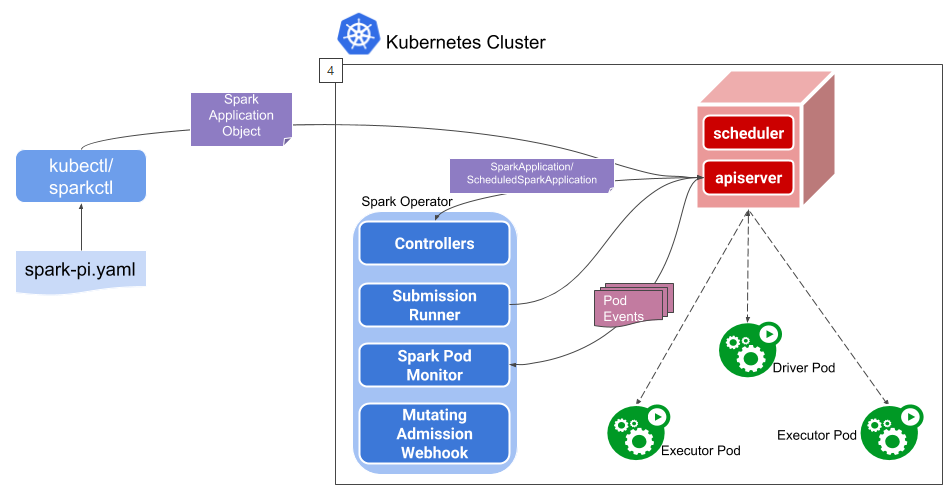
Spark Operator架构图
(图片来源:Spark Operator开源项目)
以spark-submit方式提交到K8s集群是Spark在2.3版本后提供的原生功能,客户端通过spark-submit设置K8s的相关参数,内部再调用K8sApi在K8s集群中创建Driver Pod,Driver再调用K8sApi创建需要的Executor Pod,共同组成Spark Application,作业结束后Executor Pod会被Driver Pod销毁,而Driver Pod则继续存在直到被清理。使用spark-submit方式的最大好处是由spark-submit来与K8s的进行交换,提交作业的方式几乎保持一致。但是因为使用的便利性所需要的封装也会带来一些缺点,spark-submit是通过K8sApi创建Pod,使用非声明式的提交接口,如果需要修改K8s配置就需要重新开发新接口,二次开发复杂繁琐,虽然Spark提供了大量的K8s配置参数,但也远比不了K8s YAML的声明式的提交方式更加灵活,而且Spark Application和K8s Workload的生命周期还不能较好地对应起来,生命周期不能灵活控制,任务监控也比较难接入Prometheus集群监控。虽然Spark社区也不断地在推出新特性来和K8s集成地更加灵活,不过对于些复杂场景需要定制开发,spark-submit的封装性也会成为阻碍。
spark-submit还是离线任务提交的思维,而Spark Operator方式就更倾向于K8s作业的思维,作为K8s的自定义控制器,在集成了原生的Spark on K8s的基础上利用K8s原生能力提供了更全面管控功能。Spark Operator使用声明式的YAML提交Spark作业,并提供额外组件来管理Spark作业的生命周期,SparkApplication控制器,负责SparkApplicationObject的创建、更新和删除,同时处理各种事件和作业状态,Submission Runner, 负责调用spark-submit提交Spark作业,Driver和Executor的运行流程是一致的,Spark Pod Monitor,负责监控和同步Spark作业相关Pod的状态。Spark Operator最大的好处是为在K8s中的Spark作业提供了更好的控制、管理和监控的功能,可以更加紧密地与K8s结合并能灵活使用K8s各种特性来满足复杂场景,例如混部场景,而相对地它也不再像spark-submit那样方便地提交任务,所以如何使用Spark Operator优雅提交任务将是在离线混部中一项重要的工作。
2.1.2 最终选项
在大的架构选型上,我们选择了Spark on K8s,一方面因为Spark3.X是vivo当前及未来2~3年的主流离线引擎,另一方面vivo有比较完善的K8s生态体系,内部对K8s研发也比较深入,环境和能力都能很好地支持,在应用的小方向上,我们选择了Spark Operator,因为它在混部这种复杂场景下使用更加灵活、扩展性更强、改造成本更低,我们最终决定使用Spark Operator方案。
2.2 Spark优化
2.2.1 Spark镜像
Spark任务容器化的第一步就是构建具有Spark相关环境的镜像,Spark任务类型主要分为sql任务和jar任务,在实践的过程中我们发现Spark的镜像构建需要注意几个问题:
- <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









