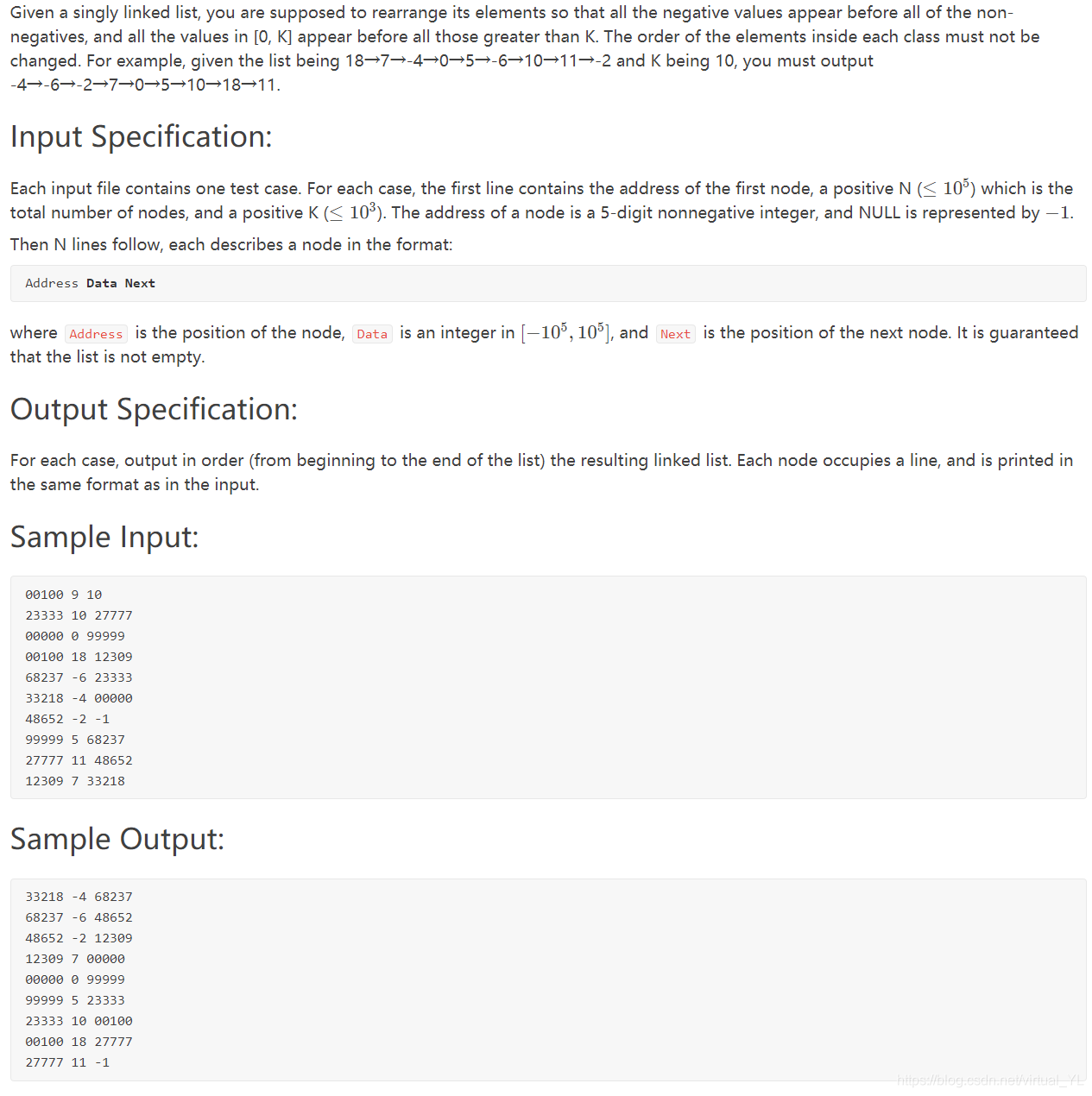
 链表重新排序
链表重新排序





 该博客主要讨论如何对链表进行重新排序,将负数、[0,K]区间内的数和大于K的数分别排列,同时保持原链表中各类别内部顺序。作者提出使用三个集合(或数组)存储不同类别的节点,通过自定义排序和映射操作来实现这一目标。在代码实现过程中,作者遇到了数据重复可能导致的问题,并对此进行了反思,提出在考虑特殊情况的同时,也要注重基础数据结构和算法的应用。
该博客主要讨论如何对链表进行重新排序,将负数、[0,K]区间内的数和大于K的数分别排列,同时保持原链表中各类别内部顺序。作者提出使用三个集合(或数组)存储不同类别的节点,通过自定义排序和映射操作来实现这一目标。在代码实现过程中,作者遇到了数据重复可能导致的问题,并对此进行了反思,提出在考虑特殊情况的同时,也要注重基础数据结构和算法的应用。
题目大意:
给一条链表,把这个里面的数据按三类排好:
- 负数排在最左边,[0,K]区间内的排中间,比K大的排右边
- 里面最关键的一点是:每一类的顺序按原先的相对顺序排列
思路:
首先考虑的是可以用三个set集合分别存储三个类别,set的元素类型为node结构体,属性包括自身地址,数据,以及在原链表的位置,原链表中下一结点的地址。而它们的排序就可以用自定义sort函数来实现。
而原链表的位置该如何得到呢?可以通过首先在输入的时候就构建结构体存到动态数组里,通过遍历寻找下一地址
因为刚刚去看了数据的取值范围,K≤10的3次方,如果两重循环一开始,很容易就超时了。
由于我不太了解map是否可以做一个string到node的映射,如果可以的话,可以通过一个while循环来进行遍历。
且在这种方式里如果从头结点开始的话,就省去了排序的步骤,用三个动态数组来存储就可以了。那么node的属性便只要:本身地址,数据,下一地址。
在实际编写代码中,又再次做了一些修改,因为三个数组很容易出现其中有一个没有的情况,所以又把三个合成一个。
代码:
#include<iostream>
#include<unordered_map>
#include<vector>
#include<cstring>
using namespace std;
unordered_map<string,string> m;
unordered_map<string,int> m1;
unordered_map<int,string> m2;
vector<int> vn,vin,vgreat,ans;
int main(){
int n,k;
string ad;
cin>>ad>>n>>k;
for(int i=1;i<=n;i++){
string selfad,nextad;
int data;
cin>>selfad>>data>>nextad;
m[selfad]=nextad;
m1[selfad]=data;
m2[data]=selfad;
}
int i=1;
while(ad!="-1"){
if(m1[ad]<0) vn.push_back(m1[ad]);
else if(m1[ad]>k) vgreat.push_back(m1[ad]);
else vin.push_back(m1[ad]);
ad=m[ad];
}
for(int i=0;i<vn.size();i++){
ans.push_back(vn[i]);
}
for(int i=0;i<vin.size();i++){
ans.push_back(vin[i]);
}
for(int i=0;i<vgreat.size();i++){
ans.push_back(vgreat[i]);
}
for(int i=0;i<ans.size();i++) printf("%s %d %s\n",m2[ans[i]].c_str(),ans[i],i==ans.size()-1?"-1":m2[ans[i+1]].c_str());
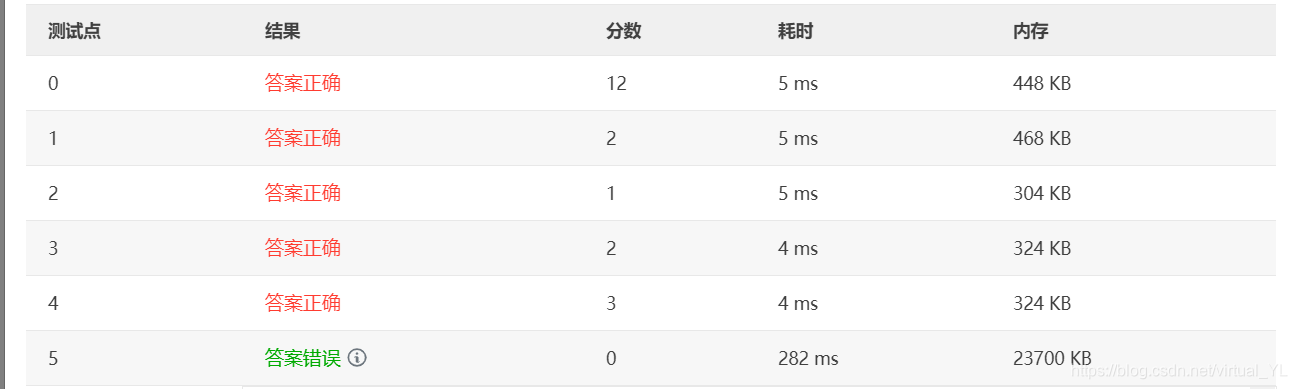
但还有一个测试点过不了,猜测是因为map出了问题,因为我这里考虑到的是data均为不同值的情况是绝对可以的。但如果data出现值一致的情况,map会出现异常。后来看了看其他的代码,其实思路还是很像的,但是一些基础的配置不一样,比如说她首先是用了一个node结构体,这里的地址是用int类型,我选取string类型的原因是因为它是个五位地址位,但看完后我才发现可以用之前的%05d来实现这个。地址用int之后便用一个node数组来存储每个结点作为一个地址数组,同时也把每个节点通过依次迭代存入vector数组中,然后分三次遍历vector分类存入ans中,最后再输出。
tips:
- 像地址位,ID之类的固定位数的整数,不一定只想到string,还可以最先用int来存,最后用%05d之类的输出就好
- 结构体数组,复杂的要学要能用,但基础简单的也要时刻记在心里。
- 要考虑到每一种可能出现的情况,周全和全面是一个好的程序应具备的性质。

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









