




前言
最近公司有一些公司频繁发生一些重大故障, 加上最近核心域凌晨比较多的一些缓存超时(Caused by: net.spy.memcached.internal.CheckedOperationTimeoutException: Timed out waiting for operation),不得不让人提高警惕。此时间段超时比较多,是因为该时间段是缓存预热高峰期。
排查有3种原因:
- memcached服务端支持的并发连接数已满,spymemcache客户端操作超时;
- memcache客户端添加获取数据时,主要spymemcache是基于nio异步获取的,所以当获取数据时会把任务添加任务队列等待执行,同时spymemcache也会做数据获取的链接超时验证,如果超过设置的超时时间(默认时间2500ms)就会报异常;
- 一次性get的key过多;
目前该超时在总请求数占比相对很小,假如某个时间点,有大部分超时,将导致大部分缓存穿透,对mysql数据库造成巨大压力。下面我们讨论一些关于缓存穿透的一些预防措施及相关设计。
缓存穿透
我们先来了解一下缓存穿透的定义
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题.
业界有两种常用预防缓存穿透的方法
(1)采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
(2)如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,这个根据业务上允许的时间为准。通过这个直接设置的默认值存放到缓存,这样第二次到缓存中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴!
针对第一种方法,大体的预防方案设计如下图
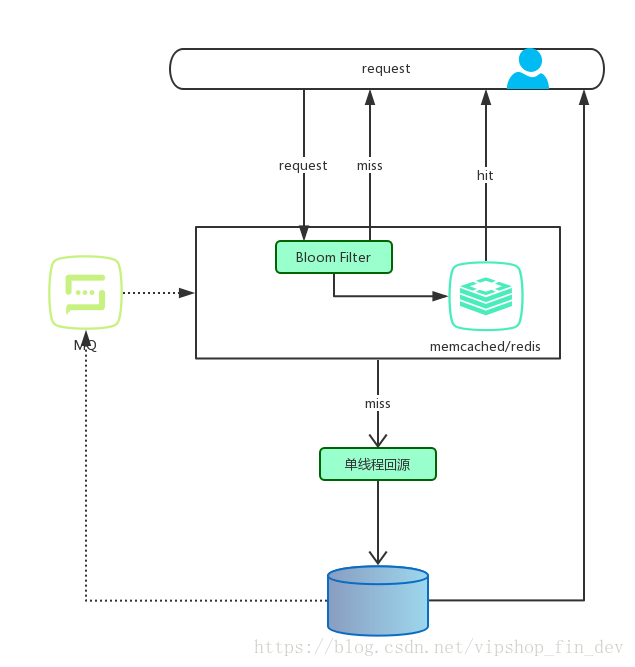
在访问所有资源(cache, storage)之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截,例如: 我们的价格服务有1亿个sku, 我们可以对所有sku对应的key做一份布隆过滤器,这样可以过滤掉一些不在本系统定价的一些请求,减少cache\storage资源的压力。
伪代码如下
if (!bloomfilter.mightContain(key)) {
return null;
}
String value = redis.get(key);
if (value == null) {
return null;
} else {
//这里用mutex锁实现单线程回源i)
value = getFromCacheDb(key);
}
return value;
private String getFromCacheDb(String key) {
String redis = null;
String value = redis.get(key);
if (value == null) {
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else{
sleep(50);
getFromCacheDb(key);//重试
}
return value;
}
附
一、布隆过滤器是什么?
- 又快又小的处理方法
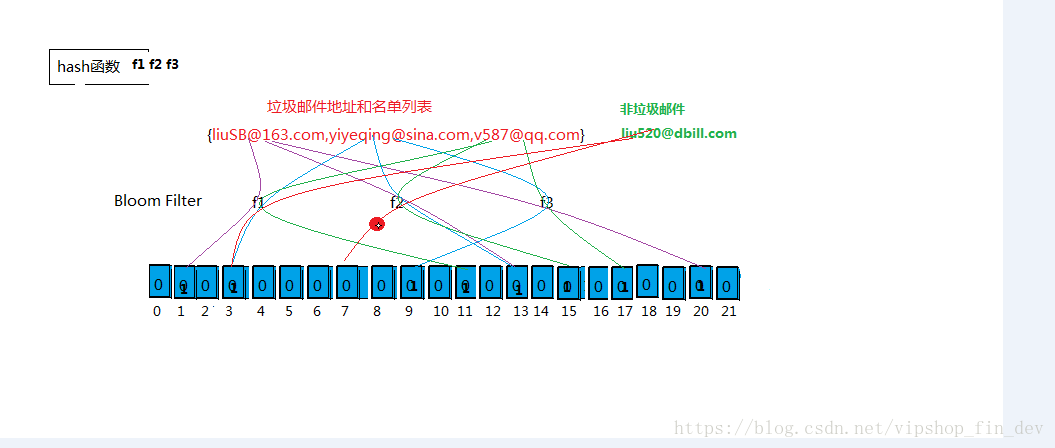
- 布隆过滤器(Bloom Filter):是一种空间效率极高的概率型算法和数据结构,用于判断一个元素是否在集合中(类似Hashset)。
- 它的核心一个很长的二进制向量和一系列hash函数
- 数组长度以及hash函数的个数都是动态确定的
- Hash函数:SHA1,SHA256,MD5…
二、优势和劣势
优势
- 全量存储但是不存储元素本身,在某些对保密要求非常严格的场合有优势;
- 空间高效率
- 插入/查询时间都是常数O(k),远远超过一般的算法
劣势
- 存在误算率(False Positive),随着存入的元素数量增加,误算率随之增加;
- 一般情况下不能从布隆过滤器中删除元素;
- 数组长度以及hash函数个数确定过程复杂;
参考文章:
https://en.wikipedia.org/wiki/Bloom_filter
http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html
https://github.com/erikdubbelboer/Redis-Lua-scaling-bloom-filter
https://www.cnblogs.com/atomicbomb/p/8979582.html

















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









