






背景
前段时间完成的会员积分系统,该系统的积分赠送等规则相对复杂,在匹配规制的时候很难精确的筛选出想要的规制,只能在数据库简单的赛选后,再将结果通过程序进行匹配。这种实现方式当规制多的时候命中规制会特别慢。
数据库的缺陷
传统的关系型数据库是通过索引来达到快速查询的目的,但是在全文搜索的业务场景下,索引很难满足。我们先举个例子看看关系型数据库为什么无法满足全文搜索的要求。
| ID | 地址 | 开发商 | 户型 | 面积 | 单价 | 交通 | 周边 |
|---|---|---|---|---|---|---|---|
| 1 | 地址A | 万科 | 两房一厅、三房两厅两卫、四房两厅 | 60平、99平、160平 | 30000、33000、36000 | 地铁、BRT | 华润万家、市一级学校、购物街等 |
| 2 | 地址B | 碧桂园 | 三房两厅两卫、四房两厅、独立别墅 | 99平、160平 | 18000、20000 | 公交、地铁 | 游乐园、动物园 |
| 3 | 地址C | 开发商A、开发商B | 三房两厅两卫、四房两厅 | 99平、160平 | 8000 | 公交 | 购物商场 |
- 用户A:天河某公司高管,有两个小孩;他的搜索条件是地址(天河)+户型(四房两厅)+周边(学位房),这些查询条件都是需要通过模糊查询进行搜索结果的;
- 用户B:某碧桂园员工,想买房结婚,价格希望在2万块钱左右,出行方便,喜欢游玩;他的搜索条件是碧桂园+99平+20000+游乐园;其中户型、面积、单价、交通、周边都需要模糊查询;
以上只是简单的举了两个例子,实际上搜索条件是无法列举完全的,各种排列组合特别的多,且不固定。我们按照常规方案,将这些数据存在关系数据库中,会有以下缺陷:
- 由于搜索条件可以任意排列组合,如果通过索引来满足,则索引的数量会特别多;
- 模糊查询只能通过 like ‘%***%’ 进行搜索结果,而这种like查询是全表扫描,不会走索引,效率非常低
由此可以看出关系数据库的全文搜索功能比较弱,只能使用like进行整表扫描匹配,性能非常低,在互联网这种搜索复杂的场景下无法满足,而全文检索可以解决这痛点。
全文检索基本原理
全文检索的技术原理是倒排索引,也可以称作反向索引。其是一种索引方法,器基本原理是建立单词到文档的索引。当然这里指的文档是一个泛指,它不单单指一些普通的文档,还可以是数据库中的某一条记录。
Lucene
介绍
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。–【百度百科】
基本概念
Lucene的索引结构从大到小分为以下几个概念:index,segments,document,field,term
- Index:一个索引,包括所有需要的信息内容;
- Segments:可以理解为一个子索引(sub-index),每当往index中新加入一个document时,都会新生成一个segments保存这个document,然后通过判断,合并部分segments,最后通过优化索引的命令,把所有的segments合并成一个index,Lucene 8.0.0会自动合并优化,而且也只会保留一个segments文件;
- Document:一般以document为单位往index中添加记录,一个document可以是一个txt,一个html或者是数据库的一条记录。一个document由几个field的组成;
- Field:一个document通常被分为几个field,用于保存不同的信息,如数据库的一条记录,不同的字段就是不同的field,当搜索时,可以指定在哪个field进行搜索,field由一组term组成;
- Term:是最基本的索引单位,一般每个field由很多个term组成;term由一对值组成,一个值表示他属于哪个field,另一个表示他本身的值,所以两个不同的field里相同的string并不是一个term。
Lucene过程

1、生成文档;
2、通过解析器进行解析文本,创建词条;
3、创建词条与文档的索引关系;
4、打开索引文件;
5、通过解析器解析用户输入的查询条件;
6、检索并返回结果。
代码实现
生成索引
以下代码基于Lucene 8.0.0
package com.vip.fcs.vpos.Lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
public class IndexFiles {
public static void main(String[] args) {
String indexPath = "E:\\Lucene\\index";
try {
Path file = Paths.get(indexPath);
IndexWriter writer = getIndexWriter(file);
addDocument(file,writer);
writer.close();
} catch (IOException e) {
System.out.println(" caught a " + e.getClass() +
"\n with message: " + e.getMessage());
}
}
static IndexWriter getIndexWriter(Path file) throws IOException {
Directory dir = FSDirectory.open(file);
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(dir, iwc);
return writer;
}
static void addDocument(Path file,IndexWriter writer) throws IOException {
Document doc1 = new Document();
doc1.add(new StringField("id", "1", Field.Store.YES));
doc1.add(new StringField("address", "地址A",Field.Store.NO));
doc1.add(new TextField("other", "万科,两房一厅、三房两厅两卫、四房两厅,60平、99平、160平,地铁、BRT",Field.Store.NO));
writer.addDocument(doc1);
Document doc2 = new Document();
doc2.add(new StringField("id", "2", Field.Store.YES));
doc2.add(new StringField("address", "地址B",Field.Store.NO));
doc2.add(new TextField("other", "碧桂园,三房两厅两卫、四房两厅、独立别墅,游乐园、动物园",Field.Store.NO));
writer.addDocument(doc2);
Document doc3 = new Document();
doc3.add(new StringField("id", "3", Field.Store.YES));
doc3.add(new StringField("address", "地址C",Field.Store.NO));
doc3.add(new TextField("other", "开发商A、开发商B,三房两厅两卫、四房两厅,购物商场",Field.Store.NO));
writer.addDocument(doc3);
}
}
全局搜索
package com.vip.fcs.vpos.lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import java.io.IOException;
import java.nio.file.Paths;
public class SearchFiles {
private SearchFiles() {}
public static void main(String[] args) throws Exception {
String index = "E:\\Lucene\\index";
String field = "other";
String queryString = "三房两厅两卫";
int hitsPerPage = 10;
IndexReader reader = DirectoryReader.open(FSDirectory.open(Paths.get(index)));
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer();
QueryParser parser = new QueryParser(field, analyzer);
Query query = parser.parse(queryString.trim());
System.out.println("Searching for: " + query.toString(field));
doPagingSearch(searcher, query, hitsPerPage);
reader.close();
}
public static void doPagingSearch( IndexSearcher searcher, Query query,
int hitsPerPage) throws IOException {
TopDocs results = searcher.search(query, 5 * hitsPerPage);
ScoreDoc[] hits = results.scoreDocs;
for(int i = 0;i < hits.length;i++){
Document doc = searcher.doc(hits[i].doc);
String id = doc.get("id");
String address = doc.get("address");
String other = doc.get("other");
System.out.println("id : " + id);
System.out.println("address : " + address);
System.out.println("other : " + other);
System.out.println("------------------------------------------------");
}
}
}
通过“三房两厅两卫”搜索出来的结果如下:
Searching for: 三 房 两 厅 两 卫
id : 1
address : null
other : null
------------------------------------------------
id : 3
address : null
other : null
------------------------------------------------
id : 2
address : null
other : null
------------------------------------------------
其中address 、other这两个Field设置的Store是Field.Store.NO,表示不存储,故这里返回null
关键类说明
IndexWriter:lucene 中最重要的的类之一,它主要是用来将文档加入索引,同时控制索引过程中的一些参数使用。
Analyzer:分析器,也叫分词器。解析各种文本,然后将文本拆分为一个个词条;如果Lucene提供的分词器不能满足需求的时候可以实现Analyzer类里面的createComponents抽象方法,而实现自己的Analyzer
Directory:索引存放的位置;lucene 提供了两种索引存放的位置,一种是磁盘(FSDirectory),一种是内存(RAMDirectory),一般情况下都会选择存放在磁盘进行持久化。
Document:文档,相当于一个要进行索引的单元,任何想要被索引的文件都必须转化为Document 对象才能进行索引。
Field:字段,可以选择是否需要进行分词,是否需要存储。
IndexSearcher:基本的检索工具类。
Query:查询类,具体实现类有:精准匹配TermQuery,区间查询TermRangeQuery,数字搜索NumericRangeQuery等一些类。
QueryParser:对查询条件通过分词器进行解析,然后在组装成Query。
Hits:通过查询条件命中结果集合。
索引文件查看
通过Lucene的索引查看工具“luke”,可以很清楚的看到Lucene生成的索引文件长什么样。
注意:luke的版本必须和Lucene的一致,要不然无法打开索引文件
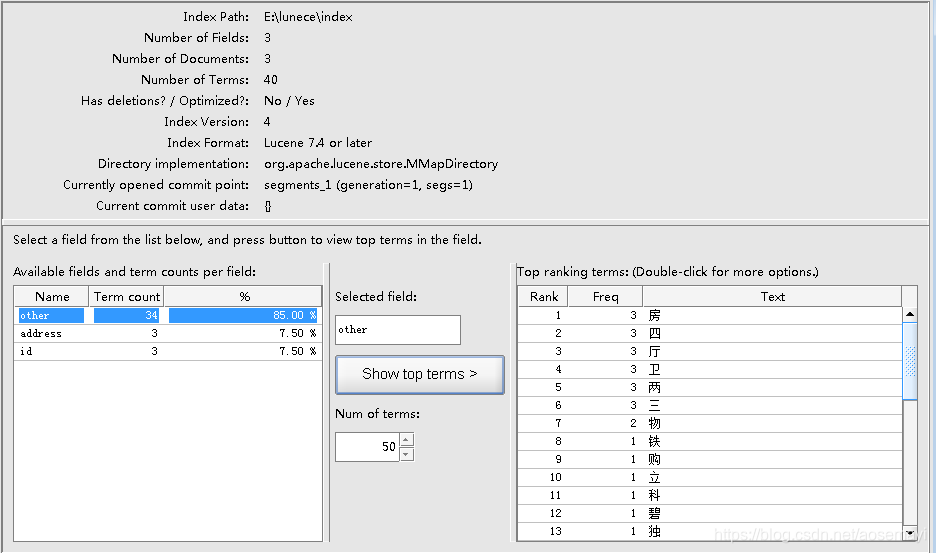

可以看到id、address没有进行分词,而other则按照字进行了分词。
下载地址
luke:https://github.com/DmitryKey/luke
Lucene:https://lucene.apache.org/
作者:张伟峰

















 2813
2813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









