




 本文详细介绍使用Python的pandas库进行数据清洗的过程,包括处理缺失值、转换数据类型、标准化文本格式等关键步骤,通过具体案例展示了如何提高数据质量。
本文详细介绍使用Python的pandas库进行数据清洗的过程,包括处理缺失值、转换数据类型、标准化文本格式等关键步骤,通过具体案例展示了如何提高数据质量。
import pandas as pd
import os
os.chdir('C:\\Users\\Violette\\Desktop\\')
data1=pd.read_csv('11数据.csv',encoding= 'gbk',header=None)
data1.rename(columns={0:'No',1:'Name',2:'Age',3:'Weight'},inplace=True)
data1
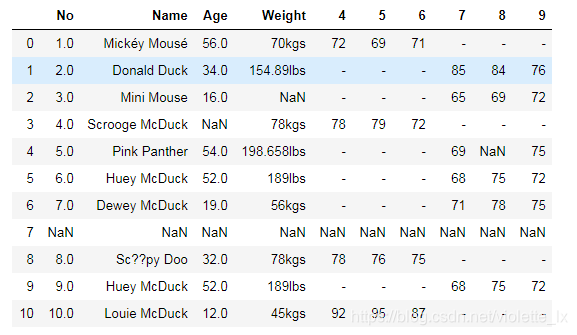
#完整性
#缺失值:删除、均值、高频
#删除全空的行
data1.dropna(how='all',inplace=True)
#均值填充
#data1['Weight'].fillna(data1['Weight'].mean(),inplace=True)
#高频填充
age_maxf=data1['Age'].value_counts().index[0]#value_counts得到Age名和频次
data1['Age'].fillna(age_maxf,inplace=True)
data1
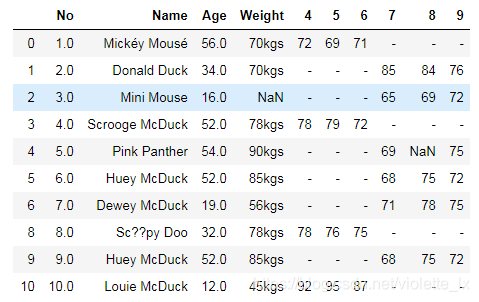
#尽量表格内容不带单位方便处理,将单位标注在标签上
#去掉单位
data1['Weight']=data1['Weight'].str.replace('kgs','')
#由str转为float
data1['Weight']=pd.to_numeric(data1['Weight'])
#均值填充Weight
data1['Weight'].fillna(data1.Weight.mean(),inplace=True)
#将单位移动到name
data1.rename(columns={'Weight':'Weight(kgs)'},inplace=True)#注意inplace
data1
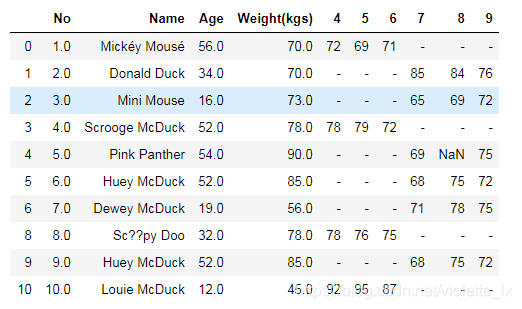
#合理性
#拆分Name为名和姓
data1[['firstname','lastname']]=data1['Name'].str.split(expand=True)
#删除Name
data1.drop('Name',axis=1,inplace=True)
#更改df的顺序
order=['No','firstname','lastname','Weight(kgs)',4,5,6,7,8,9]
data1=data1[order]
#转换非ASCII字符
data1['firstname'].replace({r'[^\x00-\x7F]+':''},regex=True,inplace=True)
data1['lastname'].replace({r'[^\x00-\x7F]+':''},regex=True,inplace=True)
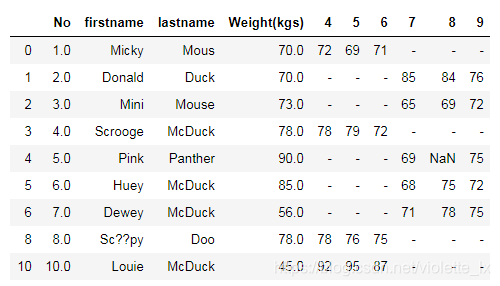
data1
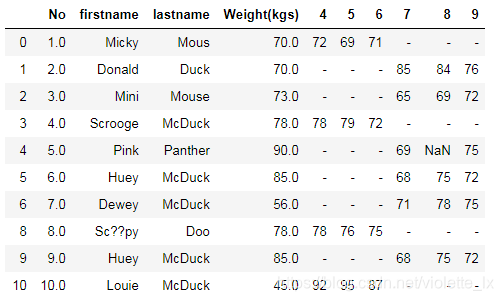
#唯一性 删除重复数据
data1.drop_duplicates(['firstname','lastname'],inplace=True)
data1
课后练习:
import pandas as pd
import os
os.chdir('C:\\Users\\Violette\\Desktop\\')
data=pd.read_csv('11作业数据.csv',encoding='UTF-8')
data
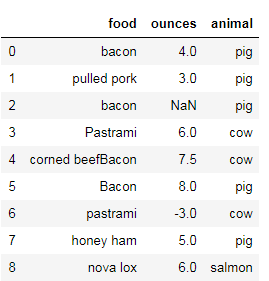
发现的问题:
food列大小写混杂——str.capotalize统一首字母大写
ounces存在缺失项——用这一项的均值填补缺失值
ounces不应有负数——按照负数条件删除列
corned beef Bacon这个应该有问题但我没弄它
data.info()
data.food.str.capitalize()
mean_ounce=data[(data['food']=='Bacon')&(data['ounces'].notnull())]['ounces'].mean()
data.loc[data['ounces'].isnull(),'ounces']=mean_ounce
data= data.drop(data[data.ounces < 0].index).reindex()
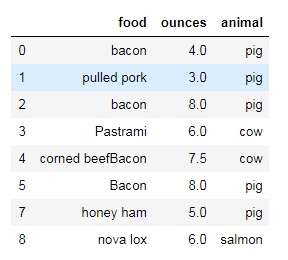
data

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









