




本人项目地址大全:Victor94-king/NLP__ManVictor: 优快云 of ManVictor
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
引言
检索增强生成(RAG)框架通过将检索机制与生成模型相结合,彻底改变了大型语言模型(LLM)的使用方式。随着人工智能解决方案需求的不断上升,GitHub 上陆续出现了多个开源的 RAG 框架,每个框架都提供了独特的功能和特性。
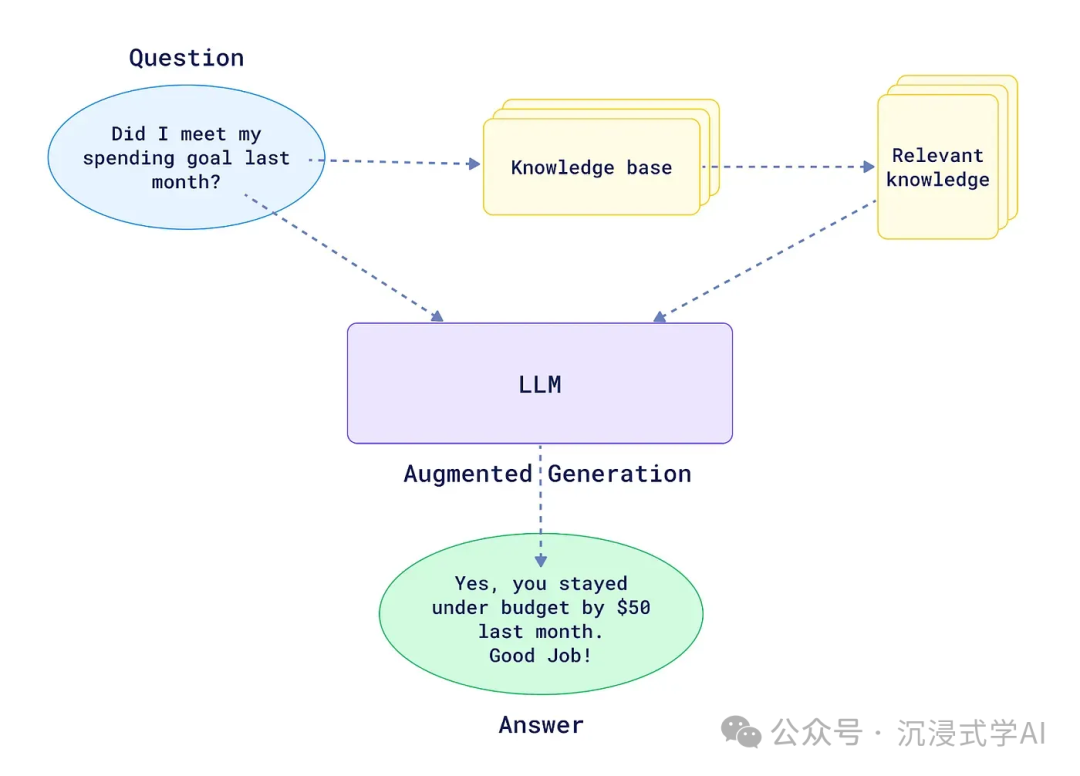
以下是 RAG 框架的主要特点:
• 知识检索 —— 这一核心功能使 RAG 框架能够通过从外部知识库中提取相关信息,为大型语言模型提供上下文支持。
• 生成模型增强 —— 通过利用检索到的信息来改善 LLM 的输入,从而使模型能够生成更准确、更新、更符合上下文的响应。
• 多轮交互 —— 此功能允许 RAG 系统通过与用户的多次交互不断完善查询和生成内容,从而提升用户满意度和系统的整体准确率。
• 模型优化 —— 通过各种技术手段(例如查询消歧、查询抽象以及索引优化)提升 RAG 系统的性能。
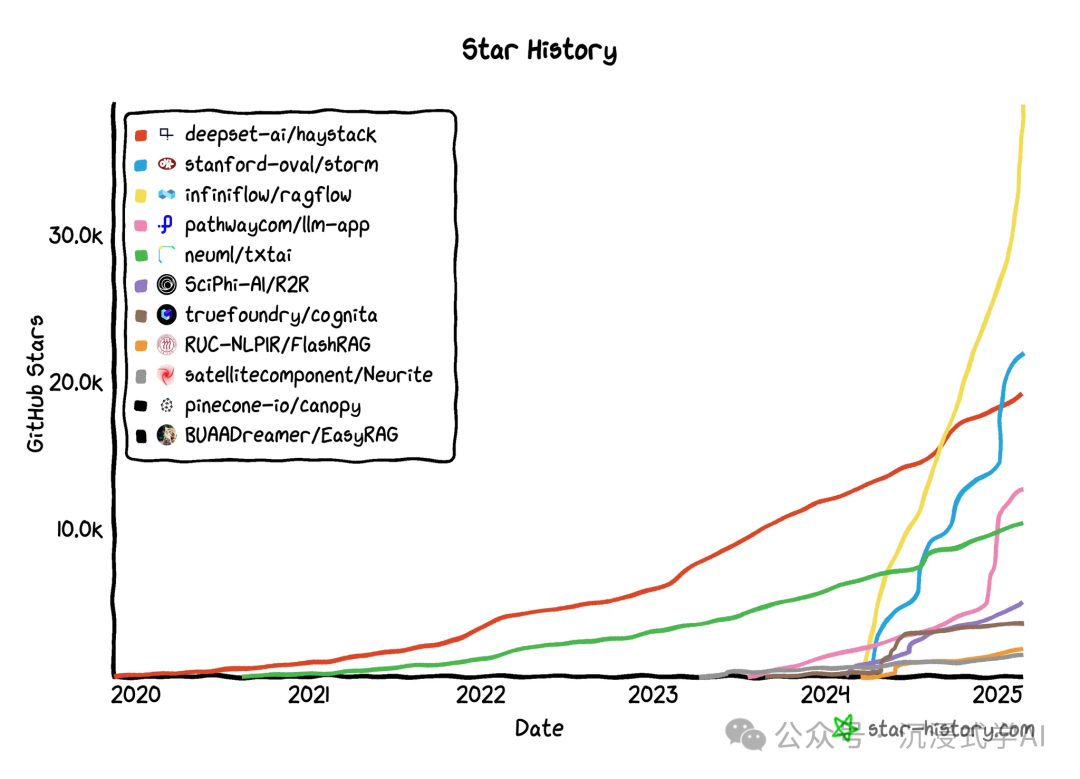
21 大著名的 RAG 框架
这些框架通过将大型语言模型与外部知识库相结合,提高了生成内容的准确性和可靠性,在医疗、金融、客户服务及教育等领域具有重要价值。
RAGFlow
• 网址 :https://github.com/infiniflow/ragflow
• 特点 :简化的工作流设计,内置预构建组件,并与向量数据库集成。
• 适用对象 :希望快速构建 RAG 应用的开发者和组织。
• 工作流设计 :直观的界面用于设计和配置 RAG 工作流。
• 预配置工作流 :提供常见场景的即用型工作流。
• 向量数据库集成 :与向量数据库无缝集成,实现高效检索。
• 应用场景 :实时应用,如聊天机器人和即时问答系统。
• 用户体验 :用户友好且高效,降低了学习曲线和开发时间。
• 社区支持 :因其简单有效,RAGFlow 正逐渐受到越来越多人的青睐。
Haystack

• 网址 :https://github.com/deepset-ai/haystack
• 特点 :模块化设计,包含文档检索、问答和文本摘要等组件;支持 Elasticsearch、FAISS 和 SQL 等多种文档存储方案。
• 适用对象 :开发者、研究人员以及构建端到端问答与搜索系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3884
3884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











