



正则表达式
【1】、三剑客与正则表达式
1、注意事项
- 正则符号都是英文符号,避免使用中文符号
- 推荐使用grep/egrep命令,默认设置了别名alias,自动加上颜色
【2】、符号概述
正则:regular expression (RE)
| 正则表达式regular expression | 符号 |
|---|---|
| 基础正则BRE | ^ $ . * .* [] [^] |
| 扩展正则ERE | | + () ? {} |
| 其他类型正则(Perl语言类型正则) |
【3】、基础正则
1、^ 以…开头
⚠️英文的符号
[root@Ansible-server /]# grep '^root' /etc/passwd
root:x:0:0:root:/root:/bin/bash
2、$ 以…结尾
[root@Ansible-server /]# grep 'nologin$' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
❓为什么我看着文件中有但是却过滤不出来
文件明明是以"o"结尾的,为什么却过滤不出来呢?
[root@Ansible-server opt]# cat a.txt 123mnmmlo [root@Ansible-server opt]# grep 'o$' a.txt我们可以使用
cat -A去查看一下文件[root@Ansible-server opt]# cat -A a.txt 123mnmmlo $我们会发现文件的结尾出现了一个“$”,并且还有一个空格,这又是什么呢?
这主要是由于
cat -A他显示出了文件中隐藏的符号,这个符号,在Linux中是一行结束的标志,每一行结束都要加一个这个符号,在Linux中是一行结束的标志,每一行结束都要加一个这个符号,在Linux中是一行结束的标志,每一行结束都要加一个,只不过在我们日常查看时,他是处于隐藏状态的,我们看不到从这也就可以说明为什么在正则表达式中要用“$”去表示以什么结尾。
从上面的代码中我们可以看到,$和正文之间还有一个空格,也就是说明,正文并不是以o结尾的,而是以空格结尾。至此我们也就知道为什么我们查不到以o结尾的数据了。
我们可以这样做,问题被解决
[root@Ansible-server opt]# grep ' $' a.txt 123mnmmlo
3、^$ 匹配空行
[root@Ansible-server opt]# grep -n '^$' a.txt
2:
一般来说我们是不想看空行的
因此会把空行过滤出去
grep -v,反向过滤
[root@Ansible-server opt]# grep -n -v '^$' a.txt
1:123mnmmlo
4:afasg
开生产环境中,我们一般会排除空行和#开头的行(注释行),这些会影响我们的观感
[root@Ansible-server opt]# grep -v '^$' /etc/ssh/sshd_config | grep -v '^#'
4、. 任意一个字符
初学正则时,很少单独使用
不匹配空行
[root@Ansible-server opt]# grep -n . a.txt
1:123mnmmlo
4:afasg
- grep -o:显示正则表达式匹配到了什么内容,以及正则表达式的匹配过程

5、\撬棍
转义字符,去掉特殊符号的含义,让其表示原本的内容
通常和.使用搭配使用
例如:我们相匹配文件中所有以.结尾的行
如果我们直接使用.$,匹配到的是所有行,因此我们就需要将.的特殊含义去除
[root@Ansible-server opt]# grep -n '.$' a.txt
1:123mnmmlo
3:af.
4:23452rtryret.
5:afasg
[root@Ansible-server opt]# grep -n '\.$' a.txt
3:af.
4:23452rtryret.
**6、* 前一个字符连续出现0次或0次以上 **
理解什么是连续/重复
111 数字1连续出现了3次
2222 数字2连续出现了4次
weqqrqq 英文字母连续出现了7次
12we 英文字母和数字连续出现了4次
这些都可以算是连续出现,而不是说只有出现相同的内容才算连续出现
❓我们去过滤“2*”,我们发现所有的都过滤出来了,这是为什么呢?
* 他可以匹配0次或0次以上的内容,那就可以解释为,不是2 的内容,我们就认为其是 2 出现了0次,因此也就满足要求,可以匹配出来
[root@Ansible-server opt]# grep -n '2*' a.txt
1:123mnmmlo
2:
3:af.
4:23452rtryret.
5:112222fgh
6:2225564vvv
7:afasg
8:222
7、.* 所有
使用频率特别高,表示所有,任何东西
- .表示任意字符
- *表示0次或0次以上匹配
- .*表示匹配所有
[root@Ansible-server opt]# grep -n '^.*linux' a.txt
5:I learn linux
6:I do not learn linux
贪婪匹配
正则表达式表示连续出现或者表示所有的时候正则表达式会体现出贪婪性,尽可能多的去匹配
他会一直去匹配a,直到最后一个

8、[]匹配任意一个字符
[abc]:表示匹配a或者b或者c
匹配中括号中的任意一个字符

⚠️[]会自动去掉特殊符号的特殊含义
9、[^]表示过滤除了中括号中的内容
[^abc]:表示过滤文件中除了abc之外的内容
[root@Ansible-server opt]# grep -n '[^a-z]' a.txt
1:123mnmmlo
7:iaflknklanaaanubkbajo9878970akbjkhakj6797
8:222
【4】、扩展正则
- grep不支持扩展正则的使用
- egrep 支持扩展正则
- sed 使用sed -r支持扩展正则
- awk 默认支持扩展正则
1、+ 前一个字符连续出现1次或1次以上
-
一般搭配着【】一起使用
-
去除连续出现的2
[root@Ansible-server opt]# grep '2+' a.txt [root@Ansible-server opt]# egrep '2+' a.txt 123mnmmlo 222 -
连续出现的数字
[root@Ansible-server opt]# egrep '[0-9]+' a.txt 123mnmmlo iaflknklanaaanubkbajo9878970akbjkhakj6797 222 -
连续出现的单词
[root@Ansible-server opt]# egrep '[a-Z]+' a.txt 123mnmmlo iaflknklanaaanubkbajo9878970akbjkhakj6797 [root@Ansible-server opt]# egrep -o '[a-Z]+' a.txt mnmmlo iaflknklanaaanubkbajo akbjkhakj -
统计单词出现的次数
[root@Ansible-server opt]# egrep -o '[a-Z]+' a.txt | sort | uniq -c 1 akbjkhakj 1 iaflknklanaaanubkbajo 1 mnmmlo
2、| 或者
一般是过滤出含有单词1或者含有单词2的行
[root@Ansible-server opt]# egrep -n 'linux|apple' a.txt
3:apple agsag vv
4:linux wrathh apple
在/etc/services中过滤出:ssh或http或smtp
[root@Ansible-server opt]# egrep 'ssh|http|stmp' /etc/services
排除/etc/ssh/sshf_conf中的空行和注释行
[root@Ansible-server opt]# egrep -v -n '^$|^#' /etc/ssh/sshd_config
3、()表示一个整体,或者后向引用
()表示一个整体或者在sed中表示后向引用
[root@Ansible-server ~]# rpm -qa | egrep '^tree|^vim|^sl'
vim-enhanced-8.0.1763-19.el8_6.4.x86_64
vim-filesystem-8.0.1763-19.el8_6.4.noarch
vim-common-8.0.1763-19.el8_6.4.x86_64
tree-1.7.0-15.el8.x86_64
vim-minimal-8.0.1763-19.el8_6.4.x86_64
slang-2.3.2-3.el8.x86_64
slirp4netns-1.2.1-1.module+el8.9.0+19731+94cfa27e.x86_64
sl-5.02-1.el8.x86_64
# 表示一个整体
[root@Ansible-server ~]# rpm -qa | egrep '^(tree|vim|sl)'
vim-enhanced-8.0.1763-19.el8_6.4.x86_64
vim-filesystem-8.0.1763-19.el8_6.4.noarch
vim-common-8.0.1763-19.el8_6.4.x86_64
tree-1.7.0-15.el8.x86_64
vim-minimal-8.0.1763-19.el8_6.4.x86_64
slang-2.3.2-3.el8.x86_64
slirp4netns-1.2.1-1.module+el8.9.0+19731+94cfa27e.x86_64
sl-5.02-1.el8.x86_64
4、{}
| 格式 | |
|---|---|
| a{n,m} | 表示连续出现的范围 |
| a{n} | 匹配固定的次数 |
| a{n,} | 前一个字符至少出现n次 |
| a{,m} | 前一个字符连续出现,最多m次 |

 ``
``
## 匹配身份证
[root@Ansible-server opt]# egrep '[0-9]{17}[0-9X]$' a.txt
5、?
表示前一个字符出现0或1次
一般用于匹配的内容可能有(出现1次)或者没有出现(出现0次)
6、扩展正则小结
| 扩展正则 | 含义 |
|---|---|
| +⭐️⭐️⭐️⭐️⭐️ | 前一个字符连续出现一次或者多次 |
| |⭐️⭐️⭐️⭐️⭐️ | 或者 |
| ()⭐️⭐️ | 🅰️表示整体 🅱️表示后向引用(sed中) |
| {} | 表示前一个字符出现的次数范围 |
| ? | 前一个字符出现0或者1次 |
| 基础正则 | 含义 |
|---|---|
| ^⭐️⭐️⭐️⭐️⭐️ | 以…开头 |
| $⭐️⭐️⭐️⭐️⭐️ | 以…结尾 |
| ^$⭐️⭐️⭐️⭐️⭐️ | 过滤空行 |
| . | 任意字符 |
| \ | 转义字符、撬棍 |
| * | 前一个字符出现0次或0次以上 |
| .*⭐️⭐️⭐️⭐️⭐️ | 匹配所有字符 |
| []⭐️⭐️⭐️⭐️⭐️ | [abc],匹配a或b或c |
| [^] | 取反 |
【5】、perl语言正则表达式
- perl正则
支持perl正则的命令
grep -P
| 符号 | 含义 |
|---|---|
| /d | [0-9] |
| /w | [0-9a-zA-Z] |
| /s | 匹配空字符 空格 tab 等等[\ \t\r\n\f] |
| /D | [^0-9] |
| /S | 非空字符 |
| /W | 排除数字,大小写字母和_ |
二十二、三剑客与正则系列-awk与sed
【1】、sed
1、概述
- 核心功能:取行、过滤、替换修改文件内容
- 难点:后向引用(截取)
- sed stream editor(流式编辑器)
2、命令格式
-
命令格式1:前置命令 | sed [选项] ‘[指令]’ 文件名
-
命令格式2:sed [选项] ‘[指令]’ 文件名
| 参数 | 含义 |
|---|---|
| -n | 屏蔽默认输出,默认sed会将所有的输出结果输出到屏幕中,-n只把sed处理的行输出到屏幕 如果不使用-n参数,那么输出的内容会输出两遍,也就是说-n屏蔽的是sed -p的默认输出 |
| -i | 直接修改文件内容,如果不加-i选项,并不会真正改变文件的内容 |
| -r | 使用扩展正则,若与其他选项一起使用,此选项应该在首位 |
| -i.bak | 修改文件内容之前先进行备份,然后再修改内容(一般用于替换一个文件),这个参数要放在所有参数的最后面 |
3、执行流程
sed 的工作流程
读取:sed从输入流(文件、管道、stdin)中读取一行内容并保存到临时文件缓冲区中(又称模式空间:pattern space)
执行:默认情况下,所有的sed命令都在模式空间中顺序地执行,除非制定了行的地址,否则sed命令将会在所有命令行上依次执行
显示:发送修改后的内容到输出流,在发送数据后,模式空间(pattern space)将会被清除
在所有的文件内容都被处理完成之前,上述过程将会重复执行,直至所有的内容被处理完成
在默认情况下,所有的sed命令都是在pattern space中完成的,因此输入的文件不会有任何变化,除非是用重定向存储输出
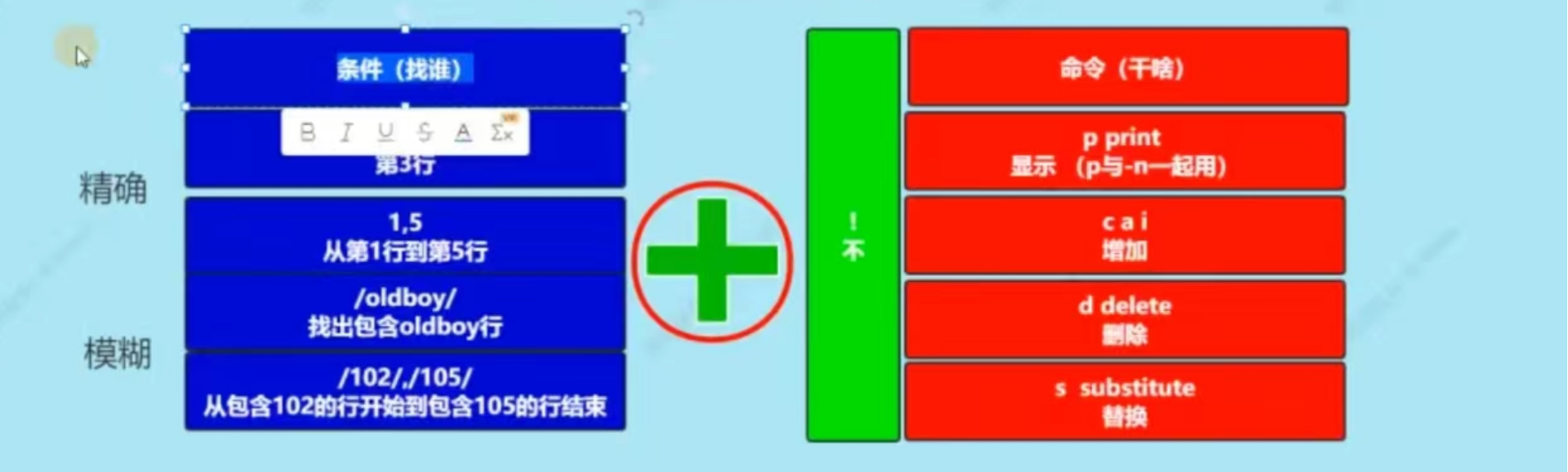
4、sed查找
一种是类似于grep的模糊查找(正则查询)
类似于grep命令的过滤,比grep强在可以指定行号
一种是精确查找,行号
(1)、取出文件的第三行
-n:取消默认输出,sed在处理文件的时候会默认的输出每一行的内容
p:表示输出,一般和-n搭配使用
[root@Ansible-server opt]# sed -n '3p' a.txt
goooood
(2)、取出2到5行
[root@Ansible-server opt]# sed -n '2,5p' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(3)、取出2行和5行
[root@Ansible-server opt]# sed -n '2p;5p' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
(4)、过滤出包含root的行
⚠️sed支持过滤某一个内容
/内容/p,打印出过滤的内容
sed支持正则,默认是支持基础正则
-r参数可以让其支持扩展正则
[root@Ansible-server opt]# sed -n '/root/p' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
stap-server:x:155:155:Systemtap Compile Server:/opt/rh/gcc-toolset-11/root/var/lib/stap-server:/sbin/nologin
[root@Ansible-server opt]# sed -n '/^root/p' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@Ansible-server opt]# sed -r -n '/^(root|bin)/p' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
(5)、模拟过滤日志
[root@Ansible-server log]# cat sed.txt
101,xiaoxu,ccc
102,xiaoli,bbb
103,xiaowang,ddd
104.xiaozhao,qqq
110.xxx,vvv
[root@Ansible-server log]# sed -n '/101/ , /104/p' sed.txt
101,xiaoxu,ccc
102,xiaoli,bbb
103,xiaowang,ddd
104.xiaozhao,qqq
(6)、查找功能小结
- 核心掌握:
- 根据行号查找,模糊查找//,模糊表示范围(日志)
- 注意这里提到的行号,//方式到表示条件(找谁),除了给p(查找)用,还可以给修改,增加,删除使用
- 过滤时与grep类似支持正则表达式,sed -r支持扩展正则
- sed可以指定行号,sed表示过滤范围
5、sed修改(替换)
sed命令的替换格式说明
sed ‘s#找谁#提供换成什么#g’ sed.txt
sed ‘s###g’ sed.txt
推荐使用: ### @@@ ///
当查找替换的内容是# @ / 时就不要使用对应的符号作为分隔符了
s substitute 替换
g global 全局替换,这一行中把所有匹配到的内容都进行替换,如果不加g,则只替换每一行的第一个匹配到的内容
-i参数:直接修改文件内容,如果不加-i选项,并不会真正改变文件的内容。动作指令d、s和选项-i是在搭配一起使用的
修改文件内容之前先进行备份,然后再修改内容(一般用于替换一个文件) -i.bak
[root@Ansible-server log]# sed 's#[0-9]#ccc#g' sed.txt
ccccccccc,xiaoxu,ccc
ccccccccc,xiaoli,bbb
ccccccccc,xiaowang,ddd
ccccccccc.xiaozhao,qqq
ccccccccc.xxx,vvv
[root@Ansible-server log]# sed 's#[0-9]#ccc#' sed.txt
ccc01,xiaoxu,ccc
ccc02,xiaoli,bbb
ccc03,xiaowang,ddd
ccc04.xiaozhao,qqq
ccc10.xxx,vvv
[root@Ansible-server log]# sed -i.bak 's#xiaoxu#lili#g' sed.txt
[root@Ansible-server log]# ls sed.txt
sed.txt
[root@Ansible-server log]# ll sed.txt*
-rw-r--r--. 1 root root 74 May 5 19:59 sed.txt
-rw-r--r--. 1 root root 76 May 5 19:16 sed.txt.bak
- 小结
- 核心掌握sed命令替换的格式
- 核心掌握-i用法
6、sed替换进阶
(1)、后向引用格式
应用说明
后向引用或反向引用:适用于sed命令处理/提取某一行中的部分内容,sed命令配合正则实现取列(类似于awk命令)
是sed命令中用于处理列的方式
使用格式
使用替换形式:s###g
前2个井号之间通过正则与(),对数据进行分组,每一个()是一个组
后面两个井号之间通过\数字,去调用前面分组的内容
整体式后面调用前面分组的内容,称之为反向引用/后向引用
应用场景:某一行中对部分数据进行加工与处理,提取某一部分数据
[root@Ansible-server log]# echo 12345678 | sed -r 's#(1)(.*)(8)#\1<\2>\3#g'
1<234567>8
(2)、案例01
交换/etc/passwd下第一列和第二列的内容
[root@Ansible-server opt]# sed -r 's#(^.*)(:.*:)(.*$)#\3\2\1#g' passwd
/bin/bash:/root:root:x:0:0:root
(3)、案例02
提取IP
[root@Ansible-server opt]# ip address show ens160 | sed -n '4p' | sed -r 's#(^.* )(.*)(/.*$)#\2#g'
192.168.121.141
(4)、案例03
取出stat /etc/hosts中的0644或644
7、sed删除
- d:sed命令删除是按照行为单位进行
- 如果仅仅删除某一行的一个字符,使用替换
[root@Ansible-server opt]# sed '1,3d' /var/log/sed.txt
104.xiaozhao,qqq
110.xxx,vvv
-
案例
-
排除文件中的空行和带注释的行
[root@Ansible-server opt]# sed -r '/^$|#/d' /etc/ssh/sshd_config [root@Ansible-server opt]# egrep -v '^$|#' /etc/ssh/sshd_config [root@Ansible-server opt]# awk '!/^$|#/' /etc/ssh/sshd_config
8、sed增加
- cai
- a:append,在指定行后面追加内容
- i:insert,在指定行上面加上内容
- c:replace,清空当前行,后续的内容作为当前行的内容
[root@Ansible-server opt]# cat sed.txt
101,lili,ccc
102,xiaoli,bbb
103,xiaowang,ddd
104.xiaozhao,qqq
110.xxx,vvv
[root@Ansible-server opt]# sed '3a hahaha' sed.txt
101,lili,ccc
102,xiaoli,bbb
103,xiaowang,ddd
hahaha
104.xiaozhao,qqq
110.xxx,vvv
[root@Ansible-server opt]# sed '3i hahaha' sed.txt
101,lili,ccc
102,xiaoli,bbb
hahaha
103,xiaowang,ddd
104.xiaozhao,qqq
110.xxx,vvv
[root@Ansible-server opt]# sed '3c hahaha' sed.txt
101,lili,ccc
102,xiaoli,bbb
hahaha
104.xiaozhao,qqq
110.xxx,vvv
9、小结
【2】、awk
- awk:单行脚本
- 核心 awk:取行
- 核心 awk:取列
- 核心 awk:混合取行取列
- awk:统计功能
- 未来:判断循环
- 未来:数组
1、awk概述
| 四剑客 | 特点 | 擅长 |
|---|---|---|
| find | 查找文件 | 查找文件,与其他命令配合 |
| grep/egrep | 过滤 | 过滤速度最快 |
| sed | 过滤、取行、替换、删除 | 替换修改文件内容、取行 |
| awk | 过滤、取行、取列、统计计算、判断、循环… | 取行、取列、统计计算 |
- awk是一种语言,叫做单行脚本
1、格式
取出/etc/passwd中的第1行的第1列、第3列和最后一列
awk -F: NR==1{print $1,$3,$NF} ’ /etc/passwd
awk -F: ‘条件{动作}’ /etc/passwd
条件:找谁
动作:干啥
2、awk取行
1️⃣取出/etc/passwd中的第一行
NR:Number of Record 记录号、行号。也可以写大于几行,小于几行
{print $0}:输出整行内容,$0表示当前的内容
## 简写
[root@Ansible-server ~]# awk 'NR==1' /etc/passwd
root:x:0:0:root:/root:/bin/bash
## 完整写法
[root@Ansible-server ~]# awk 'NR==1{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@Ansible-server ~]# awk 'NR>=6{print $0}' /etc/passwd
2️⃣取/etc/passwd出2-5行的内容
&&:表示并且,and
||:表示或者,or
[root@Ansible-server ~]# awk 'NR>=2 && NR<=5{print $0}' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
3️⃣过滤出/etc/passwd文件中包含root或者nobody的行
[root@Ansible-server ~]# awk '/root|nobody/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
nobody:x:65534:65534:Kernel Overflow User:/:/sbin/nologin
stap-server:x:155:155:Systemtap Compile Server:/opt/rh/gcc-toolset-11/root/var/lib/stap-server:/sbin/nologin
4️⃣从包含root的行开始输出到包含nobody的行,可以使用这个功能实现截取一个时间段的日志
[root@Ansible-server ~]# awk '/root/ , /nobody/' /etc/passwd
-
小结
-
awk+NR:取出指定的行,指定范围的行
-
awk+//:过滤
-
awk+其他变量:用于精确过滤(讲完取列就可以使用)
[root@Ansible-server ~]# awk -F: '$3==0' /etc/passwd root:x:0:0:root:/root:/bin/bash
-
3、awk取列
1️⃣使用awk取出
ls -lh的表示大小的列和最后一列
- NF:表示有多少列
- $NF:最后一列
[root@Ansible-server opt]# ls -lh | awk '{print $5,$9}'
[root@Ansible-server opt]# ls -lh | awk '{print $5,$NF}'
49 a.txt
4.0K mplayer
2.1K passwd
93 rh
12G rhel8.8.iso
74 sed.txt
[root@Ansible-server opt]# ls -lh | awk 'NR>1{print $5,$NF}' | column -t
49 a.txt
4.0K mplayer
2.1K passwd
93 rh
12G rhel8.8.iso
74 sed.txt
[root@Ansible-server opt]# echo 123 355 6667 87678 23 | awk '{print $(NF-1),$NF}'
87678 23
2️⃣取出/etc/passwd中第一列、第三列和第五列
-F:指定列之间的分隔符,如果不加-F则默认是空格,-F也支持正则指定分隔符
[root@Ansible-server opt]# awk -F: '{print $1,$3,$NF}' /etc/passwd | column -t
3️⃣指定复杂分隔符取出IP
⚠️在inet前有多个空格,对于awk,如果使用-F参数,每遇到一个空格就切一刀,因此为了实现把所有连续的空格作为一个整体一起切断,我们需要在正则匹配分隔符时加上+号。
[root@Ansible-server opt]# ip address show ens160 | awk 'NR==4' | awk '{print $2}' | awk -F'/' '{print $1}'
192.168.121.141
## 进行简化
[root@Ansible-server opt]# ip address show ens160 | awk 'NR==4' | awk -F'[ /]+' '{print $3}'
192.168.121.141
[root@Ansible-server opt]# ip address show ens160 | awk 'NR==4' | awk -F'inet |/24' '{print $2}'
192.168.121.141
- 小结
- 如果是空格、连续空格,直接使用awk取列即可
- 其他情况使用-F指定分隔符,必要时加正则实现
4、awk取行取列
awk 格式 ‘条件{动作}’
🌟🌟🌟🌟🌟取行+取列 取IP地址
[root@Ansible-server opt]# ip address show ens160 | awk -F'[ /]+' 'NR==4{print $3}'
192.168.121.141
🌟🌟🌟🌟🌟对列的判断,取出/etc/passwd文件中第三列大于1000的行,取出这些行的第一列、第三列和最后一列
[root@Ansible-server opt]# awk -F: '$3>1000{print $1,$3,$NF}' /etc/passwd | column -t
nobody 65534 /sbin/nologin
xiaoli 1001 /bin/bash
xiaowang 1002 /bin/bash
如果系统swap使用超过0则输出异常
- 条件
- 过滤出swap
- 第三列,大于0
- 动作
- 输出“异常”
[root@Ansible-server ~]# free | awk 'NR==3 && $3>0 {print "异常"}'
过滤出/etc/passwd第四列的数字是以0或1开头的行,输出第一列、第三列、第四列
🍃awk中通过~可以实现对某一列进行过滤
某一列中含有xxx内容:
- ~ 表示包含的意思 $1 ~ /root/ 表示第一列中包含root
- !~表示不包含
- 之前^和$表示某一行的开头或者结尾
- 在awk中因为awk可以取列,通过列可以过滤出一列中包含什么…过滤出一列中以xxxx开头或者结尾的行
[root@Ansible-server ~]# awk -F: '$4 ~ /^[01]/ {print $1,$3,$4}' /etc/passwd | column -t
5、awk统计和计算
awk进行统计有两类案例:
1️⃣类似于
wc -l统计次数2️⃣进行累加、求和
(1)、统计次数
统计/etc/passwd中的行数
使用awk进行行数统计
⚠️由于awk的执行过程是一行一行的读取,END后面的内容是要在所有的行都读取完成后在执行
[root@Ansible-server ~]# awk '{i=i+1} END{print i}' /etc/passwd
40
(2)、累加、求和
[root@Ansible-server ~]# seq 10 | awk '{sum=sum+$1}END{print sum}'
55
6、awk总结
- 核心:awk取行取列
- 熟悉:awk对列比较大小
- 熟悉:awk对列进行过滤计算
- 难点:awk计算、求和
二十三、三剑客练习题
【1】、练习1
过滤出/etc/passwd中包含的root和nobody的行
egrep 'root|nobody' /etc/passwd
sed -r '/root|nobody/p' /etc/passwd
sed -r '/root|nobody/!d' /etc/passwd
awk '/root|nobody/' /etc/passwd
过滤出/etc/passwd中以root开头的行
egrep '^root' /etc/passwd
sed '^root' /etc/passwd
sed -r '/^root/!d' /etc/passwd
egrep '/^root/' /etc/passwd
在/etc/ssh/sshd_config中过滤出包含permitrootlogin或usedns的行(忽略大小写)
egerp -i 'permitrootlogin|usedns' /etc/ssh/sshd_config
sed -r -n '/permitrootlogin|usedns/Ip' /etc/ssh/sshd_config
## I忽略大小写
sed -r '/permitrootlogin|usedns/I!d' /etc/ssh/sshd_config
awk -vIGNORECASE=1 '/permitrootlogin|usedns/' /etc/ssh/sshd_config
取出/etc/passwd中以bash结尾的行
egrep 'bash$' /etc/passwd
sed -rn '/bash$/p' /etc/passwd
sed -r '/bash$/!d' /etc/passwd
awk '/bash$/' /etc/passwd
显示/etc/下面一层中以.conf结尾的文件
ls /etc/ | grep '\.conf$'
ls /etc/ | sed '\.conf$'
ls /etc/ | awk '\.conf$'
find /etc/ -maxdepth 1 -type f -name '*.conf'
使用yum安装软件失败了,如何检查是否能联网
[root@Ansible-server ~]# ping mirrors.aliyun.com
使用grep取出/etc/passwd第一列数据
[root@Ansible-server ~]# awk -F: '{print $1}' /etc/passwd
[root@Ansible-server ~]# grep -Po '^[\w-]+' /etc/passwd
[root@Ansible-server ~]# egrep -o '^[^:]+' /etc/passwd
[root@Ansible-server ~]# sed 's/:.*$//g' /etc/passwd
## 后向引用
[root@Ansible-server ~]# sed -r 's#(^[^:]+)(:.*$)#\1#g' /etc/passwd
把上题结果写入文件中
[root@Ansible-server ~]# sed -r 's#(^[^:]+)(:.*$)#\1#g' /etc/passwd > ./a.txt
如何查看文件内容,命令有什么?
## 查看文件
vim vi cat head tail more less grep awk sed
## 查看日志
head tail less more grep sed awk
查看文件1-3行和最后一行
## 查看文件1-3行
head -3 a.txt
sed -n '1,3p' a.txt
awk 'NR>=1&&NR<=3' a.txt
## 查看文件最后一行
tail -1 a.txt
sed -n '$p' a.txt
awk 'END{print}' a.txt
取出/etc/passwd文件中每个字符,过滤后统计出每个字符出现的次数,取出出现次数最多的前10名
[root@Ansible-server ~]# grep -o '.' /etc/passwd | sort | uniq -c| sort -rn| head -5
222 :
163 n
147 /
142 s
142 o
取出/etc/passwd文件中每个单词,过滤后统计出每个字符出现的次数,取出出现次数最多的前5名
[root@Ansible-server ~]# egrep -o '[a-Z]+' /etc/passwd | sort | uniq -c| sort -rn| head -5
39 sbin
37 x
33 nologin
14 var
8 User
【2】、练习2
下面所有的练习均是基于/etc/passwd文件进行
删除文件每一行的第一个字符
[root@Ansible-server ~]# sed 's#^.##g' /etc/passwd
## 使用后向引用实现
[root@Ansible-server ~]# sed -r 's#(^.)(.*$)#\2#g' /etc/passwd
删除文件每一行的第二个字符
[root@Ansible-server ~]# sed -r 's#(^.)(.)(.*$)#\1\3#g' /etc/passwd
删除文件每一行的最后一个字符
[root@Ansible-server ~]# sed 's#.$##g' /etc/passwd
删除文件每一行的第二个单词
[root@Ansible-server ~]# sed -r 's#([a-Z]+)([:-_])([a-Z]+)(.*$)#\1\2\4#g' /etc/passwd
[root@Ansible-server ~]# sed -r 's#(^[a-Z]+)([^a-Z]+)([a-Z]+)(.*$)#\1\2\4#g' /etc/passwd
删除文件每一行的倒数第二个单词
[root@Ansible-server ~]# sed -r 's#([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+$)#\1\3\4#g' /etc/passwd
删除文件每一行的最后一个单词
[root@Ansible-server ~]# sed -r 's#[a-Z]+$##g' /etc/passwd
交换每一行的第一个字符和第二个字符
[root@Ansible-server ~]# sed -r 's#^([a-Z])([a-Z])#\2\1#g' /etc/passwd
交换每一行第一个字符和第二个单词调换位置
[root@Ansible-server ~]# sed -r 's#^(.)(.*:)(x)#\3\2\1#' /etc/passwd
交换每行第一个单词和最后一个单词
[root@Ansible-server ~]# sed -r 's#(^[a-Z]+)(.*/)([a-Z]+$)#\3\2\1#g' /etc/passwd
删除文件中所有的数字
⚠️不可以使用/d去删除
因为在sed中/d是基于一整行去删除的
[root@Ansible-server ~]# sed -r 's#[0-9]##g' /etc/passwd
用制表符替换文件中出现的所有的空格
[root@Ansible-server ~]# sed 's# #\t#g' /etc/passwd
把所有的大写字母用括号括起来
[root@Ansible-server ~]# sed -r 's#([A-Z])#(\1)#g' /etc/passwd
打印每行三次
[root@Ansible-server ~]# sed -n 'p;p;p' /etc/passwd
隔行删除
[root@Ansible-server ~]# seq 10 | sed '1~2d'
2
4
6
8
10
只显示每行第一个单词
[root@Ansible-server ~]# grep -Po '^\w+' /etc/passwd
[root@Ansible-server ~]# egrep -o '^[a-Z]+' /etc/passwd
打印每行第一个单词和第三个单词
[root@Ansible-server ~]# sed -r 's#(^[a-Z]+)[^a-Z]+([a-Z]+)[^a-Z]+([a-Z]+).*$#\1_\3#g' /etc/passwd
【3】、练习3
将格式xx/xx/xx/替换为xx:xx:xx
sed 's#/#:#g' a.txt
找出系统中UID在100-500的用户名
awk -F: '$3>100 && $3<500{print $1}' /etc/passwd
将域名取出并根据域名进行计数排序处理(souhu和baidu面试题)
[root@Ansible-server ~]# cat url.txt
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
[root@Ansible-server ~]# awk -F/ '{print $3}' url.txt | sort -rn | uniq -c | awk '{print "count:"$1,"url:"$2}'
测试环境信息:
cat >>req.txt<<EOF
Zhang Dandan 41117397 :250💯175Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250💯175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youiiu 918391635 :175:75:300
Lao Nanhai 918391635 :250💯175
EOF测验题目
1、显示Xiaoyu的姓氏和id号码
awk '$2~/Xiaoyu/{print $1,$2,$3}' req.txt2、显示姓氏是Zhang,显示他第二次捐款金额及他的名字
awk -F[ :] '/^Zhang/{print $2,$(NF-1)}' req.txt3、显示所有以41开头的id号码的人的全名和id号码
awk '$3~/^41/{print $1,$2,$3}' req.txt4、显示所有id号码最后一位是1或5的人的全名
[root@Ansible-server ~]# awk '$3~/(1|5)$/{print $1,$2}' req.txt5、显示Xiaoyu的捐款,每个值前面都以$开头
sed -n '/^Zhang Xiaoyu/p' req.txt | awk -F: '{print "$"$2,"$"$3,"$"$4}' # 另外一种方式,awk也可以实现替换功能,通过gsub函数 [root@Ansible-server ~]# sed -n '/^Zhang Xiaoyu/p' req.txt | awk '{gsub(":","$",$NF);print $4}' $155$90$201
【4】、终极测验
统计access.log网站服务访问日志信息
1、每个IP地址的访问次数(第一列)
awk '{print $1}' access.log | sort | uniq -c | sort -rn | head
2、一共使用了多少流量(第十列)
awk '{i=i+$10}END{print i}' access.log
3、每个状态码出现的次数(第九列)
awk '{print $9}' access.log | sort | uniq -c | sort -rn | head
4、图片占用的流量(第七列中以.jpg或.png或.gif结尾的,第十列是流量)
awk '$7~/\.(png|jpg|gif)/{sum+=$10}END{print sum/1024^3}' access.log
918391635 :175:75:300
Lao Nanhai 918391635 :250💯175
EOF测验题目
1、显示Xiaoyu的姓氏和id号码
awk '$2~/Xiaoyu/{print $1,$2,$3}' req.txt2、显示姓氏是Zhang,显示他第二次捐款金额及他的名字
awk -F[ :] '/^Zhang/{print $2,$(NF-1)}' req.txt3、显示所有以41开头的id号码的人的全名和id号码
awk '$3~/^41/{print $1,$2,$3}' req.txt4、显示所有id号码最后一位是1或5的人的全名
[root@Ansible-server ~]# awk '$3~/(1|5)$/{print $1,$2}' req.txt5、显示Xiaoyu的捐款,每个值前面都以$开头
sed -n '/^Zhang Xiaoyu/p' req.txt | awk -F: '{print "$"$2,"$"$3,"$"$4}' # 另外一种方式,awk也可以实现替换功能,通过gsub函数 [root@Ansible-server ~]# sed -n '/^Zhang Xiaoyu/p' req.txt | awk '{gsub(":","$",$NF);print $4}' $155$90$201
【4】、终极测验
统计access.log网站服务访问日志信息
1、每个IP地址的访问次数(第一列)
awk '{print $1}' access.log | sort | uniq -c | sort -rn | head
2、一共使用了多少流量(第十列)
awk '{i=i+$10}END{print i}' access.log
3、每个状态码出现的次数(第九列)
awk '{print $9}' access.log | sort | uniq -c | sort -rn | head
4、图片占用的流量(第七列中以.jpg或.png或.gif结尾的,第十列是流量)
awk '$7~/\.(png|jpg|gif)/{sum+=$10}END{print sum/1024^3}' access.log

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









