




 本文详细介绍如何使用Hive SQL进行数据处理,包括启动metastore服务、建表、加载数据、使用HQL进行数据查询和分析,以及常见异常处理。通过具体实例,展示如何将文本文件中的数据加载到Hive表,并利用HQL进行单词分割和计数,对比传统MapReduce编程,Hive SQL提供更为简便高效的数据处理方式。
本文详细介绍如何使用Hive SQL进行数据处理,包括启动metastore服务、建表、加载数据、使用HQL进行数据查询和分析,以及常见异常处理。通过具体实例,展示如何将文本文件中的数据加载到Hive表,并利用HQL进行单词分割和计数,对比传统MapReduce编程,Hive SQL提供更为简便高效的数据处理方式。
1. 启动metastore服务
./hive --service metastore &
2. 建表
创建一个行表,用于存储foobar.txt文件中的每行句子。
create table tbl_line(line string)
row format delimited
fields terminated by '\n';
3. 加载数据
将文件数据加载到hive表中。
echo "Hadoop Common\nHadoop Distributed File System\nHadoop YARN\nHadoop MapReduce " > /tmp/foobar.txt
hive> load data local inpath '/tmp/foobar.txt' into table tbl_line;
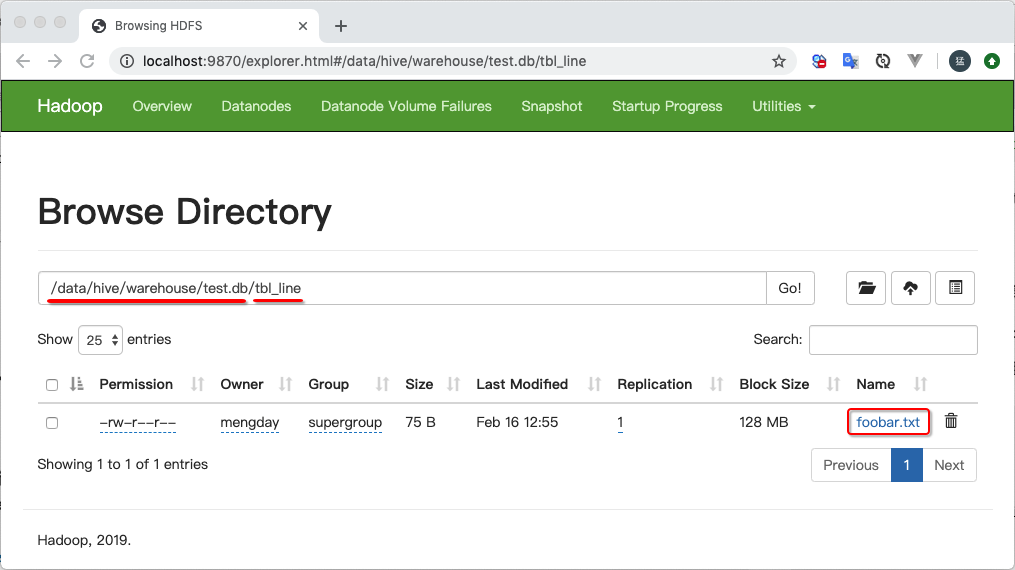
加载的数据会放到Hadoop中/data/hive/warehouse/test.db目录下,/data/hive/warehouse是hive-site.xml配置的hive.metastore.warehouse.dir值, test是数据库名称, tbl_line是表名。
4. HQL
根据MapReduce方式我们需要将每行句子拆分成独立的单词,然后对单词汇总。
- split(字符串,分割符) 函数:用于分割字符串, 返回一个数组
- explode(数组)函数:将数组中的每个元素展开成列
hive> select split("hello world", " ") from tbl_line limit 1;
OK
["hello","world"]
hive> select * from tbl_line;
OK
Hadoop Common
Hadoop Distributed File System
Hadoop YARN
Hadoop MapReduce
# 将每行句子分割成每个单词数组
hive> select split(line, " ") from tbl_line;
OK
["Hadoop","Common"]
["Hadoop","Distributed","File","System"]
["Hadoop","YARN"]
["Hadoop","MapReduce",""]
hive> select explode(split(line, " ")) from tbl_line;
OK
Hadoop
Common
Hadoop
Distributed
File
System
Hadoop
YARN
Hadoop
MapReduce
# 创建一个单词表
hive> create table tbl_word(word string);
# 将每一行句子拆分成每个单词插入到表中
hive> insert into table tbl_word select explode(split(line, " ")) as word from tbl_line;
hive> select * from tbl_word;
OK
Hadoop
Common
Hadoop
Distributed
File
System
Hadoop
YARN
Hadoop
MapReduce
hive> select word, count(*) as count from tbl_word group by word order by count desc;
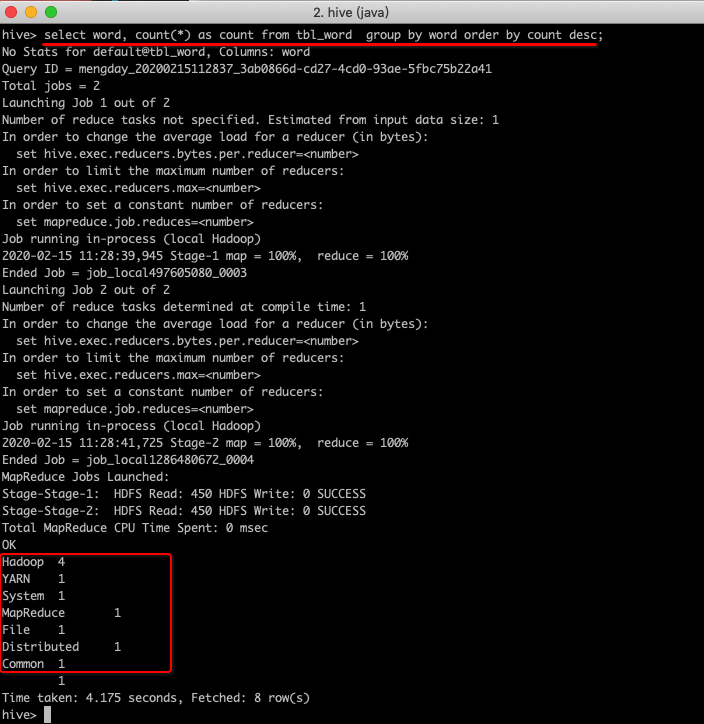
使用Hadoop MapReduce需要写代码,然后执行jar包。使用Hive只需要写HQL就可以了。相比之下使用Hive SQL更简便。
5. 异常
-
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
./hive --service metastore & -
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)Lorg/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat;
此异常是最常见的异常,这里列举出现此异常的几个原因:
- 有可能是hql语法有错误,确保语法是正确。
- hadoop 中lib/native有问题,把lib重命名成lib2,然后重启hadoop,再执行hive sql就好了,相当于不使用原生库了lib/native。不使用原生库hadoop就会报警告 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable ,先不用管这个警告。


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











