




机器学习入门01
- 准备工作:下载iris.data.csv文件(其实就是excel文件)
下载链接
如下图

# 01.导入类库
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
# 02.导入数据
filename="iris.data.csv"
names= ['separ-length','separ-width','petal-length','petal-width','class']
dataset=read_csv(filename,names=names
)
# 03.显示数据维度
print('数据维度:行%s,列%s'% dataset.shape)
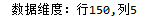
# 04.查看数据前10行
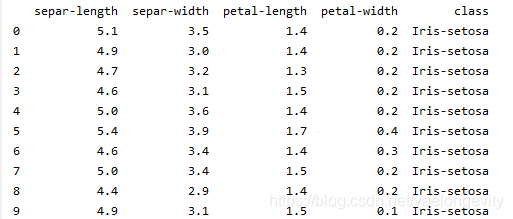
print(dataset.head(10))
# 05.统计描述数据信息
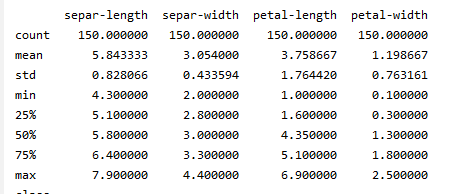
print(dataset.describe())
# 06.分类分布情况
print(dataset.groupby('class').size())

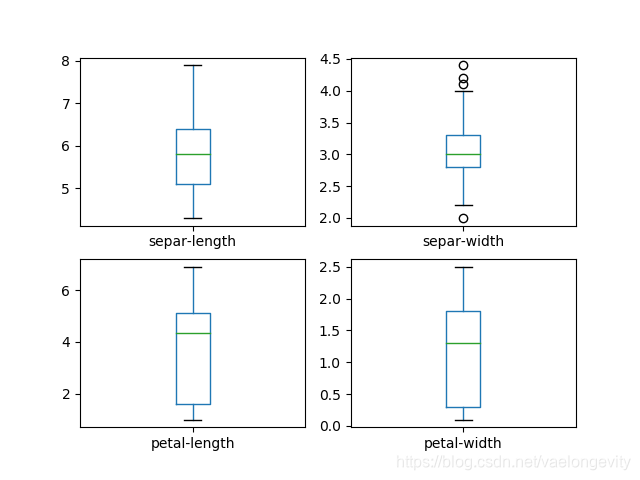
# 07.箱线图
dataset.plot(kind='box',subplots=True,layout=(2,2),sharex=False,sharey=False)
pyplot.show()
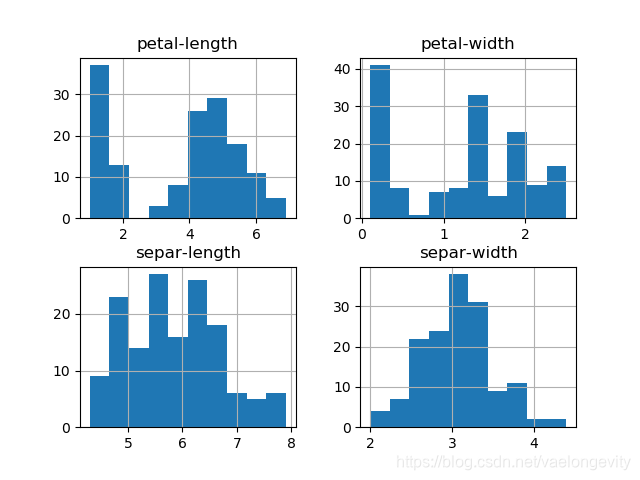
# 08.直方图
dataset.hist()
pyplot.show()
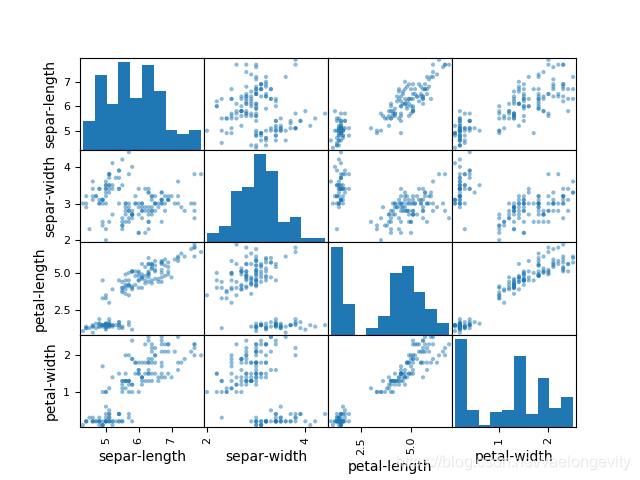
# 09.散点矩阵图
scatter_matrix(dataset)
pyplot.show()
# 10.分离数据集
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.2
seed = 7
X_train,X_validation,Y_train,Y_validation = \
train_test_split(X,Y,test_size=validation_size,random_state=seed)
# 11.算法审查
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] =SVC()
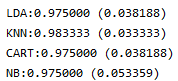
# 12.评估算法
results = []
for key in models:
kfold = KFold(n_splits=10,random_state=seed)
cv_results = cross_val_score(models[key],X_train,Y_train,cv =kfold ,scoring="accuracy" )
results.append(cv_results)
print('%s:%f (%f)'%(key,cv_results.mean(),cv_results.std()))
完整代码如下:”
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
# 02.导入数据
filename="iris.data.csv"
names= ['separ-length','separ-width','petal-length','petal-width','class']
dataset=read_csv(filename,names=names
)
# 03.显示数据维度
print('数据维度:行%s,列%s'% dataset.shape)
# 04.查看数据前10行
print(dataset.head(10))
# 05.统计描述数据信息
print(dataset.describe())
# 06.分类分布情况
print(dataset.groupby('class').size())
# 07.箱线图
dataset.plot(kind='box',subplots=True,layout=(2,2),sharex=False,sharey=False)
pyplot.show()
# 08.直方图
dataset.hist()
pyplot.show()
scatter_matrix(dataset)
pyplot.show()
# 10.分离数据集
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.2
seed = 7
X_train,X_validation,Y_train,Y_validation = \
train_test_split(X,Y,test_size=validation_size,random_state=seed)
# 11.算法审查
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] =SVC()
# 12.评估算法
results = []
for key in models:
kfold = KFold(n_splits=10,random_state=seed)
cv_results = cross_val_score(models[key],X_train,Y_train,cv =kfold ,scoring="accuracy" )
results.append(cv_results)
print('%s:%f (%f)'%(key,cv_results.mean(),cv_results.std()))

















 8750
8750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









