










NLP-大语言模型学习系列目录
一、注意力机制基础——RNN,Seq2Seq等基础知识
二、注意力机制【Self-Attention,自注意力模型】
三、Transformer图文详解【Attention is all you need】
文章目录
🚀在自然语言处理(NLP)领域,Transformer架构已经成为最先进的技术之一,其核心概念是自注意力机制(Self-Attention Mechanism)。
📚在前面的两小节中,我们已经介绍了注意力机制的基础知识,包括RNN、Seq2Seq等传统方法的基本概念和实现。此外,我们详细讨论了自注意力机制(Self-Attention)及其在现代NLP模型中的重要性。自注意力机制允许模型在处理每个输入时“关注”输入序列的不同部分,从而理解单词与其他单词之间的关系,而不是逐个地线性处理输入。
🔥在理解了自注意力机制的基础上,我们来介绍大语言模型的基础——Transformer结构,Attention is all you need!
❗️Note
本文中很多图都来自The Illustrated Transformer,Python代码来自The Annotated Transformer。为了防止文章过于冗长,只放了部分代码帮助理解原理,当原理读完后,建议完整过一遍The Annotated Transformer上面的代码,十分详细。
一、Transformer框架
Transformer 的核心概念是 自注意力机制(Self-Attention Mechanism),它允许模型在处理每个输入时“关注”输入序列的不同部分。这种机制让模型能够理解每个单词或符号与其他单词或符号之间的关系,而不是逐个地线性处理输入。原始论文给出的Transformer结构如下图所示:
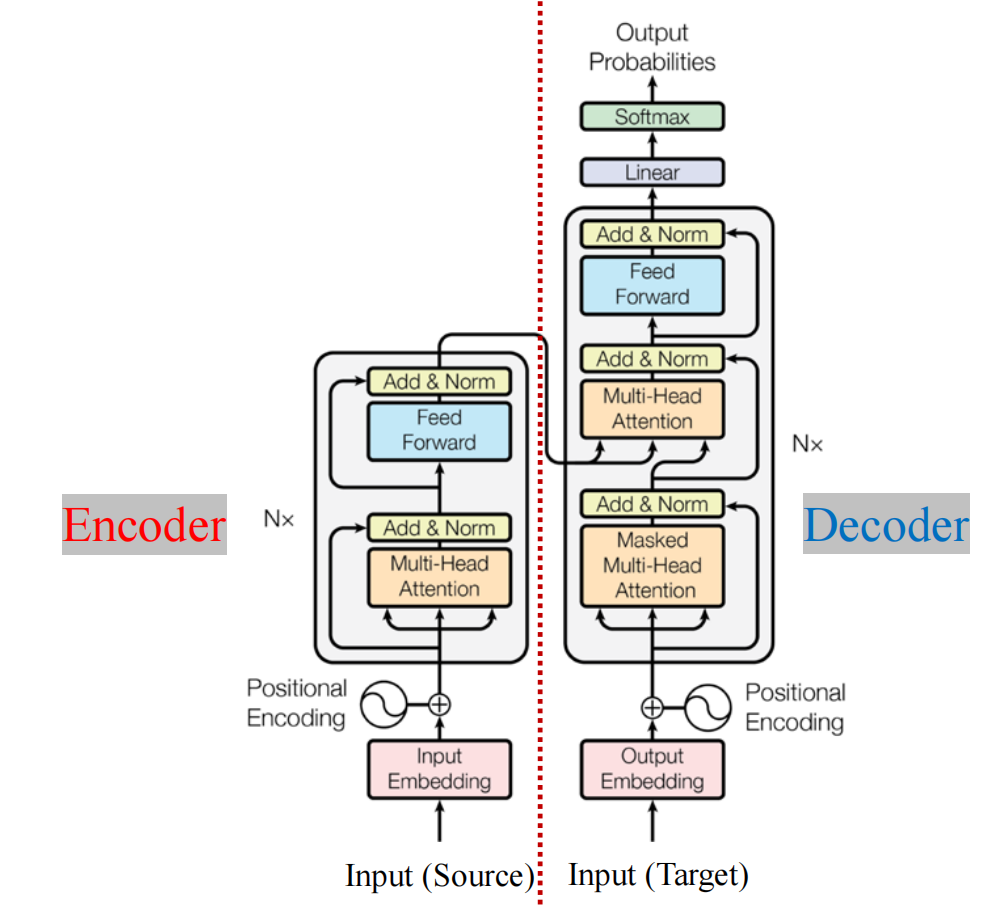
上图所示的Transformer 主要由两个部分组成:
- 编码器(Encoder):将输入序列转换为一个隐表示(向量表示);
- 解码器(Decoder):从隐表示生成输出序列.
编码器 和 解码器 都由多个层(layers) 组成,每层都包括:
- 一个 多头自注意力机制 ;
- 一个 前馈神经网络(Feed-Forward Neural Network, FFN);
- 残差结构以及层归一化操作.
下面详细分析Transformer结构每个部分的作用及计算过程。
二、Encoder
(一)自注意力机制
在上一小节我们详细介绍了注意力机制,本节我们仅介绍其在Transformer结构中的计算过程。对于输入序列 X = [ x 1 , x 2 , … , x n ] T ∈ R n × d m o d e l \mathbf{X}=[x_1,x_2,\ldots,x_n]^{T}\in\mathbb{R}^{n\times d_{model}} X=[x1,x2,…,xn]T∈Rn×dmodel,其中:
- n n n是序列长度
- d m o d e l d_{model} dmodel是词向量嵌入维度
每个元素 x i x_i xi首先被投影到三个不同的向量 :1查询向量(Query)—Q;2键向量( Key) —K;3值向量( Value) —V.
这些向量的计算公式如下:
Q = X W Q ∈ R n × d q , K = X W K ∈ R n × d k , V = X W V ∈ R n × d v \mathbf{Q}=\mathbf{X}\mathbf{W}^Q\in\mathbb{R}^{n\times d_q},\quad\mathbf{K}=\mathbf{X}\mathbf{W}^K\in\mathbb{R}^{n \times d_k},\quad\mathbf{V}=\mathbf{X}\mathbf{W}^V\in\mathbb{R}^{n\times d_v} Q=XWQ∈Rn×dq,K=XWK∈Rn×dk,V=XWV∈Rn×dv
其中, W Q ∈ R d m o d e l × d k , W K ∈ R d m o d e l × d k , W V ∈ R d m o d e l × d v \mathbf{W}^Q\in\mathbb{R}^{d_{model}\times d_k},\mathbf{W}^K\in\mathbb{R}^{d_{model}\times d_k},\mathbf{W}^V\in\mathbb{R}^{d_{model}\times d_v} WQ∈Rdmodel×dk,WK∈Rdmodel×dk,WV∈Rdmodel×dv是可学习的权重矩阵。通常来说:
- d q = d k d_q=d_k dq=dk
- d v = d m o d e l d_v=d_{model} dv=dmodel
自注意力的核心公式是计算每个查询向量与所有键向量之间的相似度,原文采用的是缩放点积模型 :
Z
=
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
Z=\text{Attention}(\mathbf{Q},\mathbf{K},\mathbf{V})=\text{softmax}\biggl(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}}\biggr)\mathbf{V}
Z=Attention(Q,K,V)=softmax(dkQKT)V
其中:
- 我们记 A = Q × K T ∈ R n × n A=Q\times K^T\in \mathbb{R}^{n\times n} A=Q×KT∈Rn×n,矩阵 A A A就是一个序列中词与词之间的注意力分数, A A A的每一行对应一个查询向量与 K K K计算得到的注意力分数(矩阵相乘的行向量视角去看);
- 我们记 softmax ( A d k ) = B ∈ R n × n \text{softmax}(\frac{A}{\sqrt{d_k}})=B\in\mathbb{R}^{n\times n} softmax(dkA)=B∈Rn×n是对 A A A的每一行进行softmax,我们需要为每一个查询向量生成对所有键向量的权重分布,这些权重表示当前查询对所有键的“关注度”。因此,对于每个查询向量,它对应的所有键的得分需要通过 Softmax 归一化为一个概率分布;
- B × V = Z ∈ R n × d m o d e l B\times V=Z\in\mathbb{R}^{n\times d_{model}} B×V=Z∈Rn×dmodel,仍然从行向量视角去看这个乘法,Z的每一行(对应一个查询)包含该查询与所有键的注意力权重。我们用这些注意力权重对值向量 V V V 的每一行进行加权求和,得到每个查询的输出。
- 所以Attention本质上是一种归约操作(reduce),虽然自注意力机制的输出通常与输入的长度相同,但每个输出都是对整个输入序列的归约和聚合的结果。因此,每个输出向量都可以被视为整个序列信息的一个“压缩版”或“摘要”。
这里, 1 d k \frac1{\sqrt{d_k}} dk1是缩放因子,用于避免Q和K的点积过大(为了说明为什么点积会随 d k d_k dk的增大而变大,假设 q q q和 k k k为独立随机变量,均值为0,方差为1。然后它们的点积, q ⋅ k q\cdot k q⋅k= ∑ i = 1 d k q i k i \sum_{i=1}^{d_k}q_ik_i ∑i=1dkqiki,其均值为0,方差为 d k d_k dk,为了抵消这种影响,我们将点积乘以 1 d k \frac1{\sqrt{d_k}} dk1), Q K T QK^T QKT过大,会导致softmax函数趋向平缓,导致其导数会很小。softmax 函数将相似度转换为权重,最后乘以 V 得到加权的值向量。下面用一个实例的图示来描述这个计算过程,并且能够清晰的看到各个部分的维度:
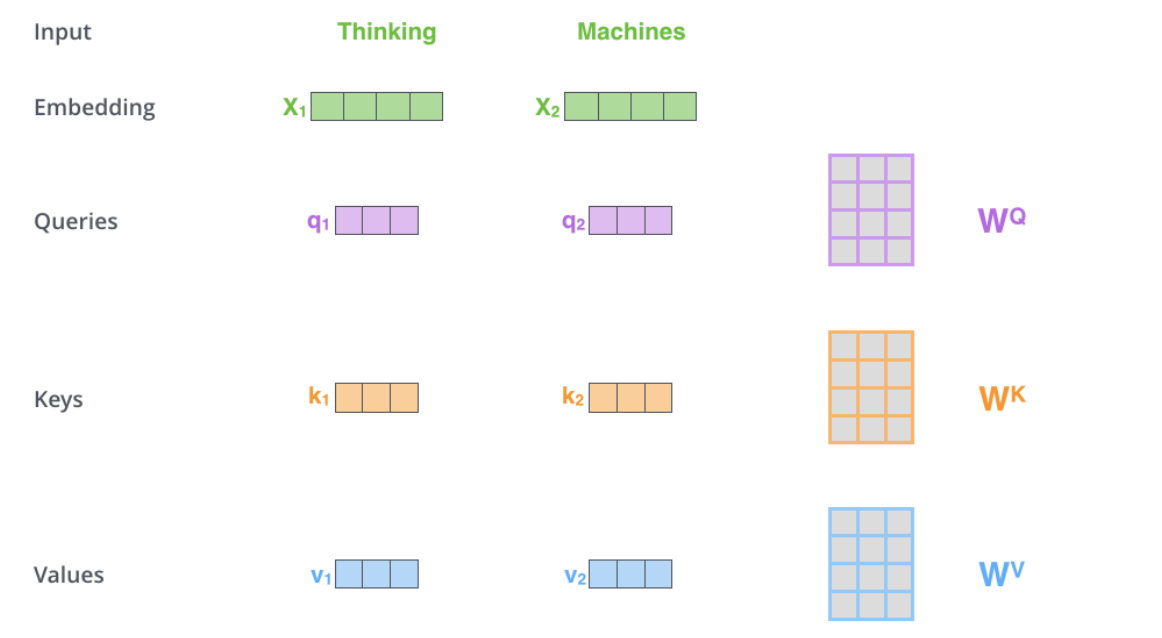
如上图所示, X 1 , X 2 X_1,X_2 X1,X2分别与 W Q , W K , W V \mathbf{W}^Q,\mathbf{W}^K,\mathbf{W}^V WQ,WK,WV相乘可以得到 q 、 k 、 v q、k、v q、k、v,下面假设一些值进行计算:
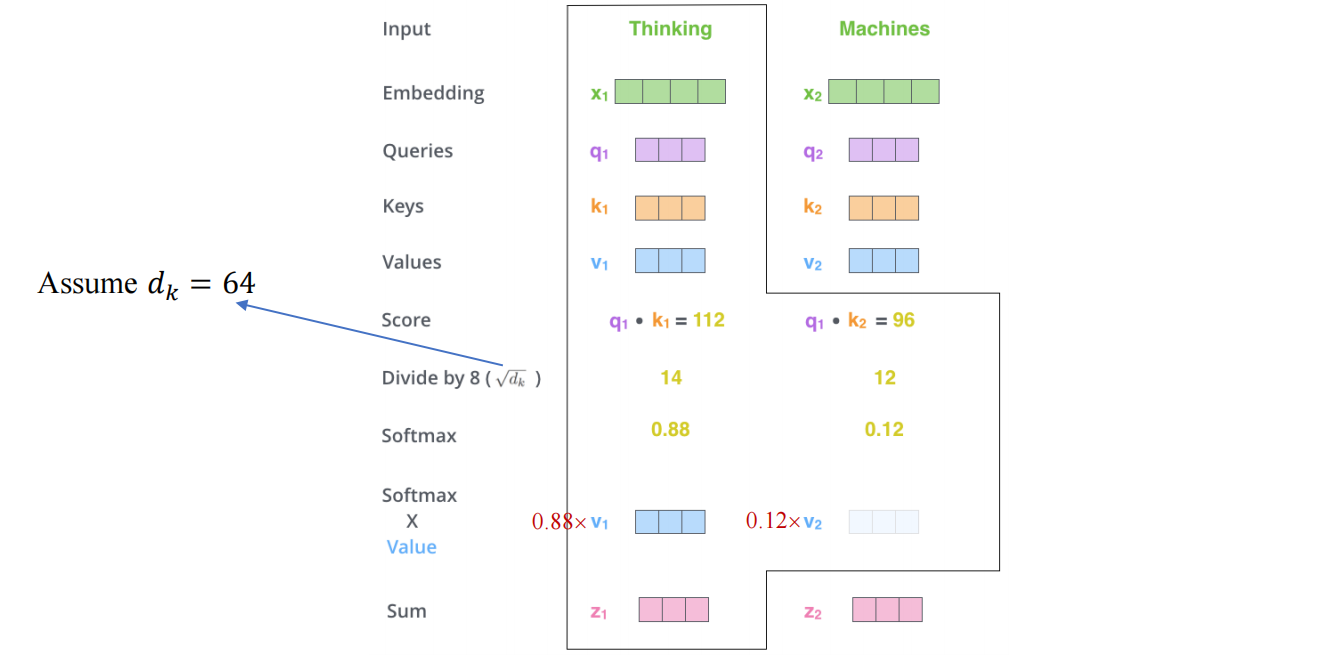
可以看到最后得到的注意力值 z i z_i zi维度和 v i v_i vi的维度一致.如果 X 1 , X 2 X_1,X_2 X1,X2拼接成矩阵,那么其计算过程图示如下:
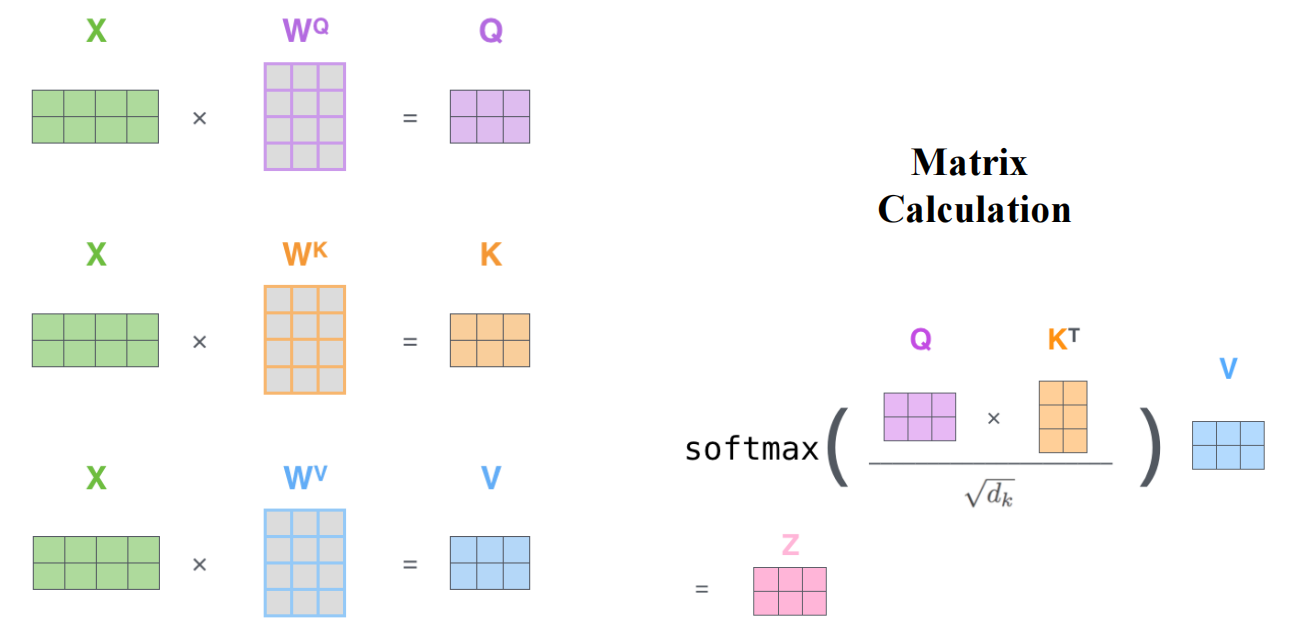
可以看到最后的 Z Z Z就是由 z 1 , z 2 z_1,z_2 z1,z2拼接得到,并且 Z Z Z与 V V V的维度仍保持一致.
(二)多头注意力机制
为了让模型捕捉到不同子空间的特征,多头注意力机制将上述注意力机制应用多个头( head ) :
M u l t i H e a d ( Q , K , V ) = [ h e a d 1 , h e a d 2 , … , h e a d h ] W O \mathrm{MultiHead}( \mathbf{Q} , \mathbf{K} , \mathbf{V} ) = [ \mathrm{head}_1, \mathrm{head}_2, \ldots , \mathrm{head}_h] \mathbf{W} ^O MultiHead(Q,K,V)=[head1,head2,…,headh]WO
其中,每个 head i _i i是一个独立的自注意力机制 :
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) \mathrm{head}_i=\mathrm{Attention}(\mathbf{QW}_i^Q,\mathbf{KW}_i^K,\mathbf{VW}_i^V)\\ headi=Attention(QWiQ,KWiK,VWiV)
W O ∈ R h d v × d m o d e l \mathbf{W}^O\in\mathbb{R}^{hd_v\times d_{model}} WO∈Rhdv×dmodel是用于连接各个头结果的权重矩阵.下面用一个图例来描述多头注意力机制的计算过程:
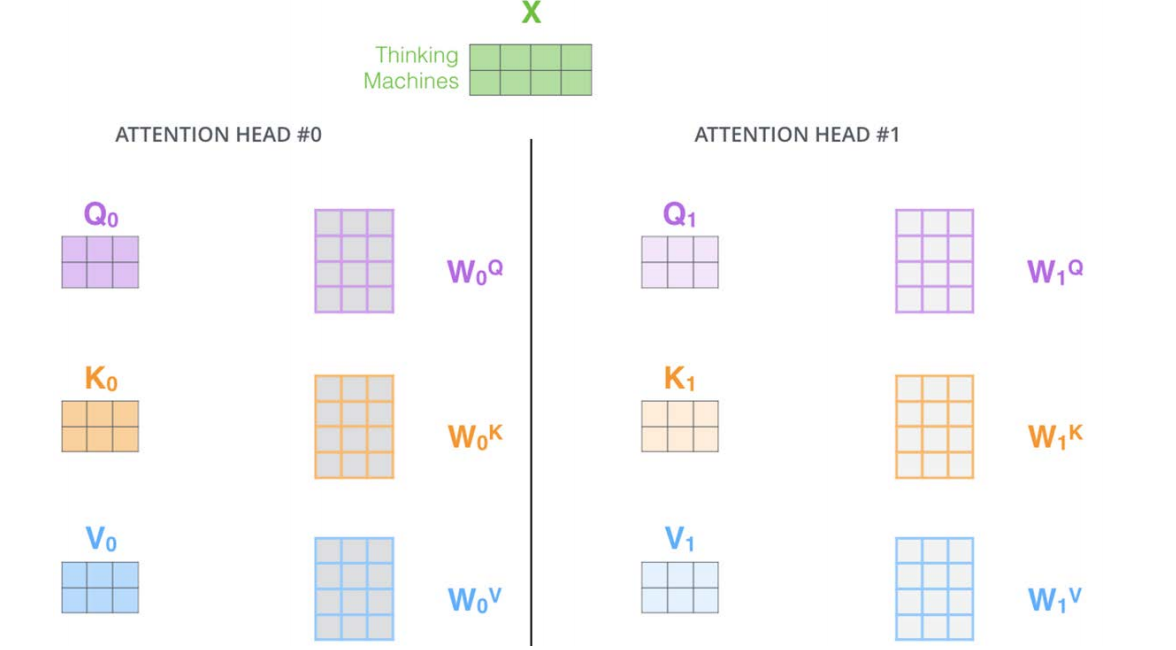
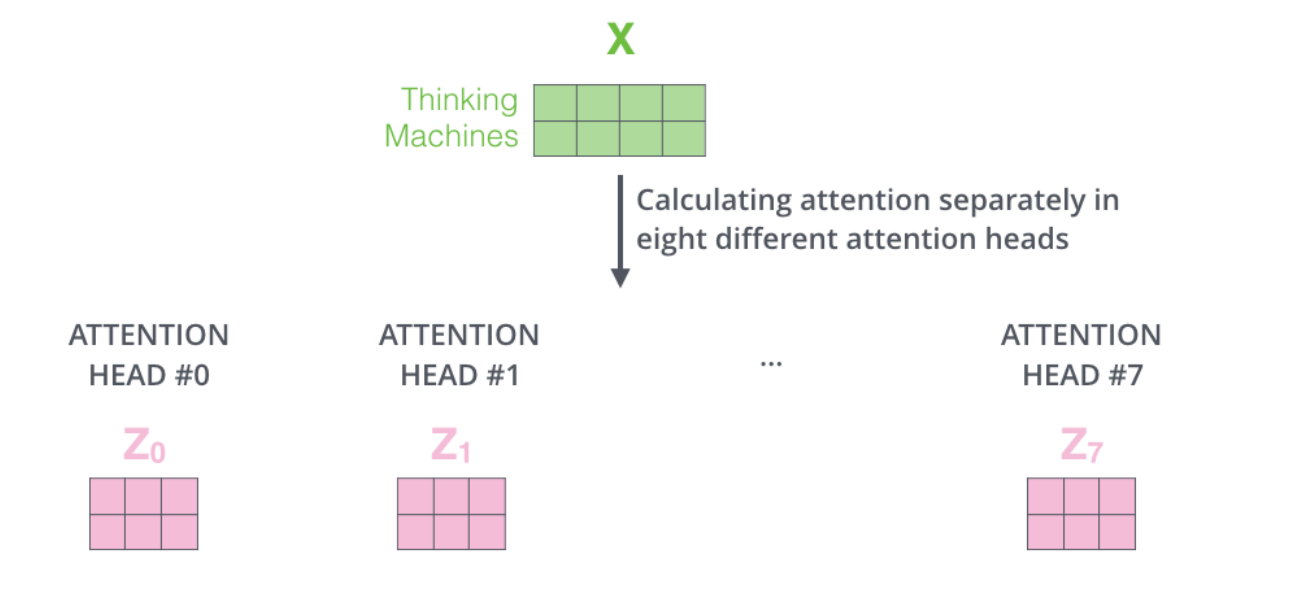
如上图所示, h = 2 h=2 h=2,左右两边结构完全一样,每个head的计算方式也完全一样。当 h = 8 h=8 h=8时,我们可以计算得到8个 Z i Z_i Zi:
多头注意力机制就是将多个head的输出拼接起来,同时再乘以一个大的参数矩阵 W O W^O WO
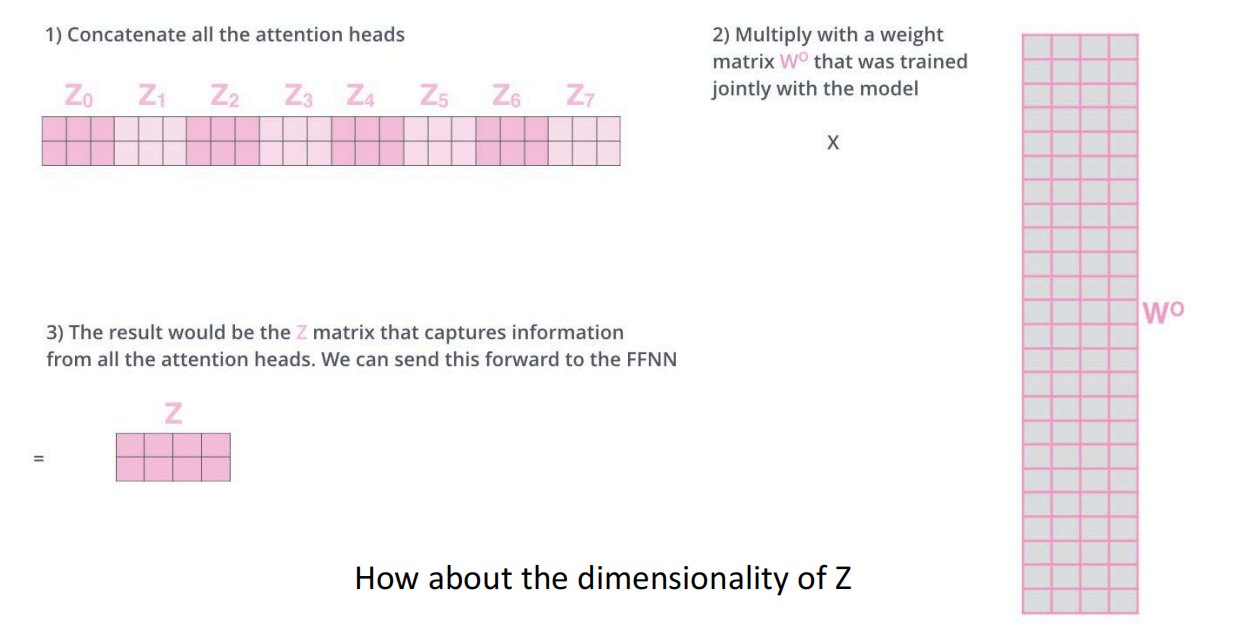
由上图可知,最后得到的 Z Z Z的维度与 X X X的维度保持一致.这是为了方便后面的layer当作输入,在Encoder结构中,只有第一层需要将输入Embedding成 X X X,后面的层直接使用上一层的输出当作输入.下图是一个多头注意力机制计算过程的完整图示:
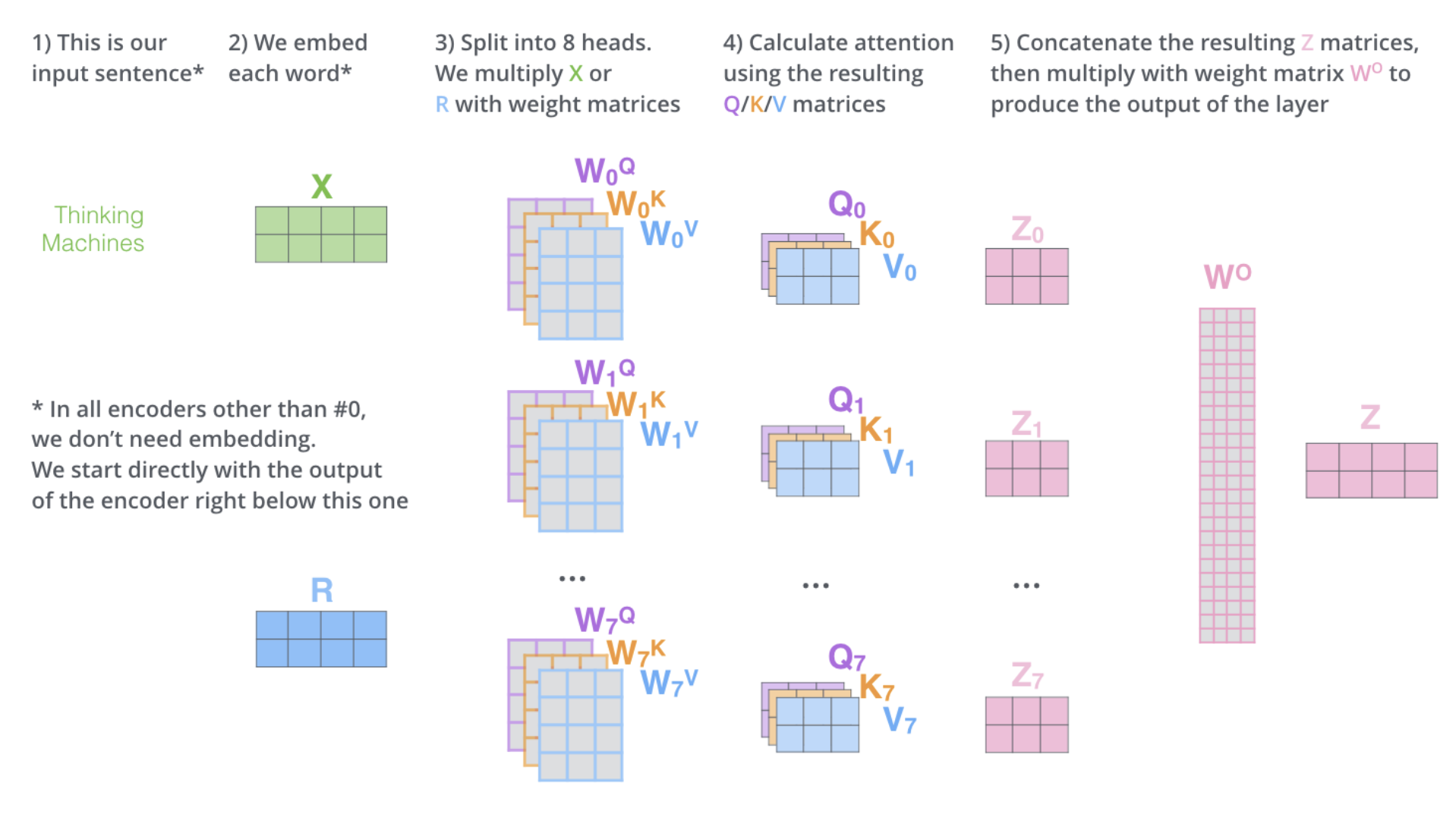
到目前为止介绍的多头注意力机制结构存在两个问题:
- 与循环神经网络不同,自注意力机制并不按顺序构建信息,这个结构没有对输入顺序的内在表示,也就是说,输入的顺序完全不影响网络输出,但是我们知道句子里单词的顺序是重要的。所以Transformer结构中中引入了一个技巧——位置编码(Positional Encoding).
- 注意到在上面的计算过程中,除了Softmax都是线性计算,使得网络的表达能力受限,Transformer中在每个多头注意力机制后引入一个前馈神经网络来增强网络的表示能力.
(三)位置编码
为了编码每个词的位置信息,原始论文中提出用一个新的向量 p i p_i pi来编码位置信息,其维度和Embedding的维度一致,在编码器的第一层,我们将 p i p_i pi与 x i x_i xi叠加得到最终的输入向量矩阵 X X X.
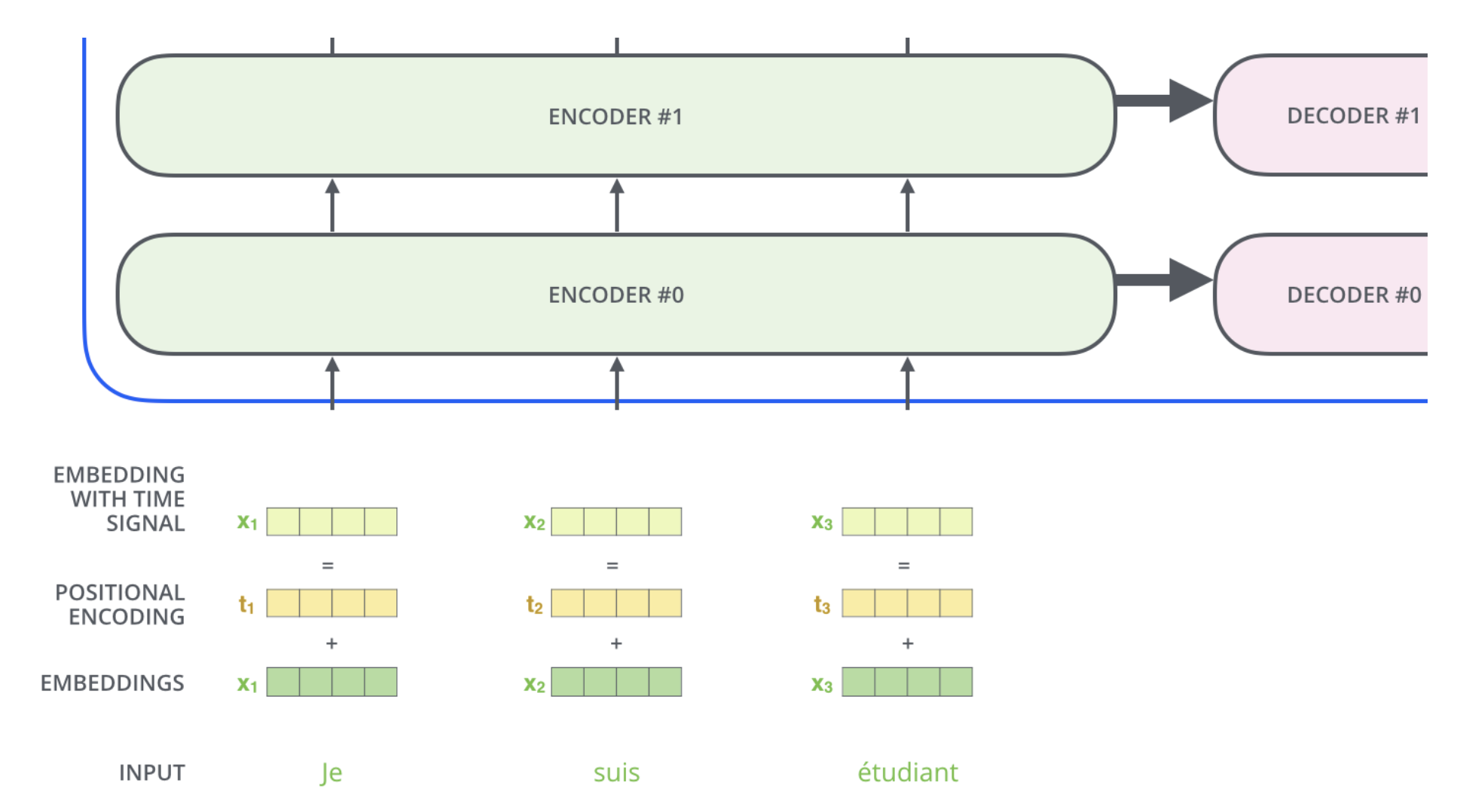
这个位置向量怎么得到呢?原论文给出一种绝对位置编码方式,其计算公式如下:
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d m o d e l ) \begin{aligned}PE_{(pos,2i)}&=\sin(pos/10000^{2i/d_{\mathrm{model}}})\\PE_{(pos,2i+1)}&=\cos(pos/10000^{2i/d_{\mathrm{model}}})\end{aligned} PE(pos,2i)PE(pos,2i+1)=sin(pos/100002i/dmodel)=cos(pos/100002i/dmodel)
其中:
- pos表示单词在句子中的绝对位置,pos=0,1,2…,例如:Jerry在"Tom chase Jerry"中的pos=2;
- d m o d e l d_{model} dmodel表示词向量的维度,在这里 d m o d e l d_{model} dmodel=512;
- 2i和2i+1表示奇偶性,i表示词向量中的第几维,例如这里 d m o d e l d_{model} dmodel=512,故i=0,1,2…255.
绝对位置编码和相对位置编码的区别1:
- 绝对位置编码是固定的向量,添加到词元的嵌入中,用于表示该词元在句子中的绝对位置。因此,它一次只处理一个词元。你可以将其类比为地图上的经纬度对:地球上的每个点都有一个唯一的经纬度对。
- 相对位置编码则一次处理两个词元,并在我们计算注意力时起作用:由于注意力机制捕捉的是两个词之间的“关联强度”,相对位置编码告诉注意力机制这两个词之间的距离。因此,给定两个词元,我们会创建一个表示它们距离的向量
(1)绝对位置编码示例2
如果我们要编码【我爱你】的位置向量, 假定 d m o d e l d_{model} dmodel是512维, 那么三个词向量的位置编码向量计算如下:
- 对 p o s = 0 p o s=0 pos=0 上的单词【我】进行位置编码可得:
P 0 = [ sin ( 0 1000 0 0 512 ) , cos ( 0 1000 0 0 512 ) , sin ( 0 1000 0 1 512 ) , cos ( 0 1000 0 1 512 ) , … , sin ( 0 1000 0 510 512 ) , cos ( 0 1000 0 510 512 ) ] P_{0} = \left[ \sin \left(\frac{0}{10000^{\frac{0}{512}}}\right), \cos \left(\frac{0}{10000^{\frac{0}{512}}}\right), \sin \left(\frac{0}{10000^{\frac{1}{512}}}\right), \cos \left(\frac{0}{10000^{\frac{1}{512}}}\right), \ldots, \sin \left(\frac{0}{10000^{\frac{510}{512}}}\right), \cos \left(\frac{0}{10000^{\frac{510}{512}}}\right) \right] P0=[sin(1000051200),cos(1000051200),sin(1000051210),cos(1000051210),…,sin(100005125100),cos(100005125100)]
- 对 p o s = 1 p o s=1 pos=1 上的单词【爱】进行位置编码可得:
P 1 = [ sin ( 1 1000 0 0 512 ) , cos ( 1 1000 0 0 512 ) , sin ( 1 1000 0 1 512 ) , cos ( 1 1000 0 1 512 ) , … , sin ( 1 1000 0 510 512 ) , cos ( 1 1000 0 510 512 ) ] P_1 = \left[ \sin \left(\frac{1}{10000^{\frac{0}{512}}}\right), \cos \left(\frac{1}{10000^{\frac{0}{512}}}\right), \sin \left(\frac{1}{10000^{\frac{1}{512}}}\right), \cos \left(\frac{1}{10000^{\frac{1}{512}}}\right), \ldots, \sin \left(\frac{1}{10000^{\frac{510}{512}}}\right), \cos \left(\frac{1}{10000^{\frac{510}{512}}}\right) \right] P1=[sin(1000051201),cos(1000051201),sin(1000051211),cos(1000051211),…,sin(100005125101),cos(100005125101)]
同理可得 P 2 P_2 P2……
(2)代码实现2
“”“位置编码的实现,调用父类nn.Module的构造函数”“”
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # 初始化dropout层
# 计算位置编码并将其存储在pe张量中
pe = torch.zeros(max_len, d_model) # 创建一个max_len x d_model的全零张量
position = torch.arange(0, max_len).unsqueeze(1) # 生成0到max_len-1的整数序列,并添加一个维度
# 计算div_term,用于缩放不同位置的正弦和余弦函数
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
# 使用正弦和余弦函数生成位置编码,对于d_model的偶数索引,使用正弦函数;对于奇数索引,使用余弦函数。
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 在第一个维度添加一个维度,以便进行批处理
self.register_buffer('pe', pe) # 将位置编码张量注册为缓冲区,以便在不同设备之间传输模型时保持其状态
# 定义前向传播函数
def forward(self, x):
# 将输入x与对应的位置编码相加
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
# 应用dropout层并返回结果
return self.dropout(x)
对于下面这行代码:
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
这里使用指数和对数运算的原因是为了确保数值稳定性和计算效率:
- 一方面, 直接使用幂运算可能会导致数值上溢或下溢。当d_model较大时, 10000.0^ (-i/d_model)中的幂可能会变得非常小, 以至于在数值计算中产生下溢。通过将其转换为指数和对数运算,可以避免这种情况,因为这样可以在计算过程中保持更好的数值范围
- 二方面, 在许多计算设备和库中, 指数和对数运算的实现通常比幂运算更快。这主要是因为指数和对数运算在底层硬件和软件中有特定的优化实现,而幂运算通常需要计算更多的中间值
上面那行代码对应的公式为
div_term = exp ( [ 0 2 4 ⋮ ( d model − 1 ) ] ⋅ ( − log ( 10000 ) d model ) ) \operatorname{div\_ term}=\exp \left(\left[\begin{array}{c} 0 \\ 2 \\ 4 \\ \vdots \\ \left(d_{\text {model }}-1\right) \end{array}\right] \cdot\left(-\frac{\log (10000)}{d_{\text {model }}}\right)\right) div_term=exp 024⋮(dmodel −1) ⋅(−dmodel log(10000))
其中的中括号对应的是一个从 0 到 d model − 1 d_{\text {model }}-1 dmodel −1 的等差数列(步长为 2 ), 设为 i i i,且上述公式与下面公式等价:
KaTeX parse error: Got function '\left' with no arguments as superscript at position 40: … r m}}_i=10000^\̲l̲e̲f̲t̲(-\frac{i}{d_{\…
为何, 原因在于 a x = e ( x ⋅ ln ( a ) ) a^x=e^{(x \cdot \ln (a))} ax=e(x⋅ln(a)), 从而有 1000 0 − i d m o d e l = e ( − i d model ⋅ log ( 10000 ) ) 10000^{-\frac{i}{d_{m o d e l}}}=e^{\left(-\frac{i}{d_{\text {model }}} \cdot \log (10000)\right)} 10000−dmodeli=e(−dmodel i⋅log(10000))
(3)位置编码的解释
为什么这个公式长这样,具体可以参考3.
以及4里面解释了为什么需要位置编码,并解释了为什么是sin,cos交替?
如下图所示4,当我们用二进制来编码一个整数位置信息(这里0、1、2就代表不同的位置),可以发现二进制数字中的各个位随数字增加时的变化规律。最低位在每个数字间交替变化,第二位每两个数字变化一次,第三位每四个数字变化一次,依此类推。通过这种模式,可以用二进制表示出位置或顺序。
 虽然使用二进制值来表示数据(如位置或顺序)是有效的,但在处理浮点数时,二进制表示可能会显得浪费空间。因此,作者提出了一种替代方案,使用正弦函数(sinusoidal functions)来模拟这种二进制的交替行为。
虽然使用二进制值来表示数据(如位置或顺序)是有效的,但在处理浮点数时,二进制表示可能会显得浪费空间。因此,作者提出了一种替代方案,使用正弦函数(sinusoidal functions)来模拟这种二进制的交替行为。
如下图所示,维度为128维的句子位置编码,其中句子的最大长度为50,每一行代表一个Token的嵌入向量。
- sin、cos相当于交替变化的比特。
- 此外,通过降低sin,cos的频率,我们可以从红色比特变成橙色比特。
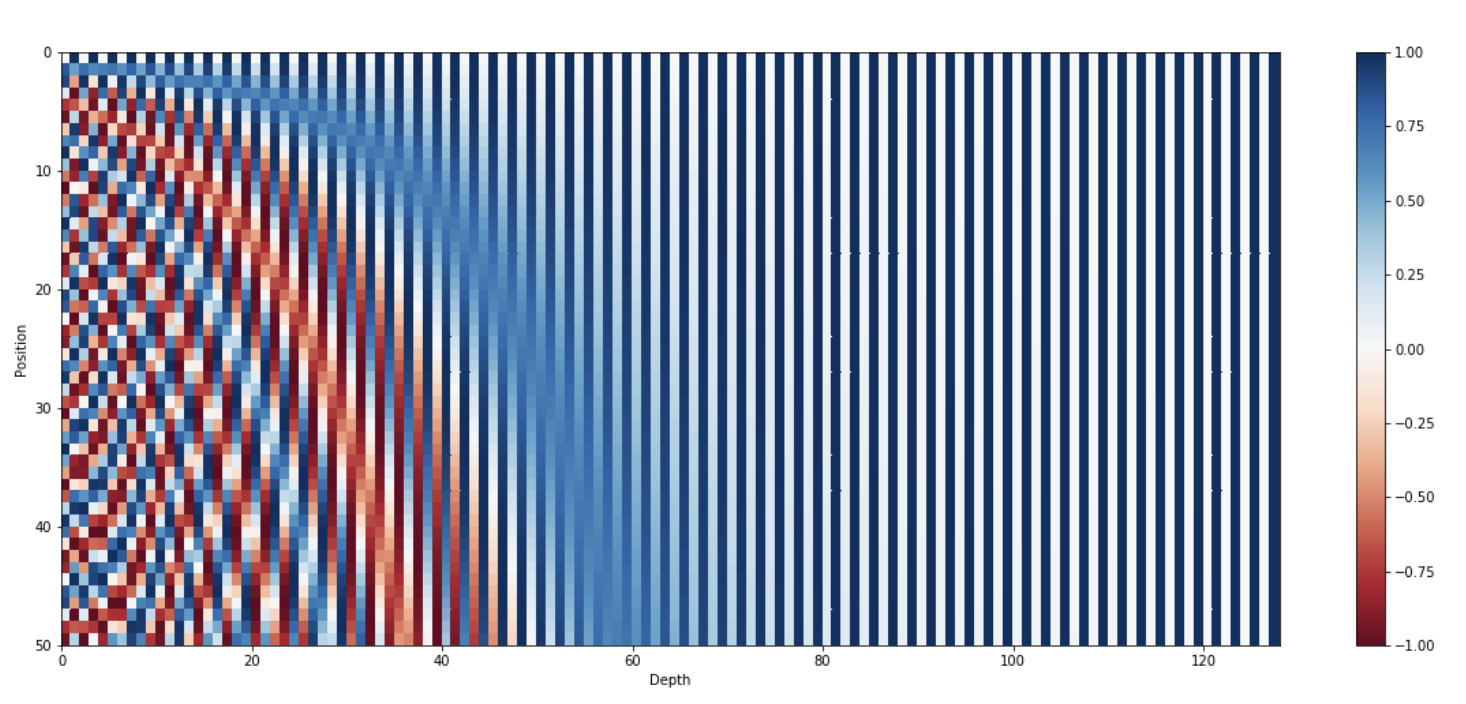
(4)相对位置信息表示
虽然这个编码方式是绝对位置编码,但是正如原文提到的这个编码可以让模型学到相对位置信息:
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k k k, P E p o s + k PE_{pos+k} PEpos+kcan be represented as a linear function of P E p o s PE_{pos} PEpos .
也就是说上面定义的位置编码方式,不同位置之间的编码可以通过一个简单的线性变换得到,详细推导参考5,这里记录一个4中给出的简单推导版本。
对于每个与频率 ω k \omega_k ωk 对应的正弦-余弦对,都存在一个线性变换矩阵 M ∈ R 2 × 2 M \in \mathbb{R}^{2 \times 2} M∈R2×2(与 t t t 无关),使得以下等式成立:
M ⋅ [ sin ( ω k ⋅ t ) cos ( ω k ⋅ t ) ] = [ sin ( ω k ⋅ ( t + ϕ ) ) cos ( ω k ⋅ ( t + ϕ ) ) ] M \cdot \begin{bmatrix}\sin(\omega_k \cdot t)\\\cos(\omega_k \cdot t)\end{bmatrix} = \begin{bmatrix}\sin(\omega_k \cdot (t + \phi))\\\cos(\omega_k \cdot (t + \phi))\end{bmatrix} M⋅[sin(ωk⋅t)cos(ωk⋅t)]=[sin(ωk⋅(t+ϕ))cos(ωk⋅(t+ϕ))]
这里
t
t
t为当前位置,
ϕ
\phi
ϕ是相对当前位置的偏移量,通过对上式右端进行展开(正余弦公式),可以推得
M
M
M为:
M
ϕ
,
k
=
[
cos
(
ω
k
.
ϕ
)
sin
(
ω
k
.
ϕ
)
−
sin
(
ω
k
.
ϕ
)
cos
(
ω
k
.
ϕ
)
]
M_{\phi,k}=\begin{bmatrix}\cos(\omega_{k}.\phi)&\sin(\omega_{k}.\phi)\\-\sin(\omega_{k}.\phi)&\cos(\omega_{k}.\phi)\end{bmatrix}
Mϕ,k=[cos(ωk.ϕ)−sin(ωk.ϕ)sin(ωk.ϕ)cos(ωk.ϕ)]
注意到这个矩阵和旋转矩阵非常像。
同样地,我们可以为其他正弦-余弦对找到矩阵 M M M,这最终使得我们能够将 p t + ϕ ⃗ \vec{p_{t+\phi}} pt+ϕ表示为 p t → \overrightarrow{p_t} pt的线性函数,对于任何固定的偏移量 ϕ \phi ϕ都适用。这个性质使得模型可以轻松学习通过相对位置进行注意力分配。
(四)残差连接
由Transformer的结构我们可以看到,在经过Multi-Head Attention得到矩阵 Z Z Z之后,并没有直接传入全连接神经网络FNN,而是经过了一步:Add&Normalize。
Add,就是在Z的基础上加了一个残差块X,加入残差块X的目的是为了防止在深度神经网络训练中发生退化问题,退化的意思就是深度神经网络通过增加网络的层数,Loss逐渐减小,然后趋于稳定达到饱和,然后再继续增加网络层数,Loss反而增大。
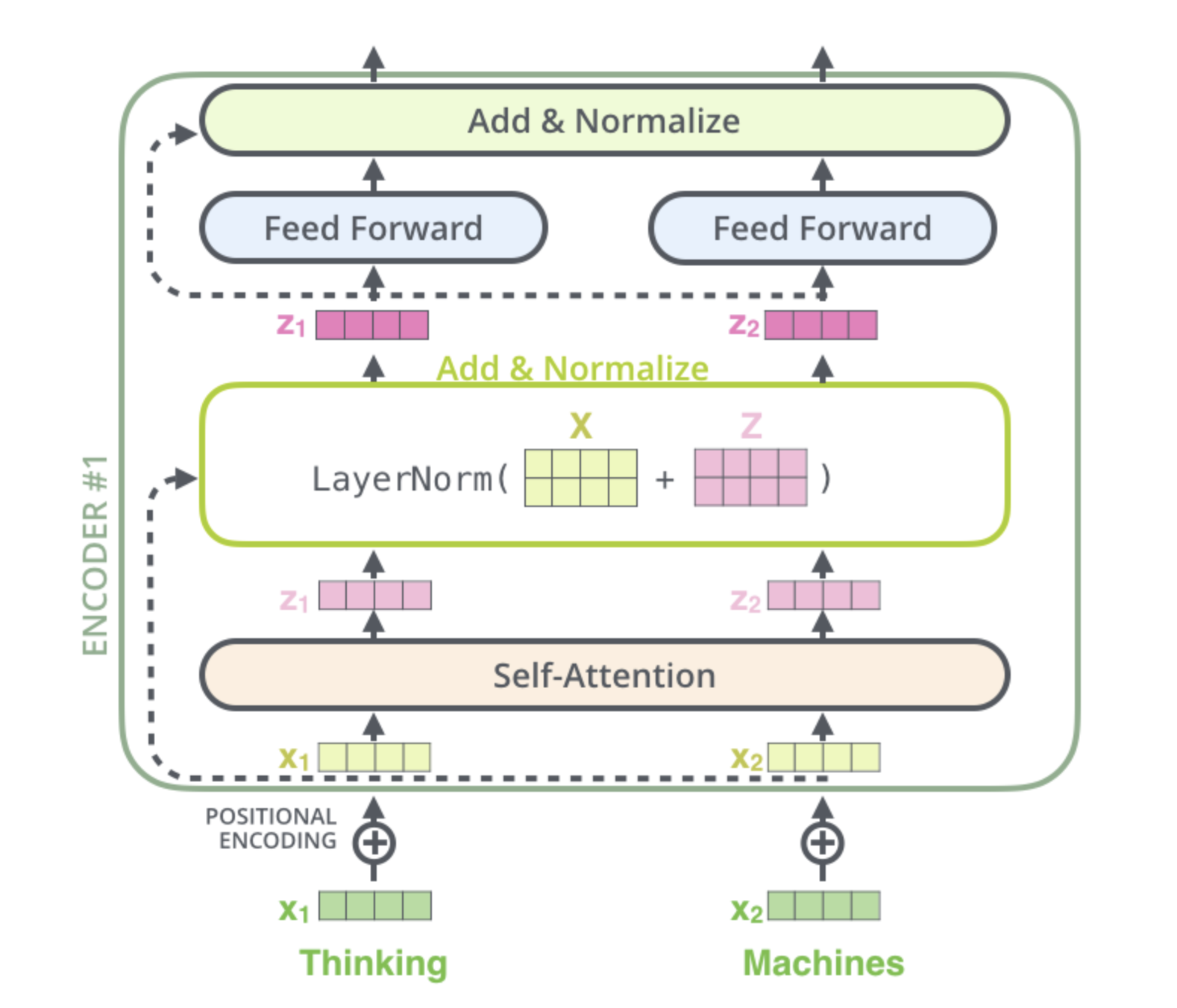
如上图所示,残差连接就是将 X X X和输出 Z Z Z加起来作为最后的输出。Python代码如下:
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
这里sublayer(self.norm(x))就是
Z
Z
Z,self.norm(x)是对上一层的输出作层归一化。
(五)层归一化
在进行了残差连接后,还要对数据进行层归一化,其目的有二:
- 能够加快训练的速度;
- 提高训练的稳定性.
为什么使用Layer Normalization(LN)而不使用Batch Normalization(BN)呢?,LN是在同一个样本中不同神经元之间进行归一化(对同一个数据不同特征),而BN是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化(对不同数据的同一个特征之间)。
如下图所示6, X X X的每一行是一个词向量,每一列是词向量的一个嵌入维度,LN是对每一行进行归一化,而BN是对每一列进行归一化。
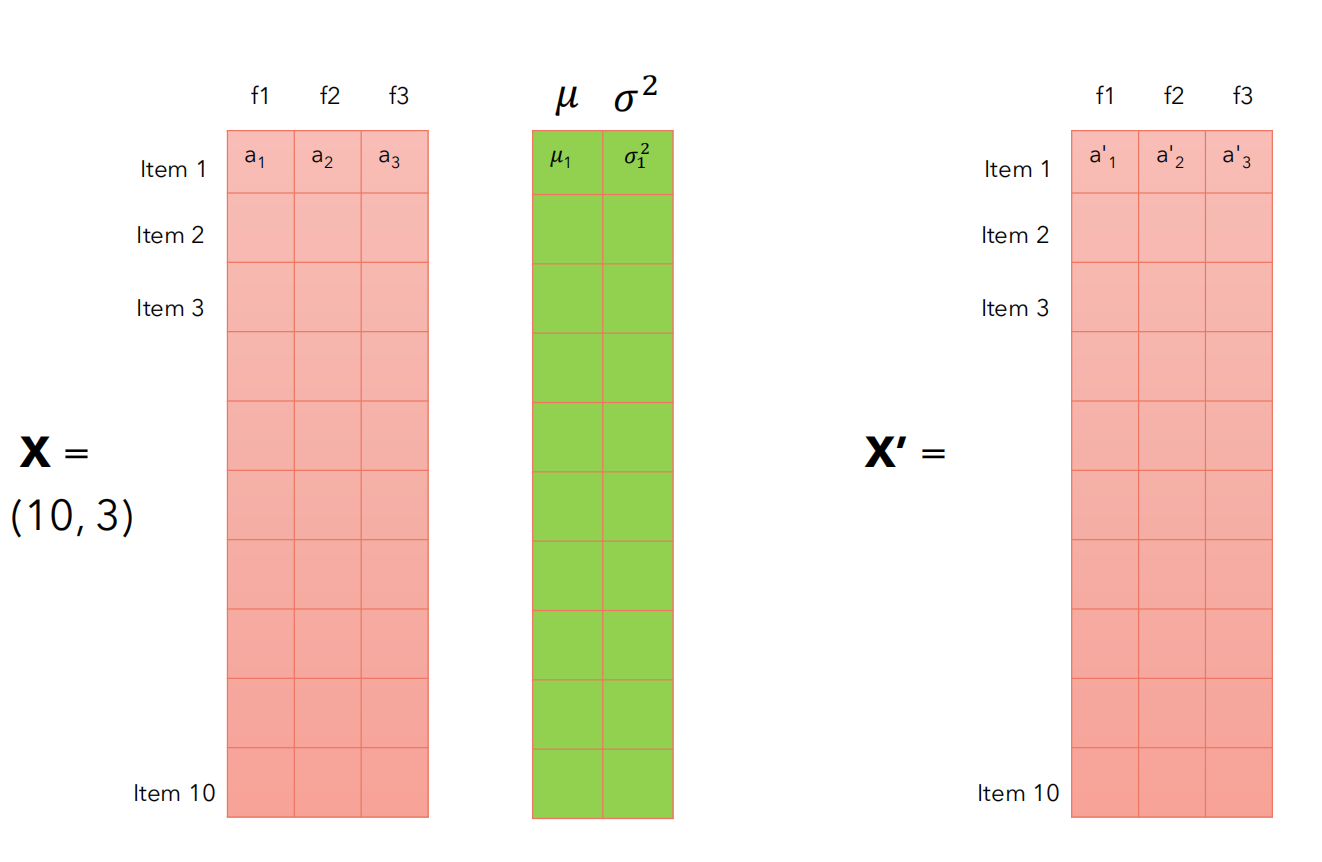
对多个词向量的同一维度进行BN归一化没有意义,但是可以对每个词向量的数据进行归一化,加快训练速度。对于给定的输入 x x x,其维度为 ( N , L ) (N,L) (N,L),其中 N N N是批量大小(词的个数), L L L是特征维度(词向量维度)。层归一化的计算公式为:
μ = 1 L ∑ j = 1 L x i j ( 均值 ) σ 2 = 1 L ∑ j = 1 L ( x i j − μ ) 2 ( 方差 ) x ^ i j = x i j − μ σ 2 + ϵ ( 归一化 ) y i j = γ ⊗ x ^ i j + β \begin{aligned} \mu&=\frac1L\sum_{j=1}^Lx_{ij} &(\text{均值})\\ \sigma^2&=\frac1L\sum_{j=1}^L(x_{ij}-\mu)^2 &(\text{方差}) \\ \hat{x}_{ij}&=\frac{x_{ij}-\mu}{\sqrt{\sigma^2+\epsilon}} &(\text{归一化})\\ y_{ij}&=\gamma\otimes\hat{x}_{ij}+\beta \end{aligned} μσ2x^ijyij=L1j=1∑Lxij=L1j=1∑L(xij−μ)2=σ2+ϵxij−μ=γ⊗x^ij+β(均值)(方差)(归一化)
其中, γ \gamma γ和 β \beta β是可训练参数, ϵ \epsilon ϵ是防止除零的小常数。注意:
- γ \gamma γ和 β \beta β都是向量
- ⊗ \otimes ⊗表示逐元素点乘
Python实现代码为:
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features)) # 可以学习的参数
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True) # 对最后一个维度求均值,也就是对每个词向量
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
(六)前馈神经网络
编码器和解码器的每一层还包括一个前馈神经网络,前馈神经网络有两层:
- 第一层从 d m o d e l d_{model} dmodel维度投影到中间维度(通常是4 d m o d e l d_{model} dmodel);
- 第二层再从中间维度投影回 d m o d e l d_{model} dmodel维.
x
=
x
W
1
+
b
1
(
上投影
)
x
=
max
(
0
,
x
)
(
激活函数
)
x
=
x
W
2
+
b
2
(
下投影
)
\begin{aligned} x&=\,\mathbf{x}\mathbf{W}_1+\mathbf{b}_1 & (\text{上投影})\\ x &= \max (0,x) & (\text{激活函数})\\ x &= x\mathbf{W}_2+\mathbf{b}_2 & (\text{下投影}) \end{aligned}
xxx=xW1+b1=max(0,x)=xW2+b2(上投影)(激活函数)(下投影)
这里的第一个
x
x
x就是我们Multi-Head Attention的输出Z,若Z是(2,64)维的矩阵,假设W1是(64,1024),其中W2与W1维度相反(1024,64),那么按照上面的公式:
F
F
N
(
Z
)
=
(
2
,
64
)
×
(
64
,
1024
)
×
(
1024
,
64
)
=
(
2
,
64
)
FFN(Z)=(2,64)\times(64,1024)\times(1024,64)=(2,64)
FFN(Z)=(2,64)×(64,1024)×(1024,64)=(2,64)
我们发现维度没有发生变化,这两层网络就是为了将输入的Z映射到更加高维的空间中,然后通过非线性函数ReLU进行筛选,筛选完后再变回原来的维度。然后经过Add&Normalize,输入下一个encoder中,经过6个encoder后输入到decoder中.
三、Decoder
接下来来看Decoder部分,其结构如下所示,和Encoder很像,但是多了一个Masked Multi-Head Attention层,这是干嘛用的呢?这是为了防止Decoder在训练的时候“作弊”,在每个时间步t只允许看到这之前的信息,不能利用t+1后的信息。下面来详细的介绍每个部分。
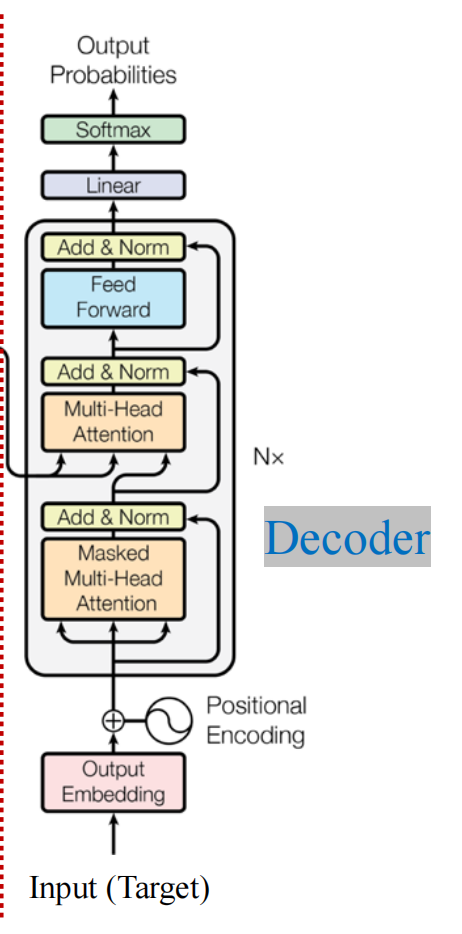
(一)解码器的输入
Decoder的输入分为两类:一种是训练时的输入,一种是预测时的输入。
- 训练时的输入就是已经对准备好对应的target数据。例如翻译任务,Encoder输入"Tom chase Jerry",Decoder输入"汤姆追逐杰瑞"。
- 预测时的输入,一开始输入的是起始符,然后每次输入是上一时刻Transformer的输出。例如,输入"“,输出"汤姆”,输入"汤姆",输出"汤姆追逐",输入"汤姆追逐",输出"汤姆追逐杰瑞",输入"汤姆追逐杰瑞",输出"汤姆追逐杰瑞"结束。
下面动图所示是解码器的第一个时间步,输入是起始符,不过也会用到编码器的信息:
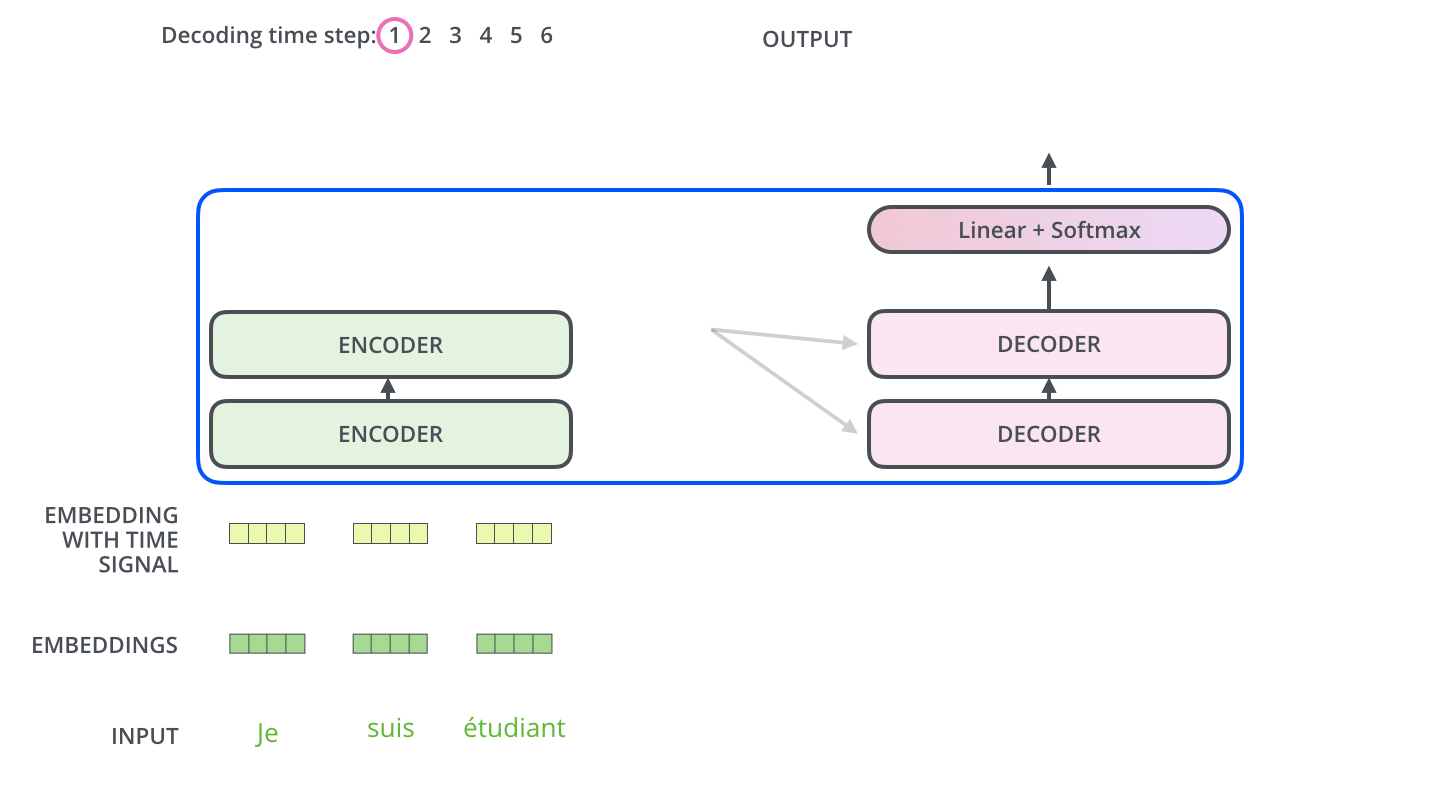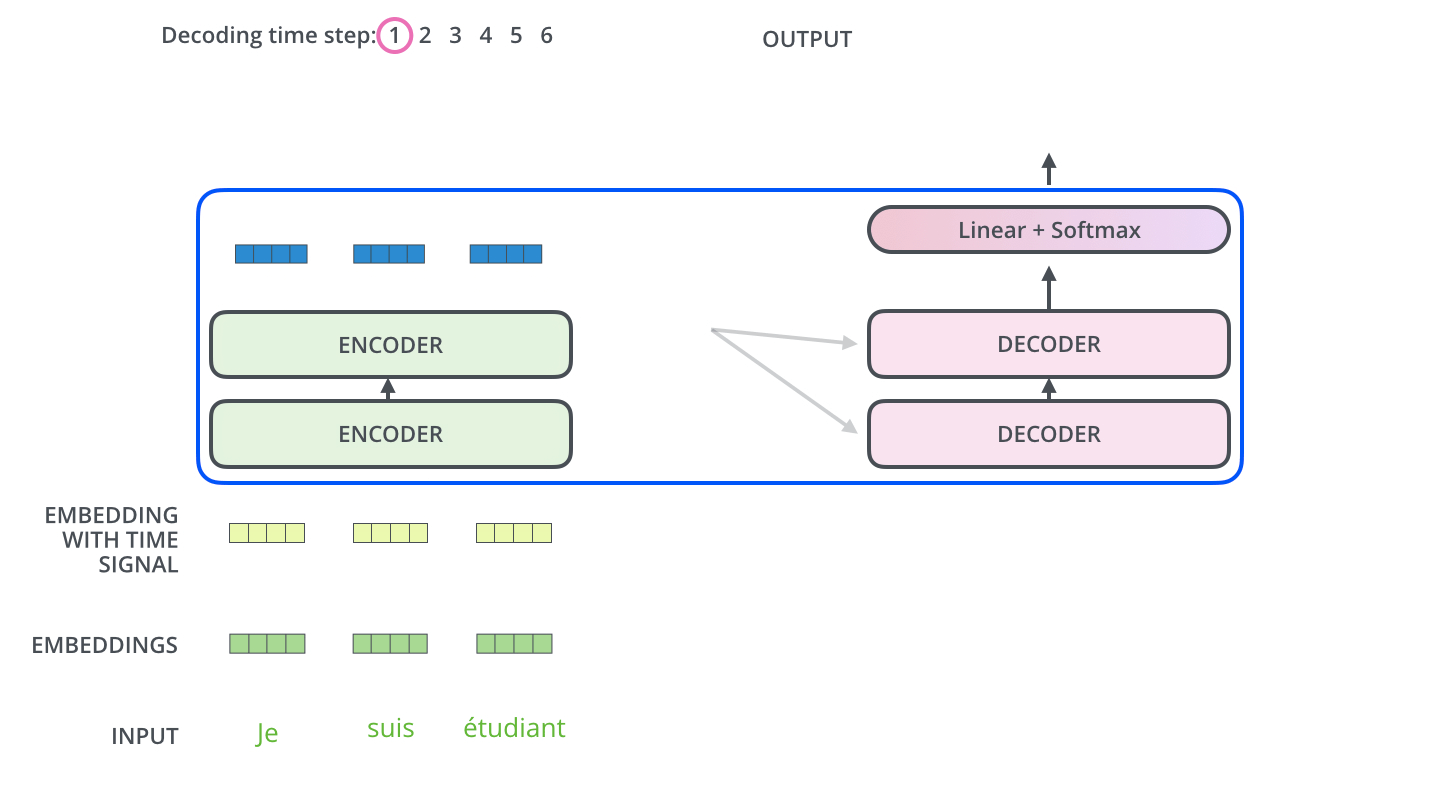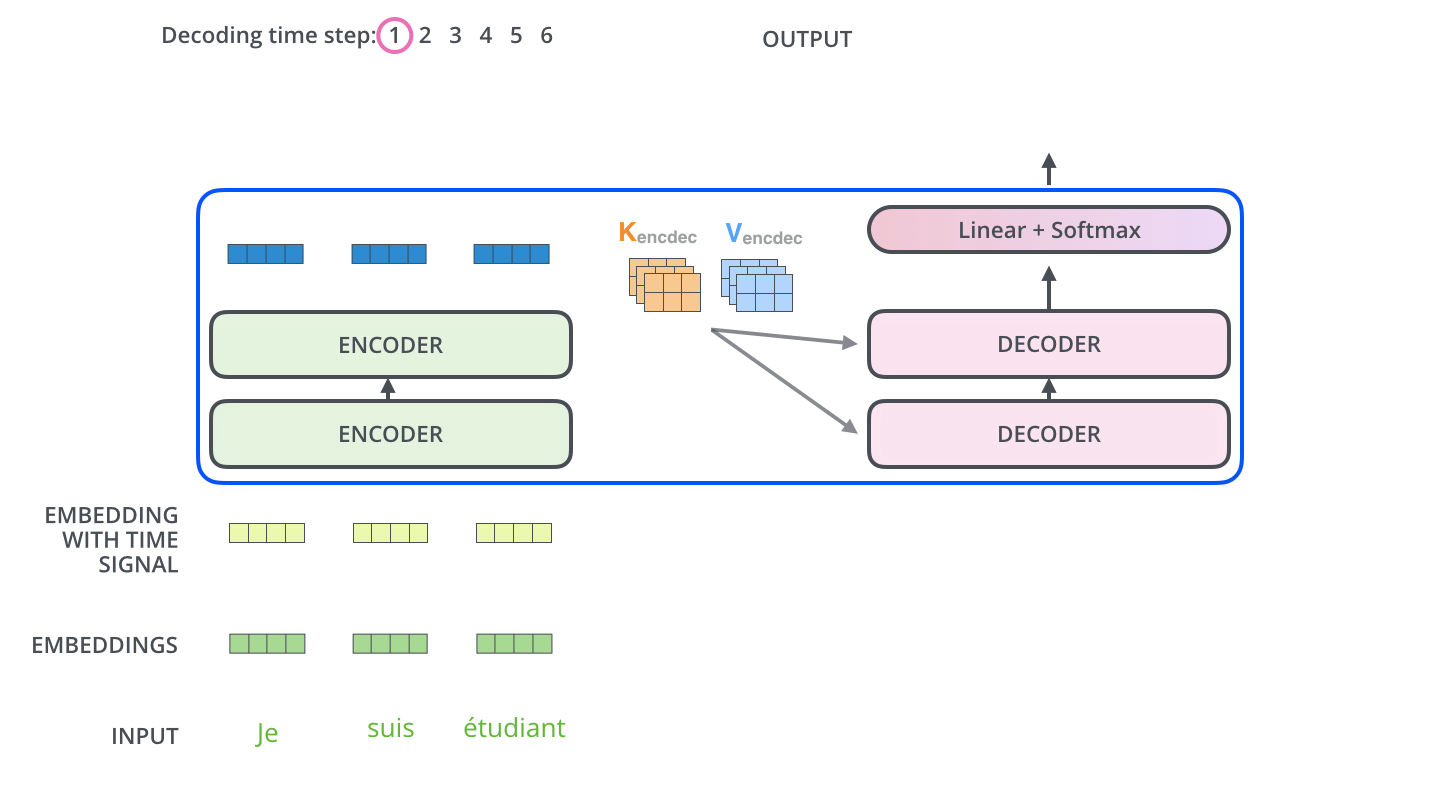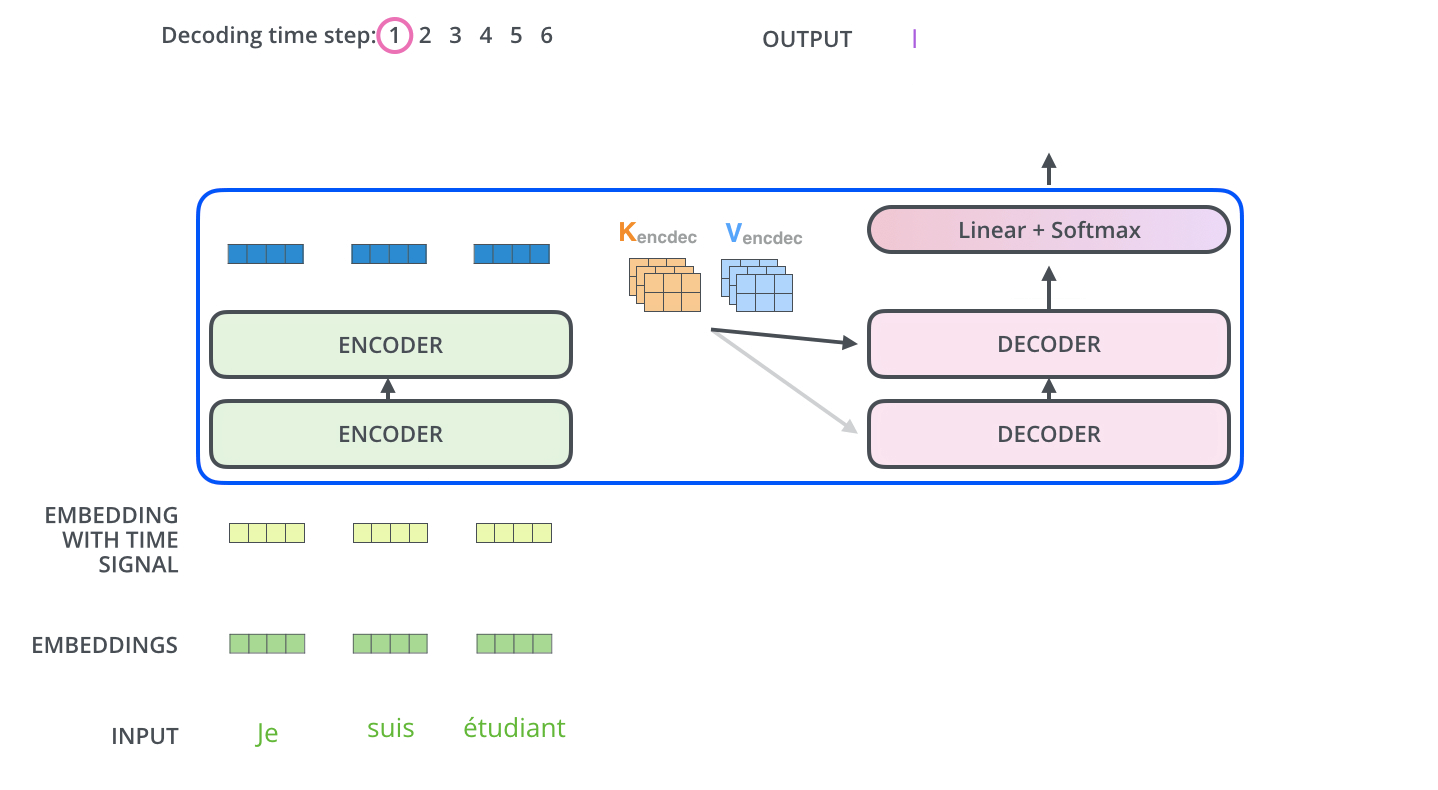
下面动图展示了Decoder后面几个时间步的输入,是上一个时间步解码器的输入:
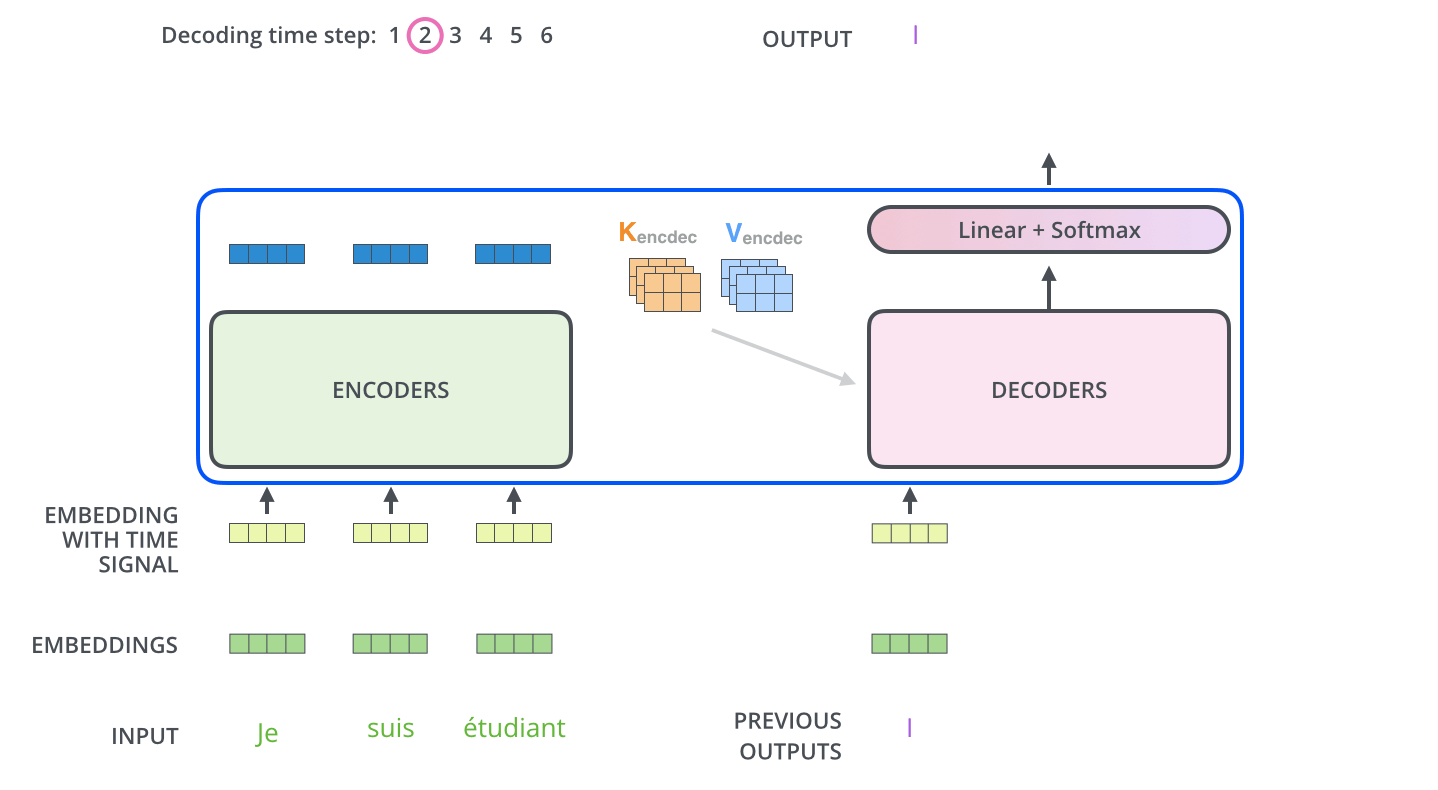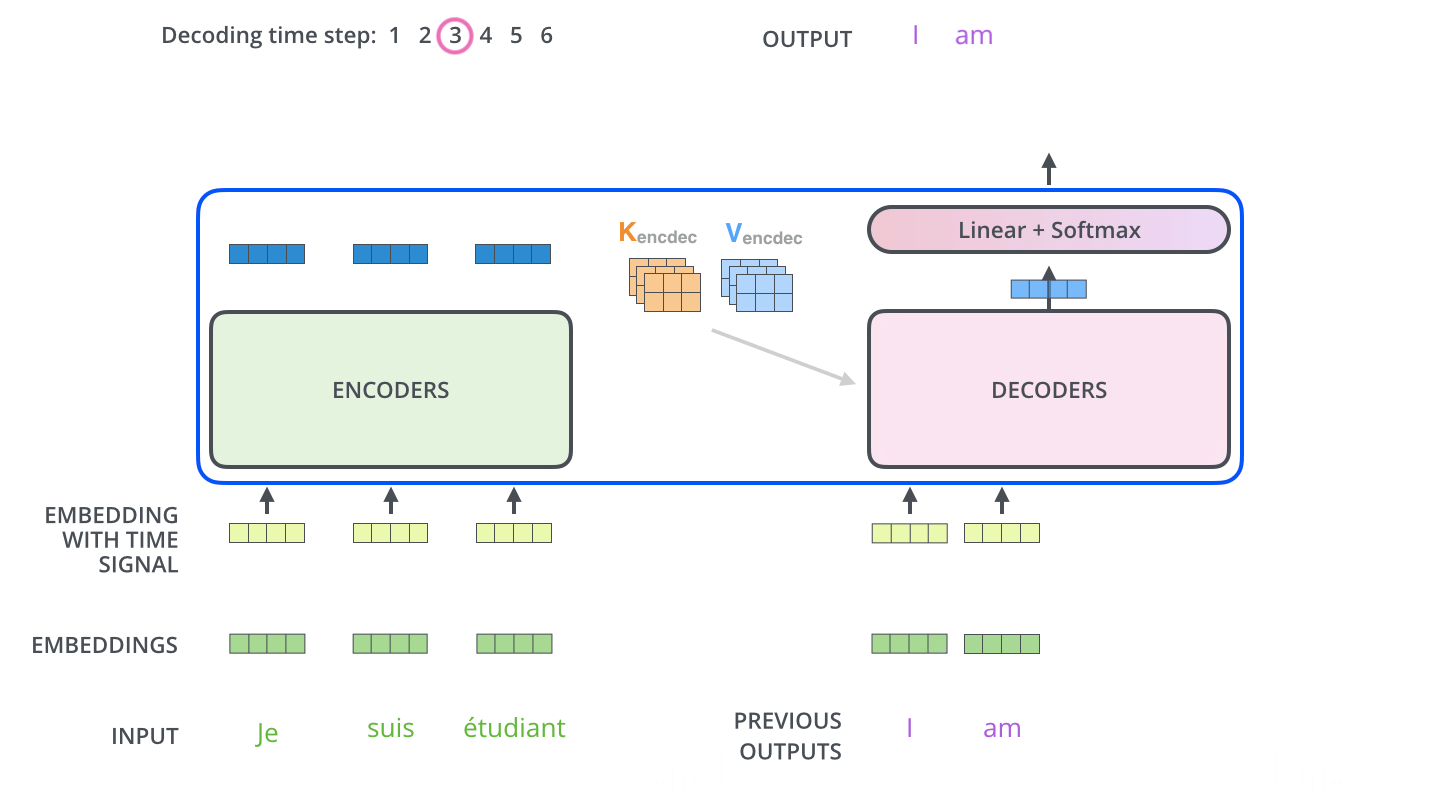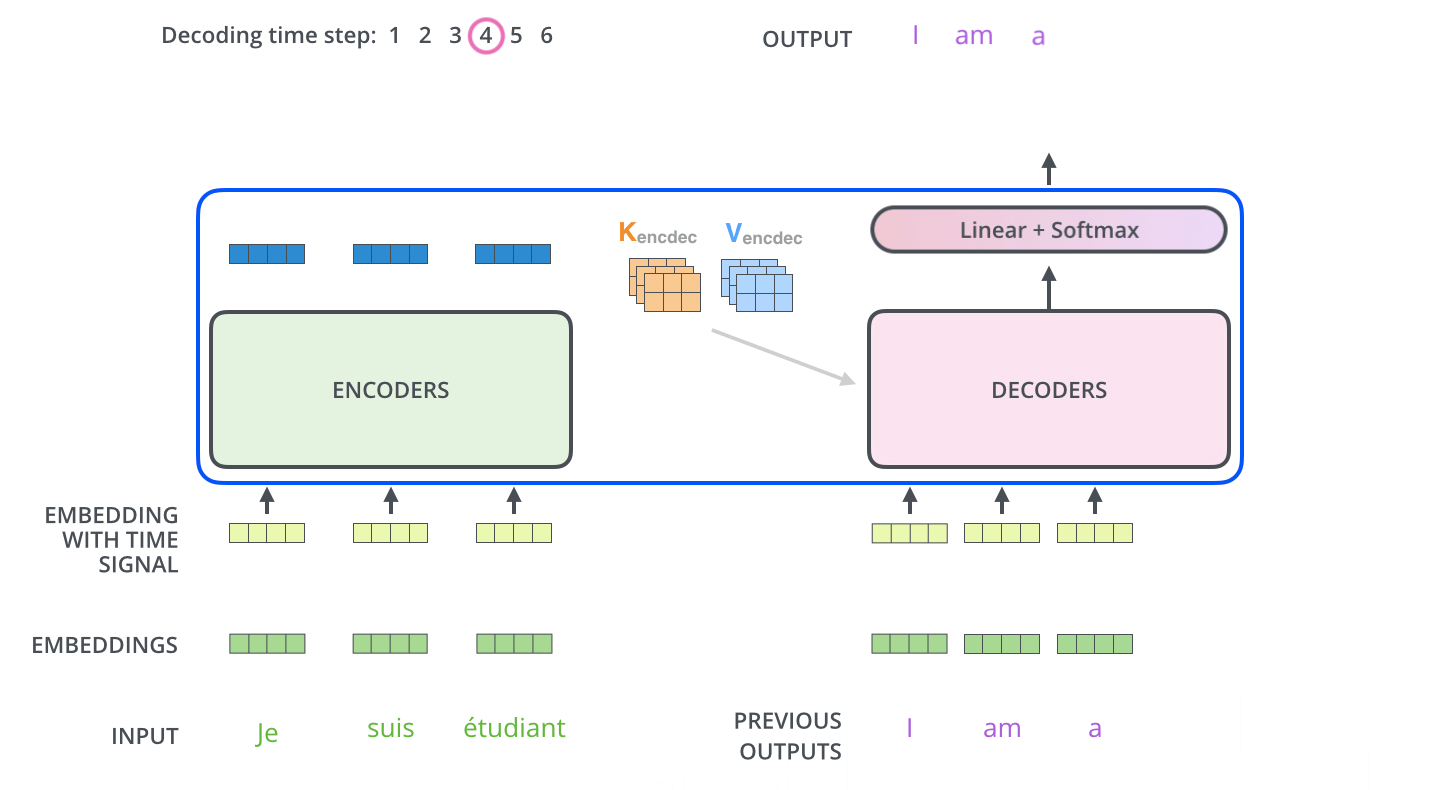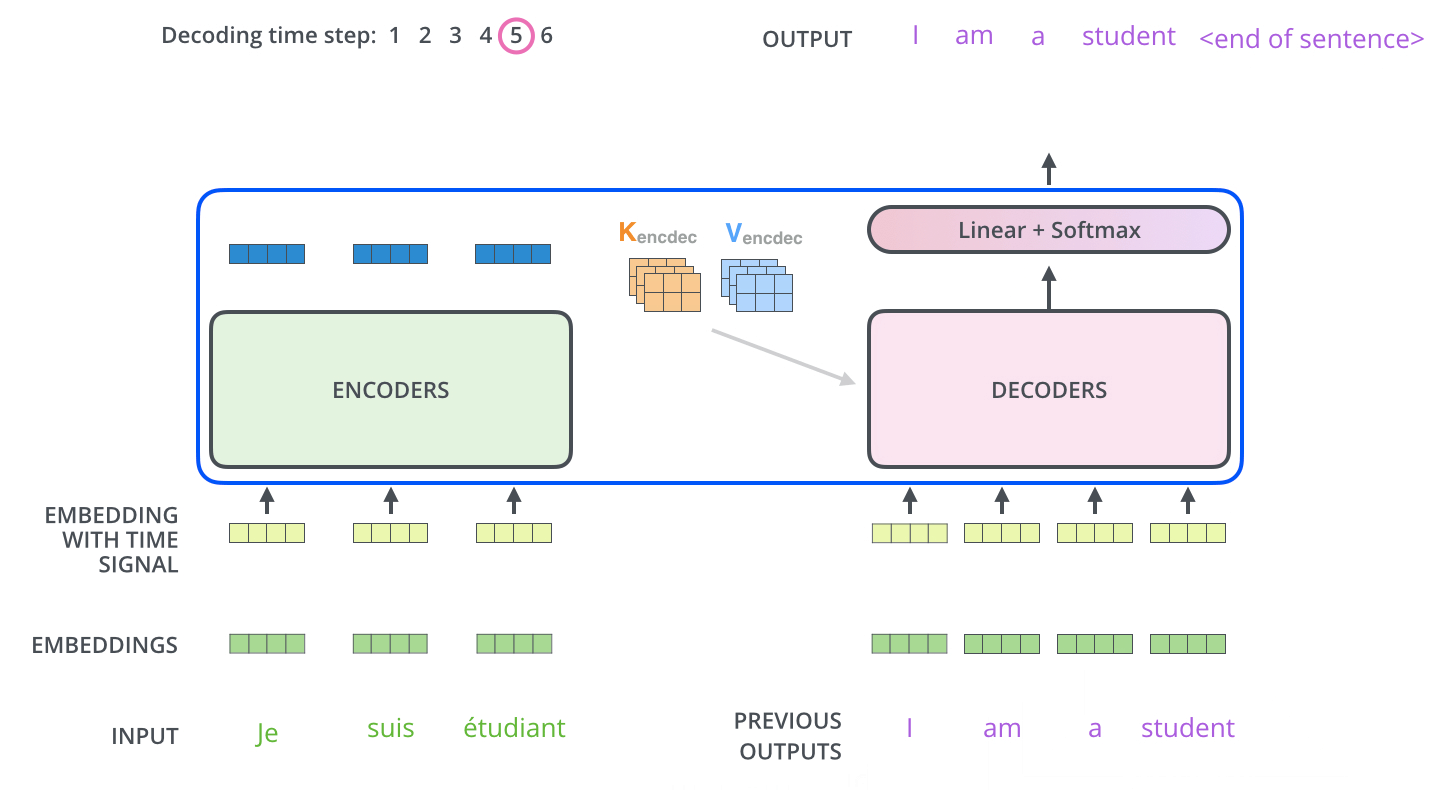
(二)Masked Multi-Head Attention
与Encoder的Multi-Head Attention计算原理一样,只是多加了一个mask码。mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果,也就是说当前词只会注意到前面出现的词,不会关注后面出现的词。两种模型的结构对比如下图所示:
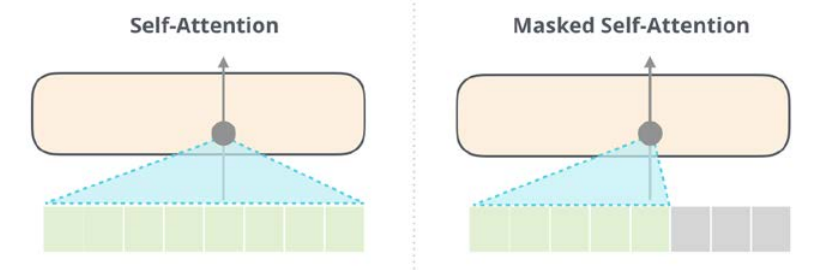
其中Masked Self-Attention也叫Causal Self-Attention.
Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。为什么需要添加这两种mask码呢?
1.padding mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
2.sequence mask
sequence mask 是为了使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。
通过sequence mask,可以使得网络进行并行计算.具体做法是在每个时间步t,我们屏蔽对未来词的注意力,将对未来的词(token)的attention值设置为-∞,其余部分的Attention值计算同前面介绍的方法一致,下图给出了一个示例:
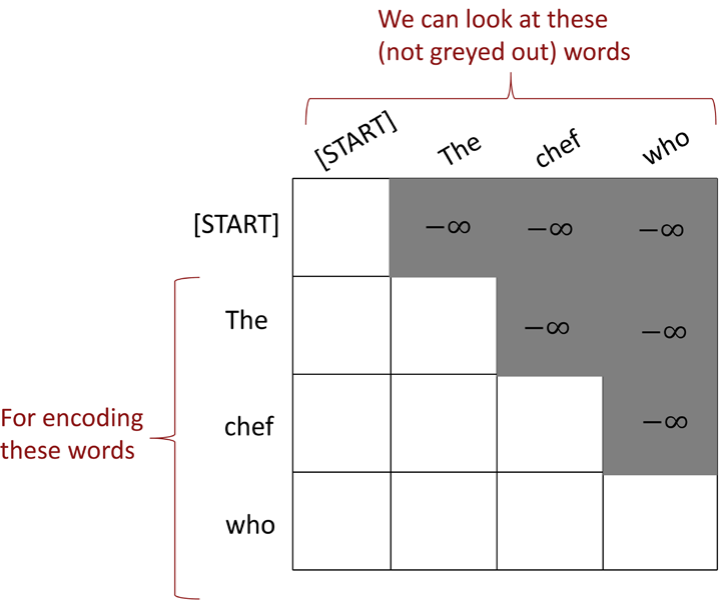
Decoder中有两个Masked Multi-Head Attention层,第一个Multi-Head Attention层的工作原理和Encoder基本一样。第二个结构如下:
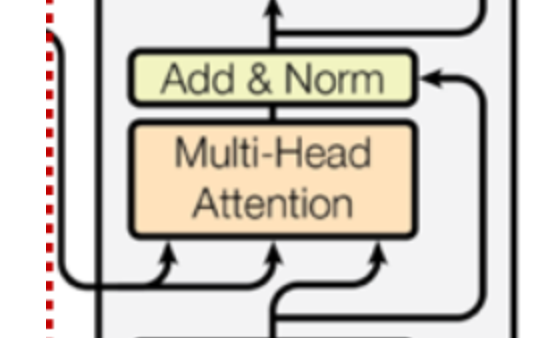
注意到它从下面的Masked Multi-Head Attention层创建查询矩阵Q,并从编码器堆栈的输出中获取键和值矩阵(K、V)。 下面给一个Python实例帮助理解:
import torch
import math
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape),diagonal=1).type(
torch.uint8)
return subsequent_mask == 0 # 返回上三角矩阵,布尔值
# 示例数据
torch.manual_seed(0) # 设置随机种子以确保结果可重复
query = torch.randn(2, 5, 4) # (batch_size, seq_len, d_k)
key = torch.randn(2, 5, 4) # (batch_size, seq_len, d_k)
value = torch.randn(2, 5, 4) # (batch_size, seq_len, d_k)
mask = subsequent_mask(5) # 生成大小为 5 的掩码
# 计算注意力
output, attention_weights = attention(query, key, value, mask)
print("输出张量:")
print(output)
print("\n注意力权重:")
print(attention_weights)
上面代码的输出如下:

可以看到加上掩码之后,每个位置t,对其后(t+1)的注意力值都是0。
(三)Decoder的输出
解码器输出一个浮点数向量,如何将其转化为一个单词呢?这就是最终的线性层(Linear layer)和后续的Softmax层的工作。
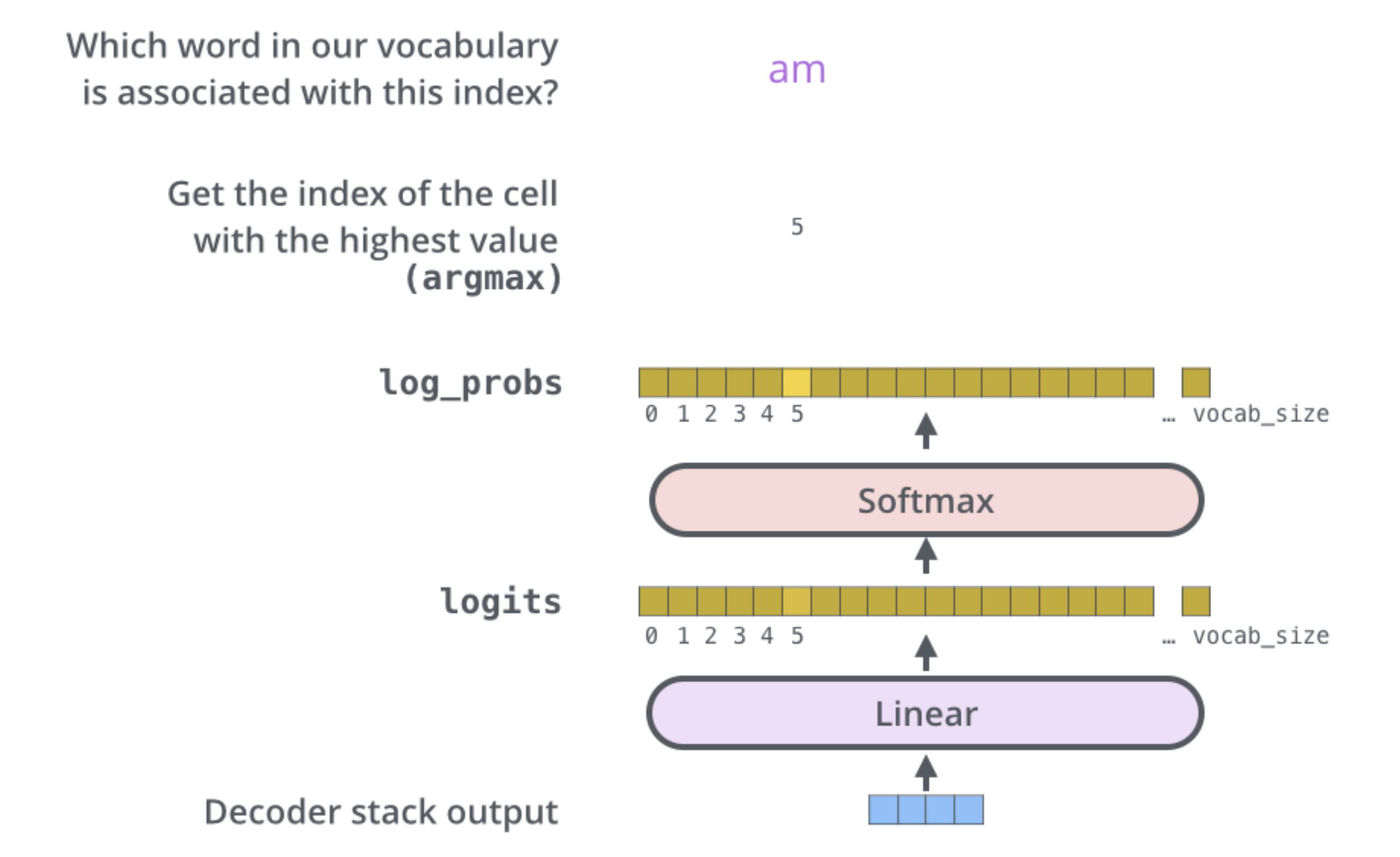
线性层是一个简单的全连接神经网络,它将解码器生成的向量投射到一个更大得多的向量上,这个向量称为logits向量。假设我们的模型知道10,000个独特的英文单词(模型的“输出词汇”),这些单词是从训练数据集中学习到的。这将使logits向量为10,000维,每维对应一个唯一单词的得分。这就是我们通过线性层解释模型输出的方式。然后,Softmax层将这些得分转化为概率(所有概率都是正数,总和为1.0)。选择概率最高的index,并将其对应的单词作为该时间步的输出。
四、复杂度分析及改进方法介绍
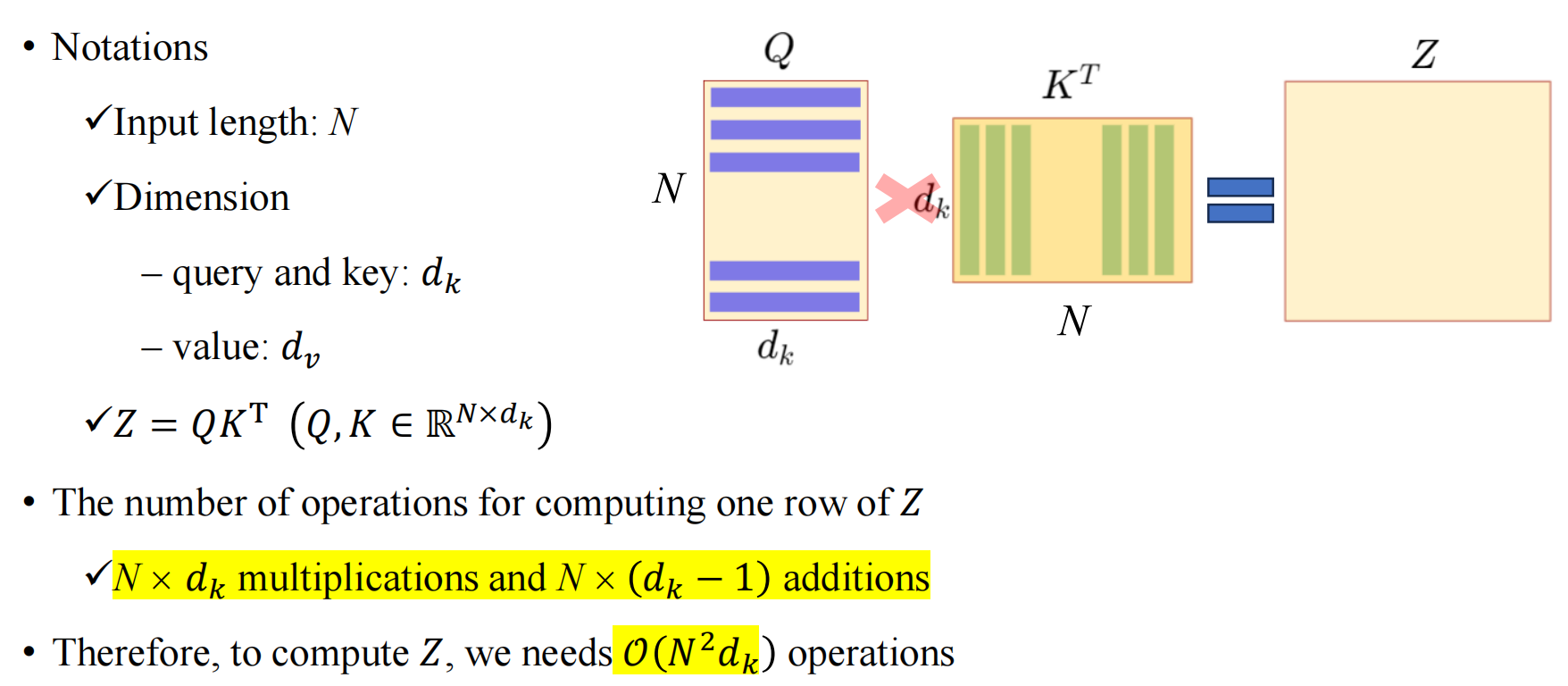
总的来说,自注意力模型的时间和空间复杂度与输入序列长度 N N N呈2次关系,可以不严格的表示为 O ( N 2 ) O(N^2) O(N2).
(一)时间复杂度

(二)空间复杂度

(三)改进方法
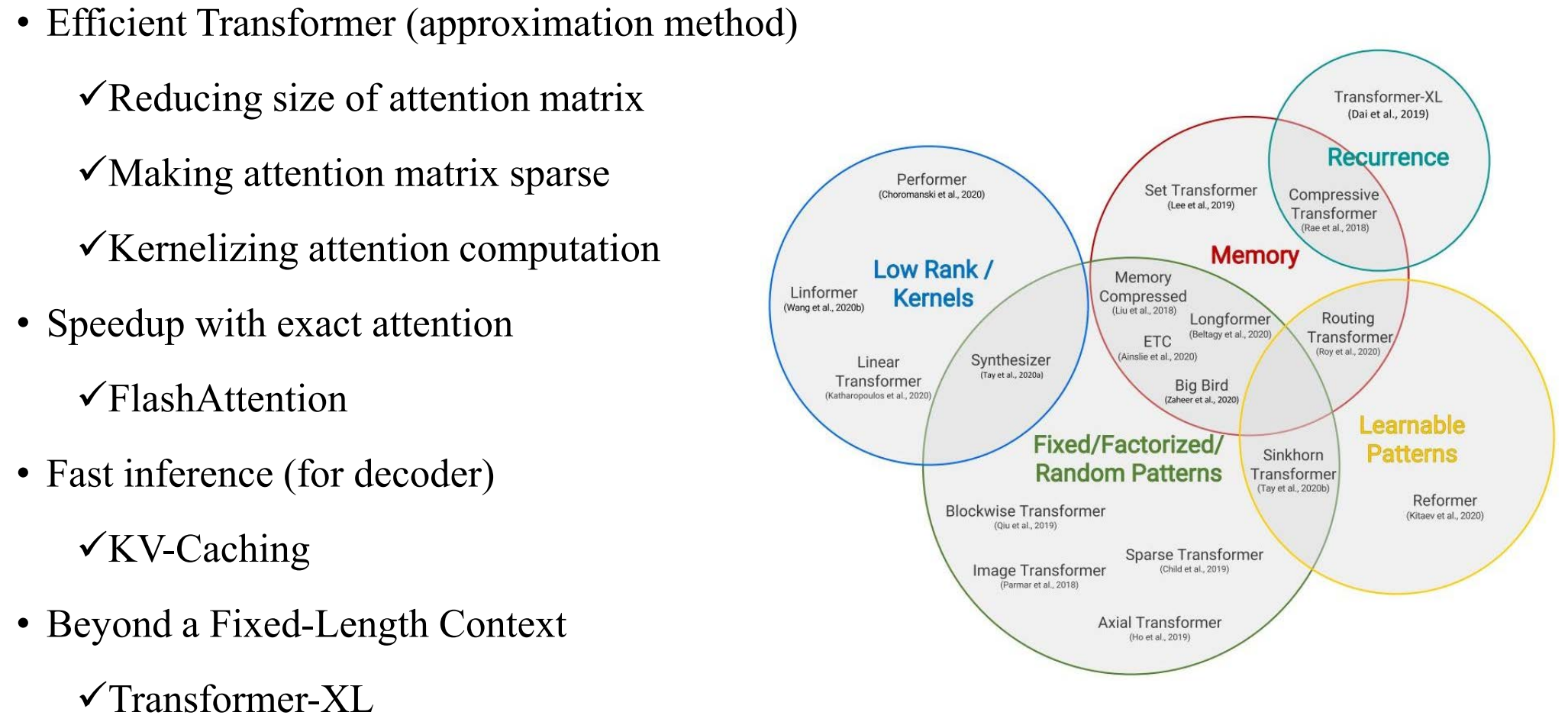
通过上面两小节的分析,我们知道Self Attention的时间和空间复杂度是输入序列的 O ( N 2 ) O(N^2) O(N2),这对于处理长文本来说效率太低了,目前学界提出了很多改进Self Attention模型的方法:
参考资料
- Attention is all you need
- The Illustrated Transformer
- The Annotated Transformer
- https://blog.youkuaiyun.com/Tink1995/article/details/105080033
- [【可视化注意力,youtube视频】](AICF29 P02 (youtube.com))
Self-Attention with Relative Position Representations ↩︎
一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long(含NTK-aware简介) ↩︎ ↩︎
Linear Relationships in the Transformer’s Positional Encoding ↩︎


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









