



 本文深入探讨了Java性能测试,通过JMH(Java Microbenchmark Harness)工具进行基准测试。文章介绍了JIT编译器如何优化代码,解释了代码运行越快的原因,并讨论了如何识别和优化热点代码。同时,强调了在基准测试中避免在Benchmark内部使用循环的重要性,并提供了测试结果报告的解读。
本文深入探讨了Java性能测试,通过JMH(Java Microbenchmark Harness)工具进行基准测试。文章介绍了JIT编译器如何优化代码,解释了代码运行越快的原因,并讨论了如何识别和优化热点代码。同时,强调了在基准测试中避免在Benchmark内部使用循环的重要性,并提供了测试结果报告的解读。

最近在研究一些基础组件实现的时候遇到一个问题,关于不同技术的运行性能比对该如何去实现。
什么是性能比对呢?
举个简单的栗子 来说:假设我们需要验证String,StringBuffer,StringBuilder三者在使用的时候,希望能够通过一些测试来比对它们的性能开销。下边我罗列出最简单的测试思路:
for循环比对
这种测试思路的特点:简单直接
public class TestStringAppendDemo {
public static void testStringAdd() {
long begin = System.currentTimeMillis();
String item = new String();
for (int i = 0; i < 100000; i++) {
itemitem = item + "-";
}
long end = System.currentTimeMillis();
System.out.println("StringBuffer 耗时:" + (end - begin) + "ms");
}
public static void testStringBufferAdd() {
long begin = System.currentTimeMillis();
StringBuffer item = new StringBuffer();
for (int i = 0; i < 100000; i++) {
itemitem = item.append("-");
}
long end = System.currentTimeMillis();
System.out.println("StringBuffer 耗时:" + (end - begin) + "ms");
}
public static void testStringBuilderAdd() {
long begin = System.currentTimeMillis();
StringBuilder item = new StringBuilder();
for (int i = 0; i < 100000; i++) {
itemitem = item.append("-");
}
long end = System.currentTimeMillis();
System.out.println("StringBuilder 耗时:" + (end - begin) + "ms");
}
public static void main(String[] args) {
testStringAdd();
testStringBufferAdd();
testStringBuilderAdd();
}
}
不知道你在平时工作中是否经常会这么做,虽然说通过简单的for循环执行来看,我们确实能够较好地给出谁强谁弱的这种结论,但是比对的结果并不精准。因为Java程序的运行时有可能会越跑越快的!
代码越跑越快
看到这里你可能会有些疑惑,Java程序不是在启动之前都编译成了统一的字节码么,难道在字节码翻译为机器代码的过程中还有什么不为人知的优化处理手段?
下边我们来观察这么一段测试程序:
public static void testStringAdd() {
long begin = System.currentTimeMillis();
String item = new String();
for (int i = 0; i < 100000; i++) {
itemitem = item + "-";
}
long end = System.currentTimeMillis();
System.out.println("String 耗时:" + (end - begin) + "ms");
}
//循环20次执行同一个方法
public static void main(String[] args) {
for(int i=0;i<20;i++){
testStringAdd();
}
}
执行的程序耗时打印在了控制台上:
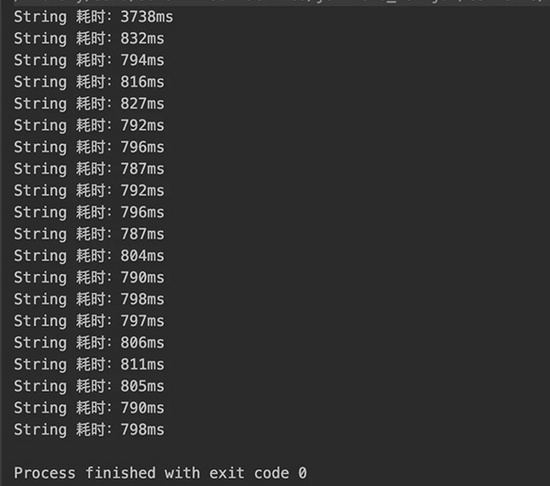
20次的重复调用之后,发现首次和最后一次调用几乎存在5倍的差异。看来代码运行越跑越快是存在的了,但是为什么会有这种现象发生呢?
这里我们需要了解一项叫做JIT的技术。
JIT技术
在介绍JIT技术之前,需要先进行些相关知识的补充铺垫。
解释型语言
解释型语言,是在运行的时候才将程序翻译成 机器语言 。解释型语言的程序不需要在运行前提前做编译工作,在运行程序的时候才翻译,解释器负责在每个语句执行的时候解释程序代码。这样解释型语言每执行一次就要“翻译”一次,效率比较低。代表语言:PHP。
编译型语言
在程序执行之前,提前就将程序编译成机器代码,这样后续机器在运行的时候就不需要额外去做翻译的工作,效率会相对较高。语言代表:C,C++。
而我们本文重点研究的是Java语言,我个人认为这是一门既具备解释特点又具备编译特点的高级语言。
JVM是Java一次编译,跨平台执行的基础。当Java被编译为字节码形式的.class文件之后,他可以在任意的JVM上运行。
PS: 这里说的编译,主要是指前端编译器。
前端编译器
将.java文件编译为JVM可执行的.class字节码文件,即javac,主要职责包括:词法、语法分析,填充符号表,语义分析,字节码生成。输出为字节码文件,也可以理解为是中间表达形式(称为IR:Intermediate Representation)。这时候的编译结果就是我们常见的xxx.class文件。
后端编译器
在程序运行期间将字节码转变成机器码,通过前端编译器和后端编译器的组合使用,通常就是被我们称之为混合模式,如 HotSpot 虚拟机自带的解释器还有 JIT(Just In Time Compiler)编译器(分 Client 端和 Server 端),其中JIT还会将中间表达形式进行一些优化。
所以一份xxx.java的文件实际在执行过程中会按照如下流程执行,首先经过前端解释器转换为.class格式的字节码,再通过后端编译器将其解释为机器能够识别的机器代码。最后再由机器去执行计算。
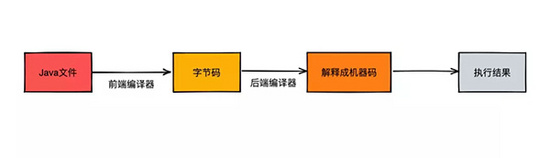
真的就这么简单吗?
还记得我在上边贴出的那段测试代码吗,首次执行和最后执行的性能差异如此巨大,其实是在后端编译器处理的过程中加入优化的手段。
在编译时,主要是将java源代码文件编译为统一的字节码,但是编译成的字节码并不能直接运行,而是需要通过JVM读取运行。JVM中的后端解释器就是将.class文件一行一行翻译之后再运行,翻译就是转换成当前机器可以运行的机器码,它不会一次性把整个文件都翻译过来,而是翻译一句,执行一句,再翻译,再执行,所以解释器的程序运行起来会比较慢,每次都要解释之后再执行。所以有些时候,我们想是否可以把解释之后的内容缓存起来,这样不就可以直接运行了?但是,如果每段代码都要缓存起来,例如仅仅执行一次的代码也缓存起来,这样太浪费内存了。所以,引入一个新的运行时编译器,JIT来解决这些问题,加速热点代码的执行。
引入JIT技术之后,代码的执行过程是怎样的?
在引入了JIT技术之后,一份Java程序的代码执行流程就会变成了下边这种类型。首先通过前端编译器转变为字节码文件,然后再判断对应的字节码文件是否有被提前处理好存放在code cache中。如果有则可以直接执行对应的机器代码,如果没有则需要进行判断是否有必要进行JIT技术优化(判断逻辑的细节后边会讲),如果有必要优化,则会将优化后的机器码也存放到code cache中,否则则是会一边执行一边翻译为机器代码。
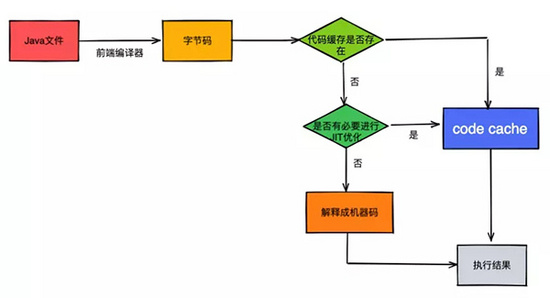
怎样的代码才会被识别为热点代码呢?
在JVM中会设置一个阈值,当某段代码块在一定时间内被执行的次数超过了这个阈值,则会被存放进code cache中。
如何验证:
建立一个测试用的代码Demo,然后设置JVM参数:
-XX:CompileThreshold=500 -XX:+PrintCompilation
public class TestCountDemo {
public static void test() {
int a = 0;
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 600; i++) {
test();
}
TimeUnit.SECONDS.sleep(1);
}
}
接下来专心观察启动程序之后的编译信息记录:
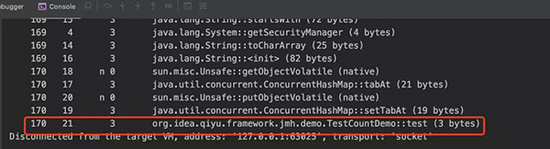
截图解释:
第一列693表示系统启动到编译完成时的毫秒数。
第二列43表示编译任务的内部ID,一般是一个自增的值。
第三列为空,描述代码状态的5个属性。
- %:是一个OSR(栈上替换)。
- s:是一个同步方法。
- !:方法有异常处理块。
- b:阻塞模式编译。
- n:是本地方法的一个包装。
第四列3表示编译级别,0表示没有编译而是使用解释器,1,2,3表示使用C1编译器(client),4表示使用C2编译器(server),级别越高编译生成的机器码质量越好,编译耗时也越长。
最后一列表示了方法的全限定名和方法的字节码长度。
从实验来看,当for循环的次数一旦超过了预期设置的阈值,则会提前使用后端编译器将代码缓存到code cache中。
即时编译极大地提高了Java程序的运行速度,而且跟静态编译相比,即时编译器可以选择性地编译热点代码,省去了很多编译时间,也节省很多的空间。目前,即时编译器已经非常成熟了,在性能层面甚至可以和编译型语言相比。不过在这个领域,大家依然在不断探索如何结合不同的编译方式,使用更加智能的手段来提升程序的运行速度。
还记得我在文章开头所提出的几个问题吗~~既然我们了解了Jvm底层具备了这些优化的技能,那么如何才能更加准确高效地去检测一段程序的性能呢?
基于JMH来实践代码基准测试
JMH是Java Microbenchmark Harness的简称,一个针对Java做基准测试的工具,是由开发JVM的那群人开发的。想准确的对一段代码做基准性能测试并不容易,因为JVM层面在编译期、运行时对代码做很多优化,但是当代码块处于整个系统中运行时这些优化并不一定会生效,从而产生错误的基准测试结果,而这个问题就是JMH要解决的。
关于如何使用JMH在网上有很多的讲解案例,这些入门的资料大家可以自行去搜索。本文主要讲解在使用JMH测试的时候需要注意到的一些细节点:
常用的基本注解以及其具体含义
一般我们会将测试所使用的注解都标注在测试类的头部,常用到的测试注解有以下几种:
/** * 吞吐量测试 可以获取到指定时间内的吞吐量 * * Throughput 可以获取一秒内可以执行多少次调用 * AverageTime 可以获取每次调用所消耗的平均时间 * SampleTime 随机抽样,随机抽取结果的分布,最终是99%%的请求在xx秒内 * SingleShotTime 只允许一次,一般用于测试冷启动的性能 */ @BenchmarkMode(Mode.Throughput) /** * 如果一段程序被调用了好几次,那么机器就会对其进行预热操作, * 为什么需要预热?因为 JVM 的 JIT 机制的存在,如果某个函数被调用多次之后,JVM 会尝试将其编译成为机器码从而提高执行速度。所以为了让 benchmark 的结果更加接近真实情况就需要进行预热。 */ @Warmup(iterations = 3) /** * iterations 每次测试的轮次 * time 每轮进行的时间长度 * timeUnit 时长单位 */ @Measurement(iterations = 10, time = 5, timeUnit = TimeUnit.SECONDS) /** * 测试的线程数,一般是cpu*2 */ @Threads(8) /** * fork多少个进程出来测试 */ @Fork(2) /** * 这个比较简单了,基准测试结果的时间类型。一般选择秒、毫秒、微秒。 */ @OutputTimeUnit(TimeUnit.MILLISECONDS)
如果不喜欢使用注解的方式也可以通过在启动入口中通过硬编码的形式设置:
public static void main(String[] args) throws RunnerException {
//配置进行2轮热数 测试2轮 1个线程
//预热的原因 是JVM在代码执行多次会有优化
Options options = new OptionsBuilder().warmupIterations(2).measurementBatchSize(2)
.forks(1).build();
new Runner(options).run();
}
如果要对某项方法进行JMH测试的话,通常会对该方法的头部加入@Benchmark注解。例如下边这段:
@Benchmark
public String testJdkProxy() throws Throwable {
String content = dataService.sendData("test");
return content;
}
JMH的一些坑
所有方法都应该要有返回值
例如这么一段测试案例:
package org.idea.qiyu.framework.jmh.demo;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
import static org.openjdk.jmh.annotations.Mode.AverageTime;
import static org.openjdk.jmh.annotations.Mode.Throughput;
/**
* JMH基准测试
*/
@BenchmarkMode(Throughput)
@Fork(2)
@Warmup(iterations = 4)
@Threads(4)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class JMHHelloWord {
@Benchmark
public void baseMethod() {
}
@Benchmark
public void measureWrong() {
String item = "";
itemitem = item + "s";
}
@Benchmark
public String measureRight() {
String item = "";
itemitem = item + "s";
return item;
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder().
include(JMHHelloWord.class.getName()).
build();
new Runner(options).run();
}
}
其实baseMethod和measureWrong两个方法从代码功能角度看来,并没有什么区别,因为调用它们两者对于调用方本身并没有造成什么影响,而且measureWrong函数中还存在着无用代码块,所以JMH会对内部的代码进行“死码消除”的处理。
通过测试会发现,其实baseMethod和measureWrong的吞吐性结果差别不大。反而再比对measureWrong和measureRight两个方法,后者只是加入了一个return关键字,JMH就能很好地去测算它的整体性能。
关于什么是“死码消除”,我在这里贴出一段维基百科上的介绍,感兴趣的读者可以自行前往阅读:
https://zh.wikipedia.org/wiki/%E6%AD%BB%E7%A2%BC%E5%88%AA%E9%99%A4
不要在Benchmark内部加入循环的代码
关于这一点我们可以通过一段案例来进行测试,代码如下:
package org.idea.qiyu.framework.jmh.demo;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
/**
* @Author linhao
* @Date created in 10:20 上午 2021/12/19
*/
@BenchmarkMode(Mode.AverageTime)
@Fork(1)
@Threads(4)
@Warmup(iterations = 1)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class ForLoopDemo {
public int reps(int count) {
int sum = 0;
for (int i = 0; i < count; i++) {
sumsum = sum + count;
}
return sum;
}
@Benchmark
@OperationsPerInvocation(1)
public int test_1() {
return reps(1);
}
@Benchmark
@OperationsPerInvocation(10)
public int test_2() {
return reps(10);
}
@Benchmark
@OperationsPerInvocation(100)
public int test_3() {
return reps(100);
}
@Benchmark
@OperationsPerInvocation(1000)
public int test_4() {
return reps(1000);
}
@Benchmark
@OperationsPerInvocation(10000)
public int test_5() {
return reps(10000);
}
@Benchmark
@OperationsPerInvocation(100000)
public int test_6() {
return reps(100000);
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(ForLoopDemo.class.getName())
.build();
new Runner(options).run();
}
}
测试出来的结果显示:
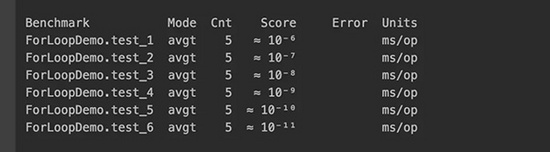
循环越多,反而得分越低,这一结果反而越来越不可信。
关于为什么在Benchmark中跑循环代码会出现这类不可信的情况,我在网上搜了一下技术文章,大致归纳为以下:
- 循环展开
- JIT & OSR 对循环的优化
感兴趣的朋友可以自行去深入了解,这里我就不做过多介绍了。
通过这个实验可以发现,以后进行Benchmark的性能测试过程中,尽量能不跑循环就不要跑循环,如果真的要跑循环,可以看下官方的这个用例:
JMH-samples/JMHSample_34_SafeLooping.java at master · lexburner/JMH-samples · GitHub
Fork注解中的进程数一定要大于0
这个是我通过实验发现的,如果设置为小于0的参数会发现跑出来的效果和预期的大大相反,具体原因还不太清楚。
测试结果报告的参数解释
最后是关于如何阅读JMH的测试报告,这里的这份报告是上边讲解的代码案例中的测试结果。由于报告的内容量比较大,所以这里只挑报告的结果来进行讲解:
Benchmark Mode Cnt Score Error Units JMHHelloWord.baseMethod thrpt 10 14343234.962 ± 585752.043 ops/ms JMHHelloWord.measureRight thrpt 10 260749.234 ± 5324.982 ops/ms JMHHelloWord.measureWrong thrpt 10 524449.863 ± 8330.106 ops/ms
从报告的左往右开始介绍起:
- Benchmark 就是对应的测试方法。
- Mode 测试的模式。
- Cnt 循环了多少次。
- Score 是指测试的得分,这里因为选择了以thrpt的模式进行测试,所以分值越高表示吞吐率越高。
- Error 代表并不是表示执行用例过程中出现了多少异常,而是指这个Score的精度可能存在误差,所以前边还有个± 的符号。
关于Error的解释,在stackoverflow中也有解释:
java - JMH Benchmark Metrics Evaluation - Code Review Stack Exchange
如果你希望报告不是输出在控制台,而是可以汇总到一份文档中,可以通过启动指令去设置,例如:
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(StringBuilderBenchmark.class.getSimpleName())
.output("/Users/linhao/IdeaProjects/qiyu-framework-gitee/qiyu-framework/qiyu-framework-jmh/log/test.log")
.build();
new Runner(options).run();
}
希望能帮助到你!
需要领取免费资料的小伙伴们,添加小助手vx:SOSOXWV 即可免费领取资料哦!

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









