



 本文介绍了逻辑回归的基本概念,包括其作为监督学习方法处理二分类和多分类问题的过程,以及通过极大似然估计和梯度下降求解参数。文章还对比了逻辑回归与线性回归的区别,强调了交叉熵作为损失函数的优势。同时讨论了生成式模型和判别式模型的差异及其应用场景.
本文介绍了逻辑回归的基本概念,包括其作为监督学习方法处理二分类和多分类问题的过程,以及通过极大似然估计和梯度下降求解参数。文章还对比了逻辑回归与线性回归的区别,强调了交叉熵作为损失函数的优势。同时讨论了生成式模型和判别式模型的差异及其应用场景.
摘要
本周对逻辑回归进行复习,通过逻辑回归预测神奇宝贝比生成模型预测的数值更加准确。逻辑回归也称作logistic回归分析,是一种广义的线性回归分析模型,属于机器学习中的监督学习。其推导过程与计算方式类似于回归的过程,但实际上主要是用来解决二分类问题(也可以解决多分类问题)。通过给定的n组数据(训练集)来训练模型,并在训练结束后对给定的一组或多组数据(测试集)进行分类。其中每一组数据都是由p 个指标构成。
Abstract
This week, we will review the use of logistic regression to predict Pokemon more accurately than generating model predictions. Logistic regression, also known as logistic regression analysis, is a generalized linear regression analysis model that belongs to supervised learning in machine learning. The derivation process and calculation method are similar to the process of regression, but in reality, they are mainly used to solve binary classification problems (and can also solve multi classification problems). Train the model through a given set of n data (training set), and classify the given set or sets of data (test set) after the training is completed. Each set of data is composed of p indicators.
逻辑回归
前提
在之前的学习中有学习过生成模型,使用生成模型 + 贝叶斯概率分布进行分类问题的三个步骤:首先我们找一堆高斯模型作为模型集,然后用极大似然估计来定义模型的好坏,即可选出最好的模型。整个过程本质上是寻找参数w和b的过程,如果直接进行参数w和b的求解,是不是就可以简化前面那么复杂的计算过程?这也是逻辑回归算法。之前的学习并未写出逻辑回归的具体步骤,故本次周报对这部分内容进行补充学习。
概念
逻辑回归假设数据服从伯努利分布(即数据的标签为0或者1),通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据分类的目的。
逻辑回归步骤
第一步:定义函数集合。
逻辑回归的公式:
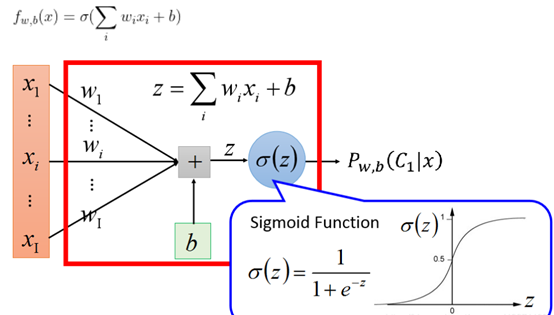
每个特征xi都有一个权重,然后加上偏置,输入到sigmoid函数里,输出值为(0,1)之间,如果结果大于等于0.5,则认为是类1,否则是类2。
第二步:损失函数
逻辑回归中,用1代表类别1,用0代表类别2。所有样本的交叉熵总和作为损失函数。而线性回归中,是一个真实的数。
有一组训练集:

假设我们的数据都来自后验概率模型Pw,b(C1∣X)生成的,记做fw,b(x)。假设我们的样本是独立同分布的,可以计算这一组w和b产生N组训练数据的几率:
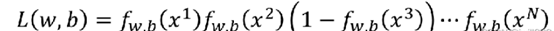
根据最大似然原理,要找到一组参数w∗,b∗,使得 L(w,b)的值最大
求最大可以转换为求最小的负对数L(w,b),取对数对函数增减性没影响,即
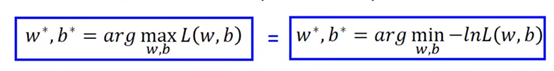
−lnL(w,b)乘积形式就可以转化为每一个相加的形式,用1表示x属于类别1,0表示x属于类别2。
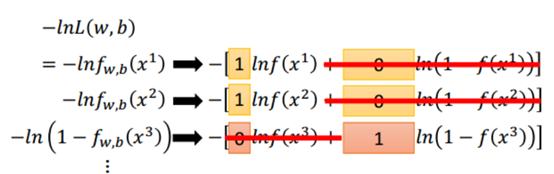
即推导出:

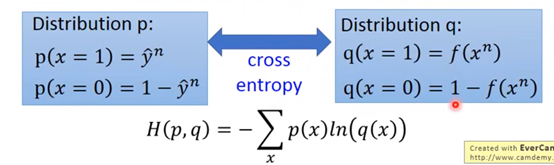
最下面的式子其实就是交叉熵,代表两个分布有多接近。
比如下图两个二项分布,p是真实的分布,q是我们的预测模型分布,我们希望这两个分布越近越好,如果交叉熵为0,,那我们的模型的分布就等同于真实分布了:
第三步:参数更新
使用梯度下降法,求偏微分。
sigmoid函数的微分可以直接记为σ(z)(1-σ(z))

于是
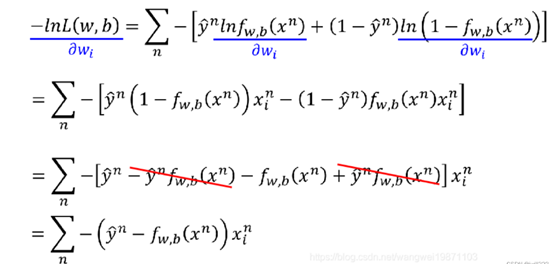
使用梯度下降法进行更新,式子如下:
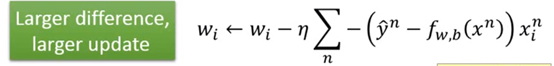
可见真实和预测之间的差距越大,更新幅度也越大。
逻辑回归和线性回归的比较
第一步:目标输出不同。逻辑回归的输出是0-1之间的。
第二步:损失函数不同。逻辑回归中,用1代表类别1,用0代表类别2。所有样本的交叉熵总和作为损失函数。而线性回归中,是一个真实的数。
第三步:参数更新方式相同。紫色部分的值不一样,一个是0到1,一个是任意数。

为什么不使用MSE
如果我们在损失函数部分,使用和线性函数一样的均方误差作为损失函数,那么参数wi的更新过程如下:

也就是说,y^=1的时候,预测为1,离目标很近,导数是0,这是对的,但是另外一种情况,我们预测为0,应该离目标很远,按道理应该有比较大的导数,居然也是0。
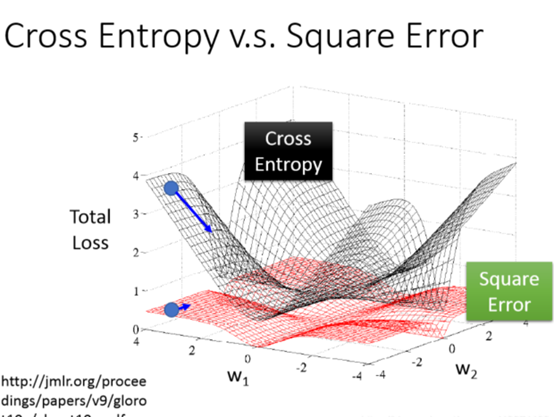
无论是结果离目标很远或者很近,偏微分都可能取到0,所以均方差损失函数貌似对分类不合适,下面是他们的损失函数的三维图,可以看到均方差在离最低点的很远的时候有平坦的地方,导数可能为0,而交叉熵没有,交叉熵越远,导数越大,更新幅度越大:
生成式模型和判别式模型的差别就在于生成式模型做出了一些假设,假设符合高斯分布或伯努利分布,假设朴素贝叶斯。脑补到底好不好呢,生成式模型也是有一定优势的:
①训练数据很少(判别式模型的结果受到数据量的影响很大,只要数据够多,效果就越好,如果数据少,生成模型可能会比较好点,受到数据量影响小,因为它可以自行做出一些假设)
②数据有噪声(数据有噪声意味着标签本身有可能就是有问题的,因为生成式模型可以做出一些假设,反而可以忽视掉数据中有问题的部分)
③由于判别式模型是直接假设一个后验概率,然后再求解这个后验概率的参数,但是生成式模型是把整个公式拆解成先验概率和类的概率这两项,这样先验概率和类的概率这两项是可以来自不同的来源的。比如语音识别,其实他是个生成模型,判别模型只是一部分,还有有部分是一个先验概率,就是说出某句话的概率,是从很多语句里面统计出来的概率。
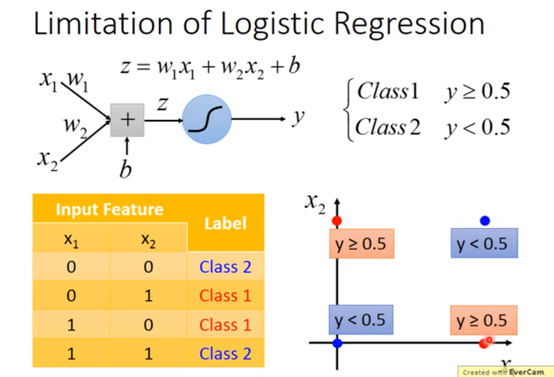
逻辑回归的限制
假设我们要用逻辑回归来分下面的例子,逻辑回归的分界线始终是一条直线,一条直线始终无法把红色的点和蓝色的点分成两个类别。
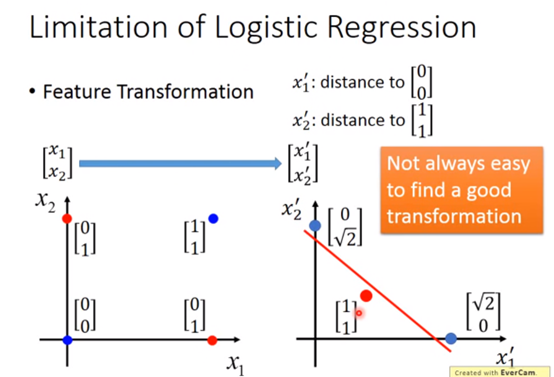
如果还是要用逻辑回归的话,这个时候就可以用到特征空间的转换,把x1′设为某点到(0,0)的距离,x2′设为某点到(1,1)的距离,刚好红线可以分割:
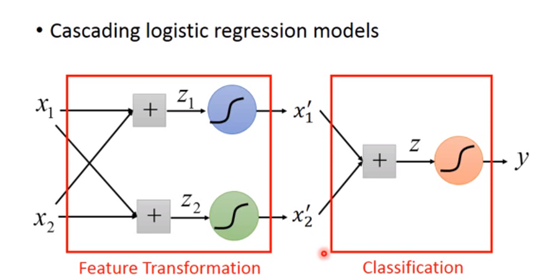
但是很多时候我们是不知道要怎么要转换的,希望机器可以自己学着去转换,可以把很多个逻辑回归组合起来。上面的例子我们可以用两个逻辑回归的,刚好转换到两个新坐标上,然后再接一个逻辑回归来进行线性分类:
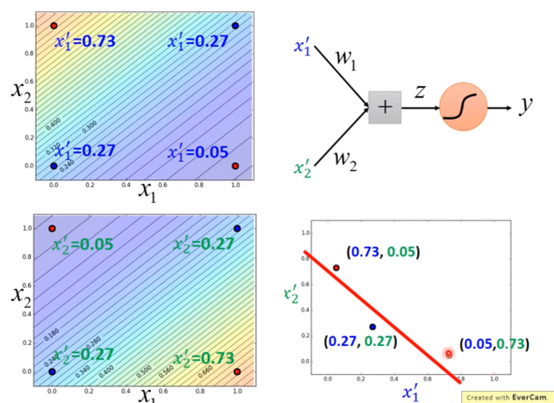
把一个逻辑回归叫做一个神经元,这些神经元形成的网络称为神经网络。
总结
生成式模型:学习得到联合概率分布P(X,Y),然后再求条件概率分布。能够学习数据的生成机制。例如隐马尔可夫模型,朴素贝叶斯,LDA等。(学习多个模型)
计算思路:学习全部样本的先验和条件概率分布求出后验概率。
优点:①可以通过联合概率分布获取其他信息 ②收敛速度快(适用数据多) ③能应付存在隐变量的情况(高斯模型) ④可以进行异常检测
缺点:①联合概率计算量大
判别式模型:学习条件概率分布。例如SVM,感知机,决策树,KNN,CRF等。(学习一个模型)
计算思路:直接学习得到条件概率分布。
优点:①节省计算资源 ②需要的样本数量小 ③准确率较高
缺点:①得到的信息少

















 635
635




 到【灌水乐园】发言
到【灌水乐园】发言







