






 本文介绍了动态网页抓取的基本概念,包括AJAX技术和使用浏览器审查元素解析真实网页地址。详细讲解了如何利用Selenium模拟浏览器进行抓取,包括安装、配置及常见操作,如定位元素、模拟点击等。此外,还提到了通过控制CSS、图片和JavaScript加载来提升Selenium爬取效率的方法。
本文介绍了动态网页抓取的基本概念,包括AJAX技术和使用浏览器审查元素解析真实网页地址。详细讲解了如何利用Selenium模拟浏览器进行抓取,包括安装、配置及常见操作,如定位元素、模拟点击等。此外,还提到了通过控制CSS、图片和JavaScript加载来提升Selenium爬取效率的方法。
网络爬虫学习笔记(2)
1 资料
- 《Python网络爬虫从入门到实践》唐松,陈志铨。主要面向windows平台下的python3。
2 笔记
2-1 动态抓取概述
在使用JavaScript时,很多内容并不会出现在HTML源代码中,所以爬取静态网页的技术可能无法正常使用。因此,我们需要用到动态网页抓取的两种技术:通过浏览器审查元素解析真实网页地址和使用selenium模拟浏览器的方法。
- 异步更新技术AJAX(Asynchronous Javascript And XML,异步JavaScript和XML),通过在后台与服务器进行少量数据交换就可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下对网页的某部分进行更新。例如百度搜索界面的皮肤:

- 爬取里面使用AJAX动态加载的内容的两种方法:
(1)通过浏览器审查元素解析地址。
(2)通过Selenium模拟浏览器抓取。 - json数据直接打印显得又多又乱,可以使用json库提取想要的信息
2-2 通过浏览器审查元素解析真实网页地址
- chrom浏览器右键菜单“检查”
- 单击“Network”选项,然后刷新网页。此时,Network会显示浏览器从网页服务器中得到的所有文件,一般这个过程称为“抓包”。
- 找到真实的数据地址。选择需要的文件,单击Preview标签即可查看数据,而Headers标签里则可以找到数据地址(就是Request URL那一项)。
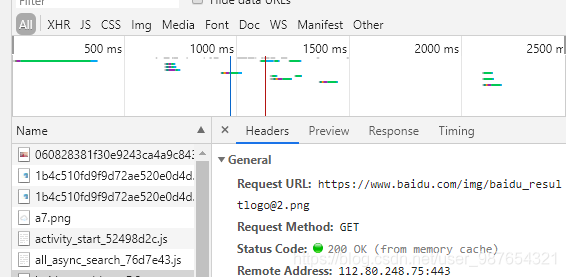
- 获得了地址,再想爬取就只用把link换成3里找到的数据地址。
2-3 网页URL地址的规律
例如有些URL地址中有两个特别重要的变量offset和limit,offset显示本页第一项是总的第几项,limit表示每页项目数。基于此,书中给了一个很好的例子(这个例子中,不同页数的评论真实地址之间只体现在offset,所以才有page_str这个变量):
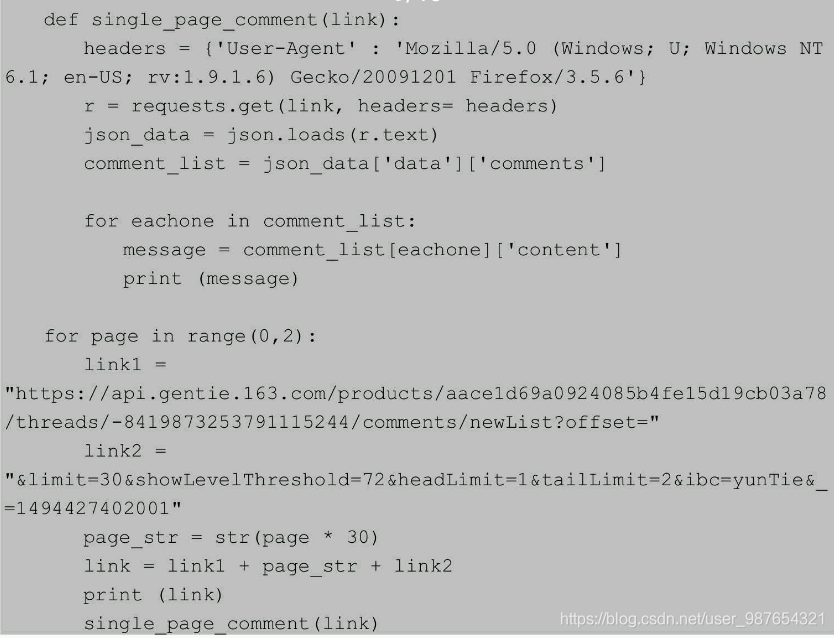
2-4 json库
- 使用:
(1)引入json库import json
(2)使用json.loads把字符串格式的响应体数据转化为json数据json_date = json.load(req_1.text)
2-5 通过Selenium模拟浏览器抓取
使用本方法无需2-1的操作,直接用网页网址即可
因此,这里介绍另一种方法,即使用浏览器渲染引擎。直接用浏览器在显示网页时解析HTML、应用CSS样式并执行JavaScript的语句。
这个方法在爬虫过程中会打开一个浏览器加载该网页,自动操作浏览器浏览各个网页,顺便把数据抓下来。用一句简单而通俗的话说,就是使用浏览器渲染方法将爬取动态网页变成爬取静态网页。
我们可以用Python的Selenium库模拟浏览器完成抓取。Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,浏览器自动按照脚本代码做出单击、输入、打开、验证等操作,就像真正的用户在操作一样。
- 安装
pip install selenium - 下载geckodriver,在环境变量的PATH中加入这个geckodriver的地址
- 要使用浏览器,可能会需要相应的driver,例如Chromedriver。关于Chromedriver的下载,可以参考这个博客:
ChromeDriver与Chrome版本对应参照表及ChromeDriver下载链接 - 上述内容的简单例子:
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import WebDriver
# 产生DesiredCapabilities()对象,并修改对应字典的默认值,不过对于使用chrom暂时没什么用
caps = webdriver.DesiredCapabilities().CHROME
# 要调用的浏览器driver地址,根据浏览器不同实现方式会有所差别
# chrom.webdriver里对应的参数需要的是一个字符串,如果不给数据它会去找$PATH
executable_path = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe'
# 产生对象
driver = WebDriver(executable_path=executable_path)
driver.get('https://greasyfork.org/zh-CN/scripts')
- 书中给的例子仍旧是评论,在driver调用get()以后,
driver.find_element_by_css_selector表示用CSS选择器查找元素,找到class为bdy-inner的div元素;find_element_by_tag_name表示通过元素的tag寻找,意思是找到comment中的p元素。
具体增加代码

检查可以看到的内容
运行上述代码,得到的结果是:“第35条测试评论” - 书中还提及单击特定位置的方法:
使用driver.find_element_by_css_selector()(还有许多其他查找方法,这里只提这一种)找到该元素,然后使用.click()方法模拟单击
load_more = driver.find_element_by_css_selector('div.tie-load-more')
load_more.click()
- Selenium中通过
find_element_by_xpath()和find_element_by_css_selector()查找比其他查找函数好一些。 - Selenium常见的操作元素方法
·Clear清除元素的内容。·send_keys模拟按键输入。·Click单击元素。·Submit提交表单。 - 用Selenium控制浏览器加载的内容(火狐使用
FirefoxProfile().set_preference()函数调整),可以加快Selenium的爬取速度,常用的方法有:
(1)控制CSS(用来控制页面的外观和元素放置位置的)的加载。
(2)控制图片文件的显示。
(3)控制JavaScript的运行。 - Selenium的官方网站

















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









