




 本文深入解析GridWorld强化学习示例,探讨视觉观察值在Agent训练中的应用,以及如何使用动作遮罩提升决策效率。
本文深入解析GridWorld强化学习示例,探讨视觉观察值在Agent训练中的应用,以及如何使用动作遮罩提升决策效率。
GridWorld这个例子比较有意思,它还是运用了Reinforcement Learning来进行学习的,不同的是它运用了视觉观察值(Visual Observations)来训练agent。
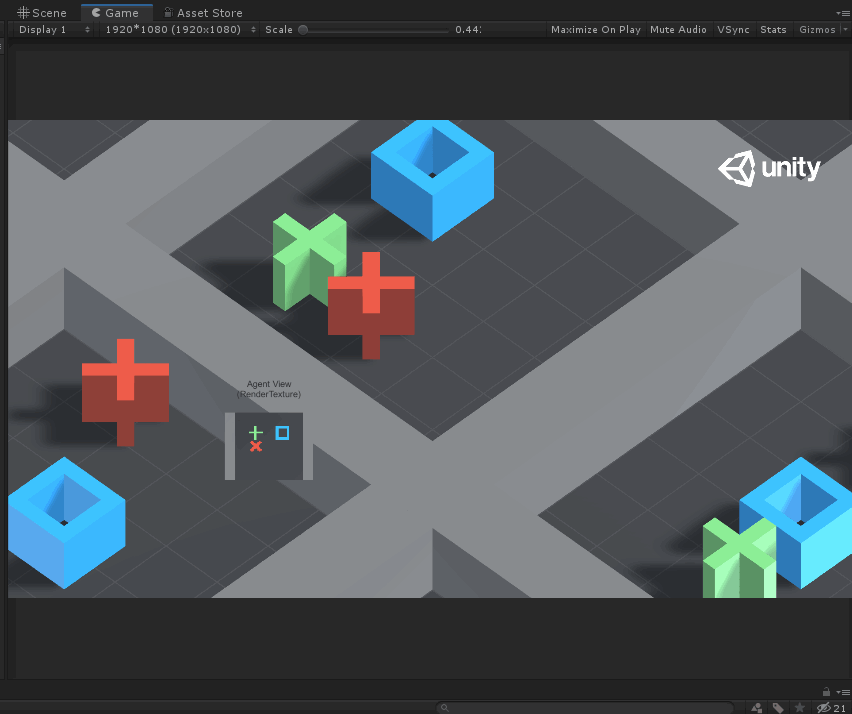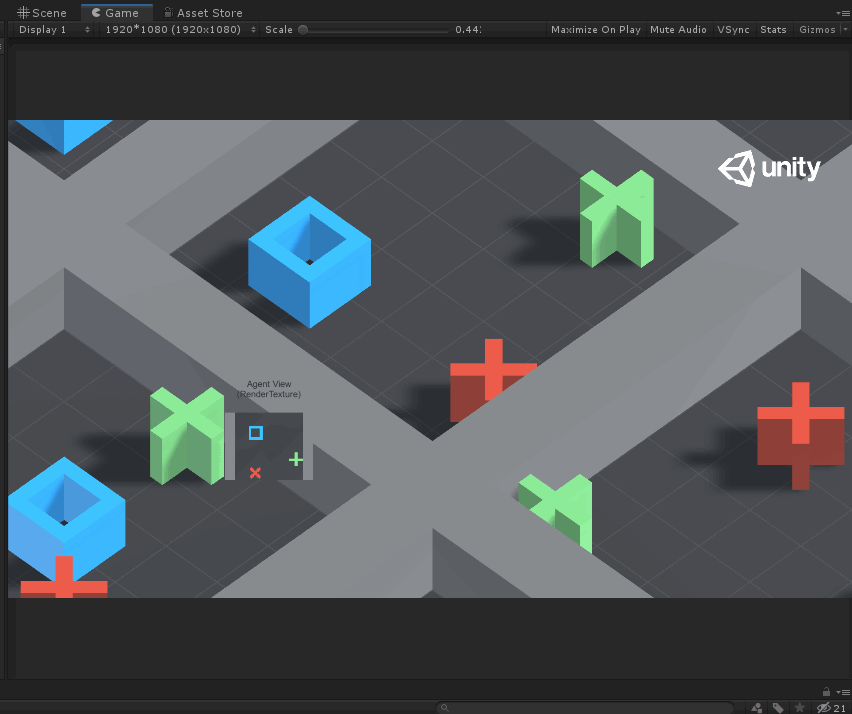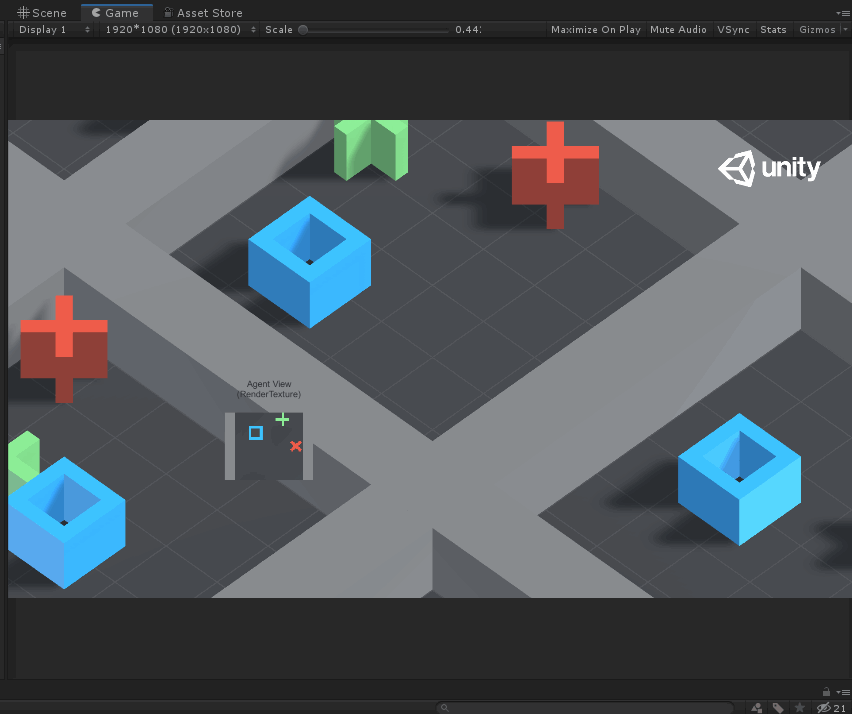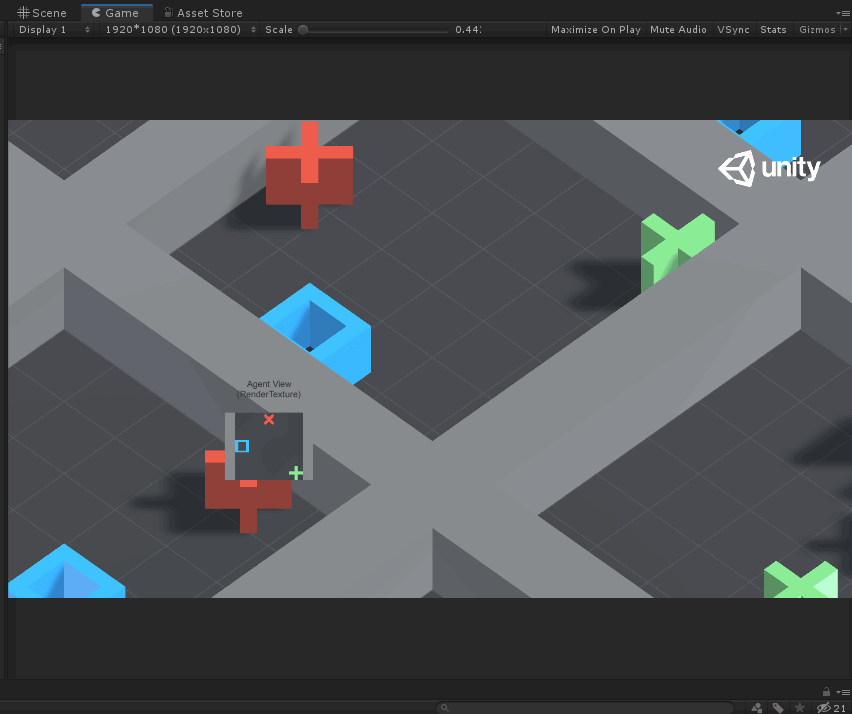
如上图所示,Agent就是蓝色的方块,每次它可以移动一格(上、下、左、右),要求不能碰到红叉,最终到达绿色加号目标。
Visual Observations
先来了解一下视觉观察值是怎么回事。在ml-agents里主要通过CameraSensor或RenderTextureSensor两种方式来向Agent提供视觉观察。通过这两个组件收集的图像信息输入到agent policy的CNN(卷积神经网络)中,这使得agent可以从观察图像的图像规律中学习。Agent可以同时使用视觉观察值( Visual Observations)和矢量观察值( Vector Observations)。
使用视觉观察可以使得Agent可以捕获任意复杂的状态,并且在难以用数字描述的状态时非常有用。当然,视觉观察训练相比矢量观察训练,效率低、速度慢,而且有时完全不能成功。因此,只有当使用vector observations或者ray-cast observations(之后会研究到,是射线观察)不能解决问题时,才使用visual observations。
视觉观察结果可以从场景中的Cameras或者RenderTextures获得。为了给agent添加视觉观察组件,需要在agent上添加Camera Sensor Component或者Render Texture Sensor Component组件,然后将Camera或者RenderTexture拖入相应的地方(如下图)。同时给一个Agent可以加一个以上的camera或者render texture组件,甚至可以两种组件进行组合。对于每个视觉观察组件,需要设置图像的宽度和高度(以像素为单位),以及观察值是彩色还是灰色。
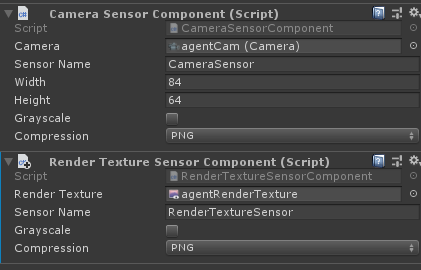
使用相同策略的Agent必须有相同数量的visual observations,并且这些视觉组件需要有相同的分辨率(包括灰度设置)。另外,在Agent的Sensor Component必须有自己单独的Sensor Name以便可以确定地对其排序(名称对于该Agent必须是唯一的,但是多个Agent可以具有同名的Sensor组件)。
当使用Render Texture Sensor Component组件时,可以利用Canvas来调试,需要将在Canvas下建立带有Raw Image组件的物体,然后将Agent的RenderTexture设置到Raw Image的Texture中,例如下图。
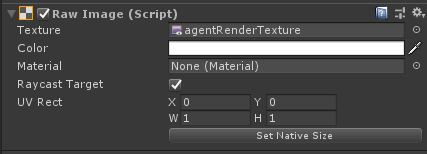
Grid World示例则是展示了怎样去使用RenderTexture组件去调试和观察。注意,在此示例中,将Camera渲染为RenderTexture,然后将其用于观察和调试。为了更新RenderTexture,Camera必须在代码中要求每次做出决定时,都需要进行画面渲染。当直接使用Camera作为观察值时,Agent会自动完成此操作。
-
Visual Observation总结&最佳实践
-
为了收集视觉观察值,需要给GameObject添加CameraSensor组件或RenderTextureSensor组件
-
除非vector observations不充分,否则通常应使用visual observation
-
Image的大小应该尽可能小,不丢失决策所需的细节
-
对于不需要颜色信息来做出决策的情况下,Image应该使用Greyscale(灰度图)
Masking Discrete Actions
除了Visual Observation,在这个示例中还使用了action mask。下面也先来介绍一下这个概念。
当我们使用离散动作反馈(Discrete Actions)时,可以指定某些动作对于下一决策是不可能发生的。即当Agent被神经网络控制时,agent将无法执行指定的操作。注意,当agent被人为控制时(Heuristic Type),agent仍然能够决定执行被屏蔽的操作。为了屏蔽某些动作,需要在Agent脚本中重写Agent.CollectDiscreteActionMasks()虚函数,同时需要在函数中调用DiscreteActionMasker.SetMask(),如下图
public
override
void
CollectDiscreteActionMasks
(
DiscreteActionMasker actionMasker
)
{
actionMasker
.
SetMask
(branch
, actionIndices
)
}
其中:
-
branch:你想屏蔽操作分支的索引(从0开始)
-
actionIndices:对应于agent无法执行操作的索引相对应的int列表
上面的branch就是Behviour Parameters组件中Vector Action中Branches Sizes属性。
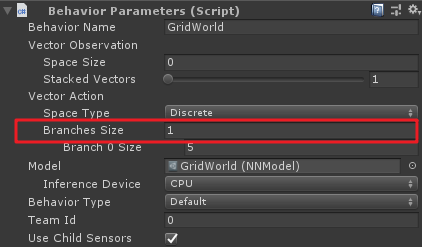
例如,如果一个Agent有两个branch,第一个branch(branch 0)有四个动作枚举:"do nothing", "jump", "shoot" and "change weapon",分别对应索引值0,1,2,3。如果Agent需要在shoot时不可以jump且change weapon,则代码如下:
public
override
void
CollectDiscreteActionMasks
(
DiscreteActionMasker actionMasker
)
{
if
(agent
.action
==
3
)
//伪代码,意思是当agent动作为shoot时
actionMasker
.
SetMask
(
0
,
new
int
[
2
]
{
1
,
3
}
)
;
//重点是这句
}
Notes:
-
如果你想在多个branch上遮罩,你可以使用Set Mask多次
-
不可以将一个branch上的所有动作都遮罩
-
不能遮罩Continuous Type 中的连续动作
OK,有以上基础,下面就来研究一下Grid World示例。
环境与训练参数
先来根据官方文档参数翻译一下项目参数:
-
设定:场景包含代理、目标和障碍
-
目标:agent必须在找到目标的同时,避开障碍
-
Agent:环境中包含九个具有相同行为参数的Agent
-
Agent奖励设定
-
每一步都-0.01f(为了使得代理以最短路径找到目标)
-
如果agent找到目标(绿色加号)的位置,则+1,同时重新开始下一次
-
如果agent导航到障碍物(红色叉)处,则-1,同时重新开始下一次
-
行为参数
-
矢量观察值(Vector Observations):无
-
矢量动作空间:(离散Discrete类型)Size为4,对应代理上下左右四个方向运动。此外,在环境中,默认情况下会启动动作遮罩(action masking,可以在对应组件上进行勾选开启或关闭)。源工程中提供的训练模型是在启动屏蔽的情况下生成的。这里利用action mask其实就是限制蓝色方块代理不要走出grid的范围,后面看代码就知道了。
-
视觉观察值(Visual Observations):对应GridWorld自顶向下的视图
-
泛化参数:gridSize,障碍物数量(numObstacles)和目标数量(numGoals)三个。具体关于泛化的解释请查看之前的文章
-
基准平均奖励:0.8
场景基本结构
以一个基本的Agent为单位,先看一下在Scene视图中:
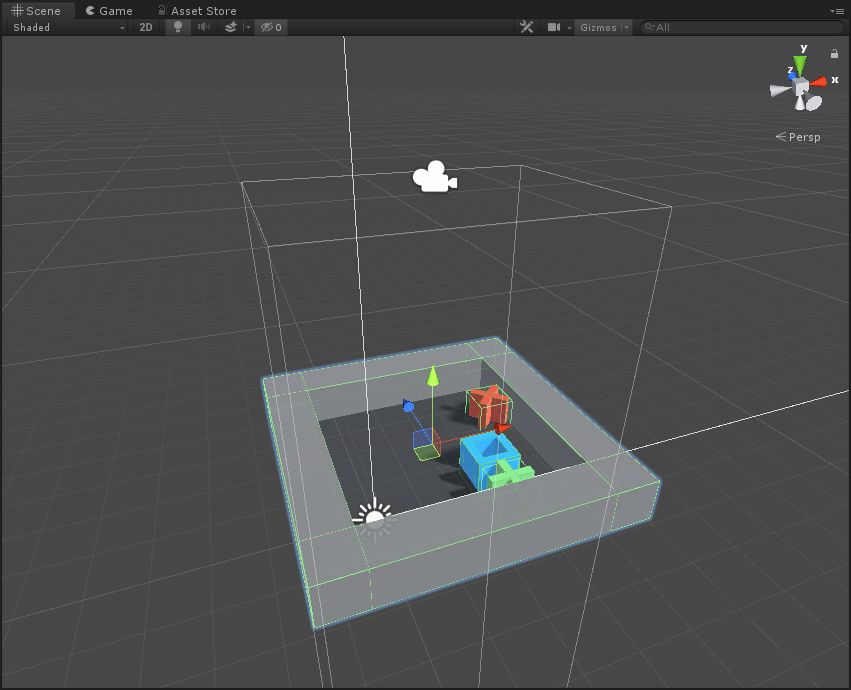
其Hierarchy层级为:

其中scene为组成Grid范围的父物体,包括一个plane和四个墙体;RenderTextureAgent则是蓝色方块,即为agent;agentCam为渲染相机,通过该相机观察而渲染得到的Texture就作为CNN的输入数据;pit和goal分别代表了障碍物和目标,这里是在运行时才在grid中随机位置生成。
注意这里的父节点AreaRenderTexutre上挂有Grid Area脚本,该脚本主要是初始化环境(包括墙体生成,目标、障碍随机生成等)、重置Agent以及环境的作用。
此外,你会发现这个AreaRenderTexutres单元和其他训练单元不同,因为该训练单元的Camera负责渲染输出了RenderTexture,即在运行时的小画面。
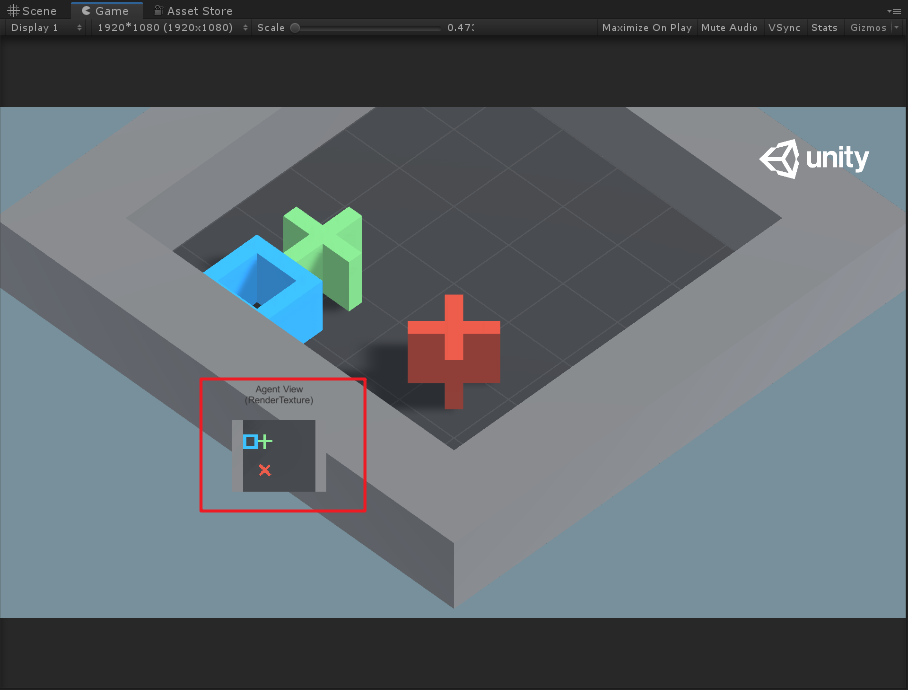
代码分析
环境初始化代码
GridArea.cs
using
System
.
Collections
.
Generic
;
using
UnityEngine
;
using
System
.
Linq
;
using
MLAgents
;
using
MLAgents
.
SideChannels
;
public
class
GridArea
:
MonoBehaviour
{
[
HideInInspector
]
public
List
<
GameObject
> actorObjs
;
//障碍物和目标物GameObjects List
[HideInInspector
]
public
int
[
] players
;
//障碍物和目标物数组,其中“1”的个数代表障碍物个数,“0”的个数代表目标个数
public
GameObject trueAgent
;
//代理
public
GameObject goalPref
;
//目标预制体
public
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5238
5238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









