




前言
在当今数据驱动的时代,数据处理与分析已成为各行业不可或缺的技能。python中Pandas,它以简洁的语法和强大的功能,成为了数据处理必备工具。本文将带您深入了解 Pandas,从使用场景到核心功能,再到实际案例,展示这个数据处理能力
Pandas 的使用场景
Pandas 的应用范围极为广泛,几乎涵盖了所有需要数据处理的领域:
- 数据清洗与预处理:处理缺失值、异常值,转换数据格式,规范化数据等
- 数据分析与探索:进行描述性统计分析,如计算均值、中位数、标准差等
- 数据聚合与分组:按不同维度对数据进行分组统计,如按时间统计用户活跃度等。
- 时间序列分析:处理与时间相关的数据,支持时间索引、重采样等操作。
- 数据合并与连接:将多个数据源的信息整合在一起,类似于数据库中的 join 操作。
Pandas 的核心功能
Pandas 的核心功能围绕两种数据结构展开:Series 和 DataFrame。
- Series:一维数组结构,类似于带标签的数组,标签可以是整数、字符串等,支持索引操作和基本的数学运算。
- DataFrame:二维表格结构,由多个 Series 组成,既有行索引也有列索引,是 Pandas 中最常用的数据结构,可看作是 Excel 表格或数据库表的等效数据结构。
基于这两种数据结构,Pandas 提供了丰富的功能:
- 数据读取与写入:支持读取 CSV、Excel、JSON、SQL 等多种格式的数据,并能将处理后的数据写入到这些格式中。
- 索引与选择:灵活的索引方式,可通过标签、位置等多种方式选择数据的行和列。
- 数据清洗:提供了处理缺失值(如 dropna ()、fillna ())、重复值(如 drop_duplicates ())的方法。
- 数据转换:包括数据类型转换(astype ())、字符串处理(str 属性)、apply () 函数实现自定义转换等。
- 分组与聚合:groupby () 函数实现数据分组,结合 agg () 等函数进行聚合操作。
- 合并与连接:merge ()、concat () 等函数实现多个 DataFrame 的合并。
Pandas 使用案例
下面通过一个实际案例来展示 Pandas 的使用。购买数据(data.csv),包含用户 ID、购买时间、商品类别、购买金额等信息,我们将使用 Pandas 进行分析。
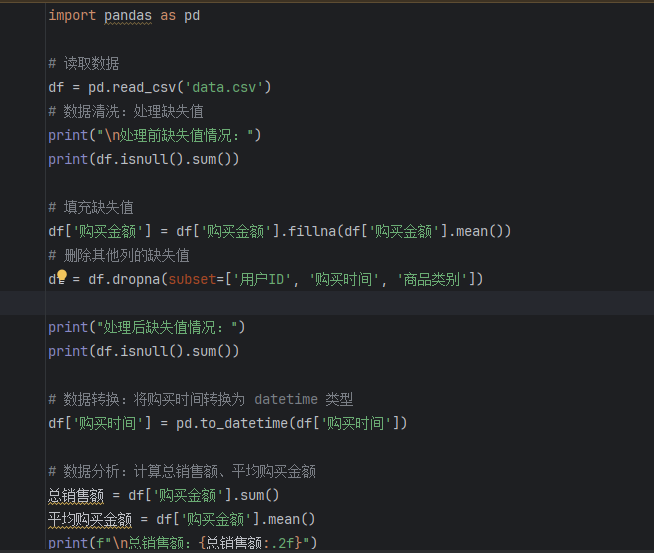
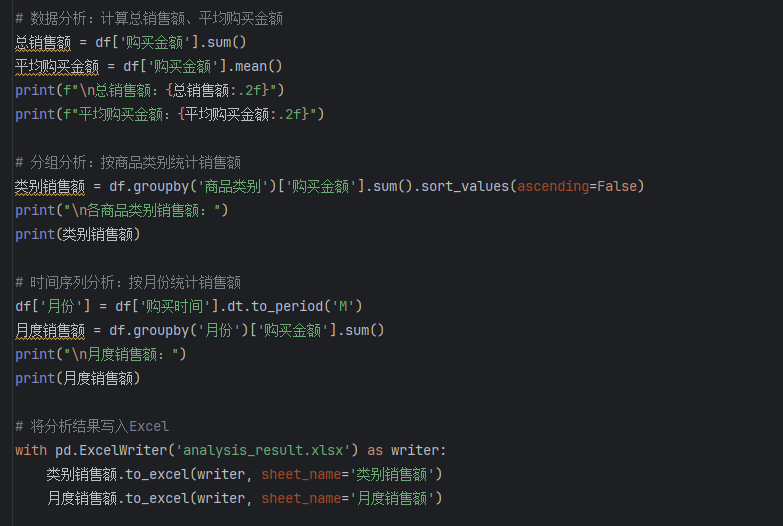
在这个案例中,我们首先读取了 CSV 格式的数据,查看了数据的基本信息和缺失值情况,并进行了相应的清洗处理。然后将购买时间转换为 datetime 类型,方便后续的时间序列分析。接着计算了总销售额和平均购买金额等基本统计量,通过分组分析得到了各商品类别的销售额和月度销售额,最后将分析结果写入 Excel 文件。
结尾语
Pandas 作为 Python 数据处理的核心库,以其简洁高效的特点,极大地提升了数据处理和分析的效率。无论是数据清洗、转换,还是复杂的分组聚合、时间序列分析等。
当然,Pandas 的功能远不止本文所介绍的这些,还有更多高级特性和技巧等待我们去探索。


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









