




 该文详细介绍了如何部署Zookeeper和Kafka集群。首先,提供了Zookeeper和Kafka的下载及解压步骤,然后配置Kafka服务,包括设置broker.id、advertised.listeners、log.dirs和zookeeper.connect。接着,配置Zookeeper服务,指定dataDir和dataLogDir。创建启动和停止脚本简化管理,并设置环境变量。最后,创建生产者和消费者topic进行测试。
该文详细介绍了如何部署Zookeeper和Kafka集群。首先,提供了Zookeeper和Kafka的下载及解压步骤,然后配置Kafka服务,包括设置broker.id、advertised.listeners、log.dirs和zookeeper.connect。接着,配置Zookeeper服务,指定dataDir和dataLogDir。创建启动和停止脚本简化管理,并设置环境变量。最后,创建生产者和消费者topic进行测试。
所需配置
zookeeper集群
kafka集群
zookeeper部署
写过文章了,详情点击连接跳转即可
kafka部署
下载kafka
在kafka官网下载所需要的版本(不要下载源文件,源文件是还没有编译的,后面运行会报错,下载编译后的)
百度网盘下载本次案例的kafka压缩包
本次案例kafka版本:kafka_2.13-3.4.0
链接:https://pan.baidu.com/s/1MzKLP60HYcUr5KvyCgAFFQ
提取码:yyds
2.解压kafka
1.上传压缩包到所需要的位置(我的上传位置是:/usr/local/kafaka)
2.解压
tar -zxvf kafka_2.13-3.4.0.tgz3.部署kafka
在kafka解压路径下新建一个文件夹:kafka-logs ,用来装log和数据等等
如果想把zookeeper的log和数据内容都放一起好看的话,可以再多创建几个目录分别存放
mkdir -p /usr/local/kafaka/kafka_2.13-3.4.0/kafka-logs配置kafka服务
cd /mnt/kafka_2.12-2.4.1/config/
#编辑修改相应的参数,内容改动和添加如下:
vim server.propertiesbroker.id=0
#地址加端口号
advertised.listeners=PLAINTEXT://127.0.0.1:9092
#日志文件存放路径(刚刚的kafka-logs路径)
log.dirs=/usr/local/kafaka/kafka_2.13-3.4.0/kafka-logs
#zookeeper地址和端口,单机配置部署,localhost:2181
zookeeper.connect=127.0.0.1:2181
#保存退出
:wq配置zookeeper服务
如果想把zookeeper的log和数据内容都放一起好看的话,就按下面配置,配置过,懒得调就跳过
cd /zookeeper/apache-zookeeper-3.7.1-bin/config/
#编辑修改相应的参数,内容改动和添加如下:
vim zoo.cfg#zookeeper数据目录
dataDir=上面kafka下的目录
#zookeeper日志目录
dataLogDir =上面kafka下的目录
#端口号
clientPort=2181
maxClientCnxns=100
tickTimes=2000
initLimit=10
syncLimit=5
:wq4.创建启动类
cd /usr/local/kafaka/kafka_2.13-3.4.0/1. 创建启动脚本
vim kafka_start.sh里边内容为:
#!/bin/sh
#启动zookeeper
/usr/local/kafaka/kafka_2.13-3.4.0/bin/zookeeper-server-start.sh /usr/local/kafaka/kafka_2.13-3.4.0/config/zookeeper.properties &
#等3秒后执行
sleep 3
#启动kafka
/usr/local/kafaka/kafka_2.13-3.4.0/bin/kafka-server-start.sh /usr/local/kafaka/kafka_2.13-3.4.0/config/server.properties &2. 创建关闭脚本
vim kafka_stop.sh里边内容为:
#!/bin/sh
#关闭zookeeper
/usr/local/kafaka/kafka_2.13-3.4.0/bin/zookeeper-server-stop.sh /usr/local/kafaka/kafka_2.13-3.4.0/config/zookeeper.properties &
#等3秒后执行
sleep 3
#关闭kafka
/usr/local/kafaka/kafka_2.13-3.4.0/bin/kafka-server-stop.sh /usr/local/kafaka/kafka_2.13-3.4.0/config/server.properties &3.为脚本执行权限
chmod +x kafka_start.sh
chmod +x kafka_stop.sh4.配置环境变量
vim /etc/profile添加配置
export KAFKA_HOME=/usr/local/kafaka/kafka_2.13-3.4.0
export PATH=KAFKA_HOME/bin:$PATH使配置生效
source /etc/profile5.创建生产者 topic 和 消费者 topic 简单示例测试
启动kafka
sh kafka_start.sh2.进入bin, 生成生产者
#进入kafka目录
cd /usr/local/kafaka/kafka_2.13-3.4.0/bin/
# wd_test是生成的topic名称,可改
./kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic wd_test3.新建一个终端,进入bin,生成消费者
#进入kafka目录
cd /usr/local/kafaka/kafka_2.13-3.4.0/bin/
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic wd_test最终结果如下
生成者
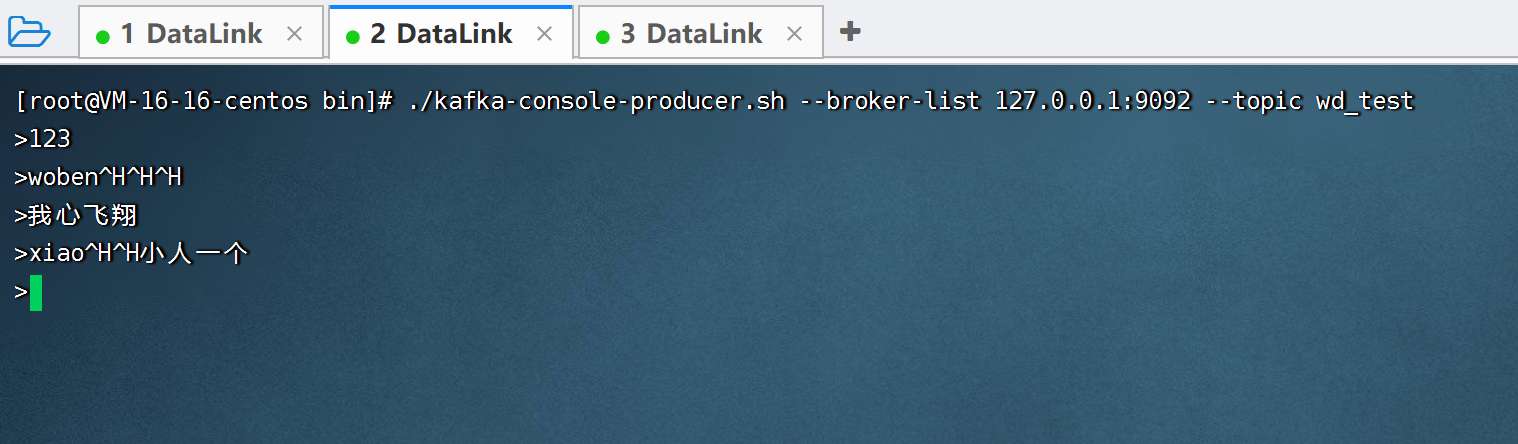
消费者
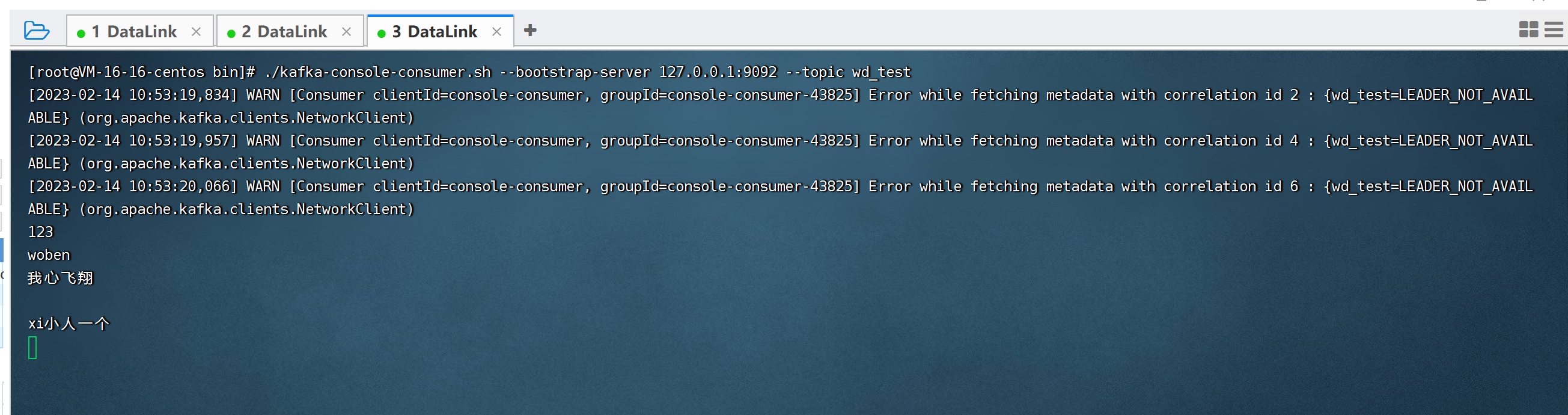


















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









