



 本文介绍了如何通过域名访问互联网服务,涉及DNS解析、HTTPD服务器安装与配置,展示了从网址到IP的路径。重点讲解了c/s与b/s架构,以及Apache HTTPD服务器的实践操作。
本文介绍了如何通过域名访问互联网服务,涉及DNS解析、HTTPD服务器安装与配置,展示了从网址到IP的路径。重点讲解了c/s与b/s架构,以及Apache HTTPD服务器的实践操作。
1.访问网站方法概念
有人互联网上设置了一台服务器,提供了服务,并监听一个包含端口的地址,用户就可以通过该监听的主机ip地址和端口进行访问
即通过ip+port 来进行访问,也叫套接字(socket)访问
而ip地址难以记述,为了方便人们记忆,主机名就出现了,也就是所谓的网址,例如“www.baidu.com”,主机名一定对应着一个地址,所以网址访问实际上也是ip+port的访问形式。
我们可以通过网络上的主机名查询ip网站或工具来查看主机名对应的ip地址,这里我用xshell来查看对应的ip
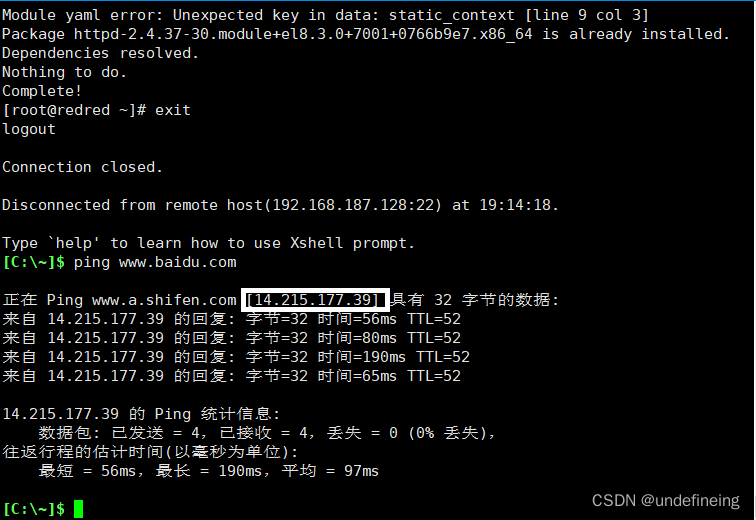 14.215.177.39就是百度对应的ip地址,可以用它访问百度
14.215.177.39就是百度对应的ip地址,可以用它访问百度
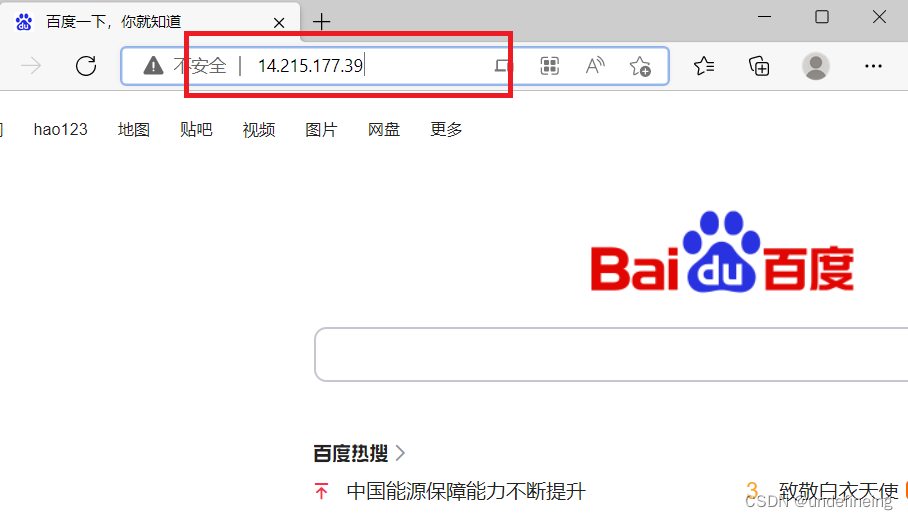
这里访问百度访问的是80端口,浏览器默认访问对方的web服务,web服务的默认端口为80.
而还有一种常用的服务https (web加密服务)的端口号为443,许多应用程序喜欢使用此端口
每一个ip可以有不同的端口,1-65535个序号,其中又是 udp和 tcp两种端口,通过ip可以找到主机,通过端口可以找到主机中对应的服务
2.web服务工作流程
在浏览器搜索栏我们输入了一个网址(主机名),为了找到对应的ip,我们会用到一个服务
dns :domain name server 的缩写
它提供主机名到ip地址的翻译服务,叫dns正向解析服务,也提供ip地址到主机名的翻译服务,叫dns反向解析服务。
在浏览器输入一个网址时
1、浏览器需要查询dns缓存,确定该主机名是否已经翻译成ip地址
2、如果有缓存ip地址,那么直接使用,如果没有,则发送dns查询去dns服务器,进行查询ip地址
(在网卡属性的详细信息里面可以看到dns服务器)
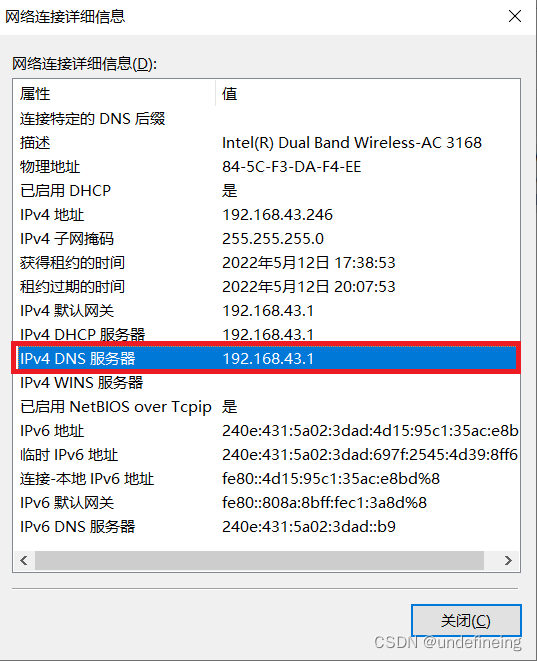
如上图所示我的电脑的dns服务器就是192.168.43.1 ,它向我电脑提供主机名到ip地址的解析服务。
3、使用查找到的ip地址进行访问,会话层的端口收到报文,解封装,应用层报文发给指定的应用程序
4、应用层会话
当然这只是最简单web流程,期间tcp 3次握手 4次 断开 交换 路由 arp识别 rarp stp ospf 帧封装灯都没提。
3.web服务
c/s 架构: clinet/server 的缩写,通过浏览器或其它设备 与 服务器 生成响应的过程
b/s 架构: broswer/server的缩写,特指通过浏览器与服务器生成响应的过程
3.1.服务端
linux web工具
两种软件:
1.apache 写的.httpd
2. 俄罗斯Nginx 公司写的 nginx
3种应用程序服务器:
Tomcat 、WebSphere、 IIS
Tocat使用较另外两种更多
3.2.客户端
edge Chrome sofari IE 火狐 这些都是
4.httpd实现web服务器
既然学httpd就不得不提一下它的创立者Apache
www.apache.org 可以访问阿帕奇组织官网
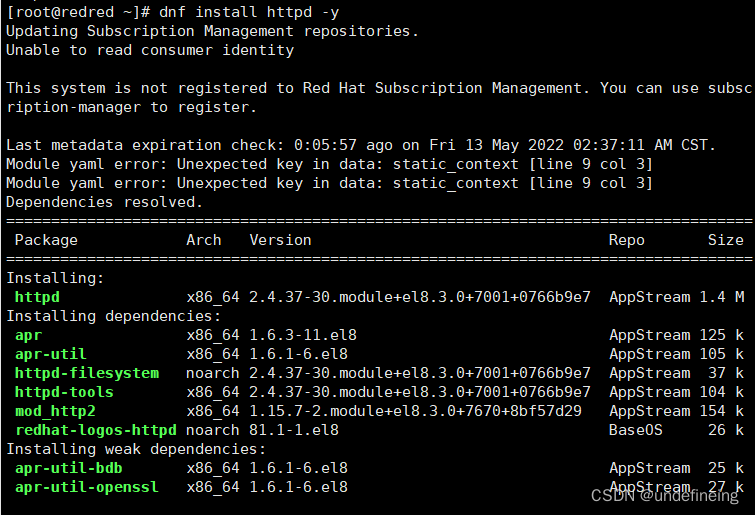
4.1.安装httpd服务
dnf install httpd -y
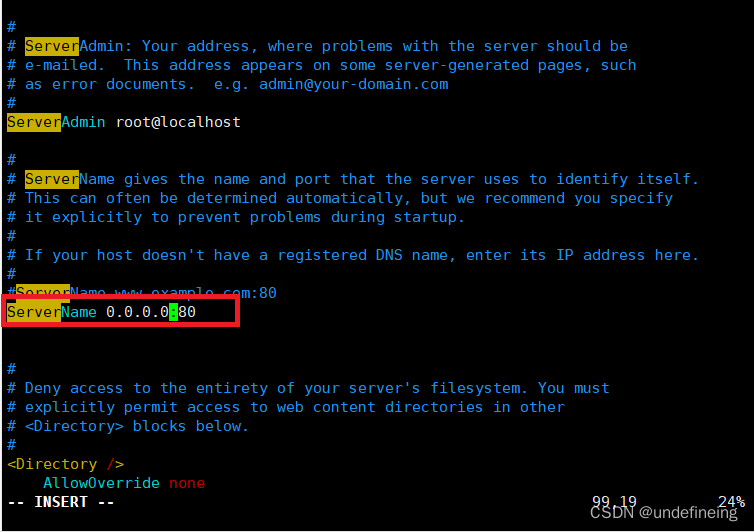
4.3.修改配置文件
用vim编辑/etc/httpd/conf/httpd.conf,将ServerName设定为0.0.0.0:80
4.3.重启httpd服务
systemctl restart httpd
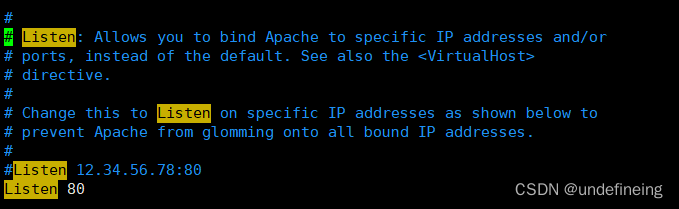
netstat -lntup | grep httpd

上图可见监听端口号为80,同样可以修改/etc/httpd/conf配置文件中Listen 来修改监听端口
4.4.在防火墙中放行http服务
firewall-cmd --permanent --add-service=http
firewall-cmd --reload 重载

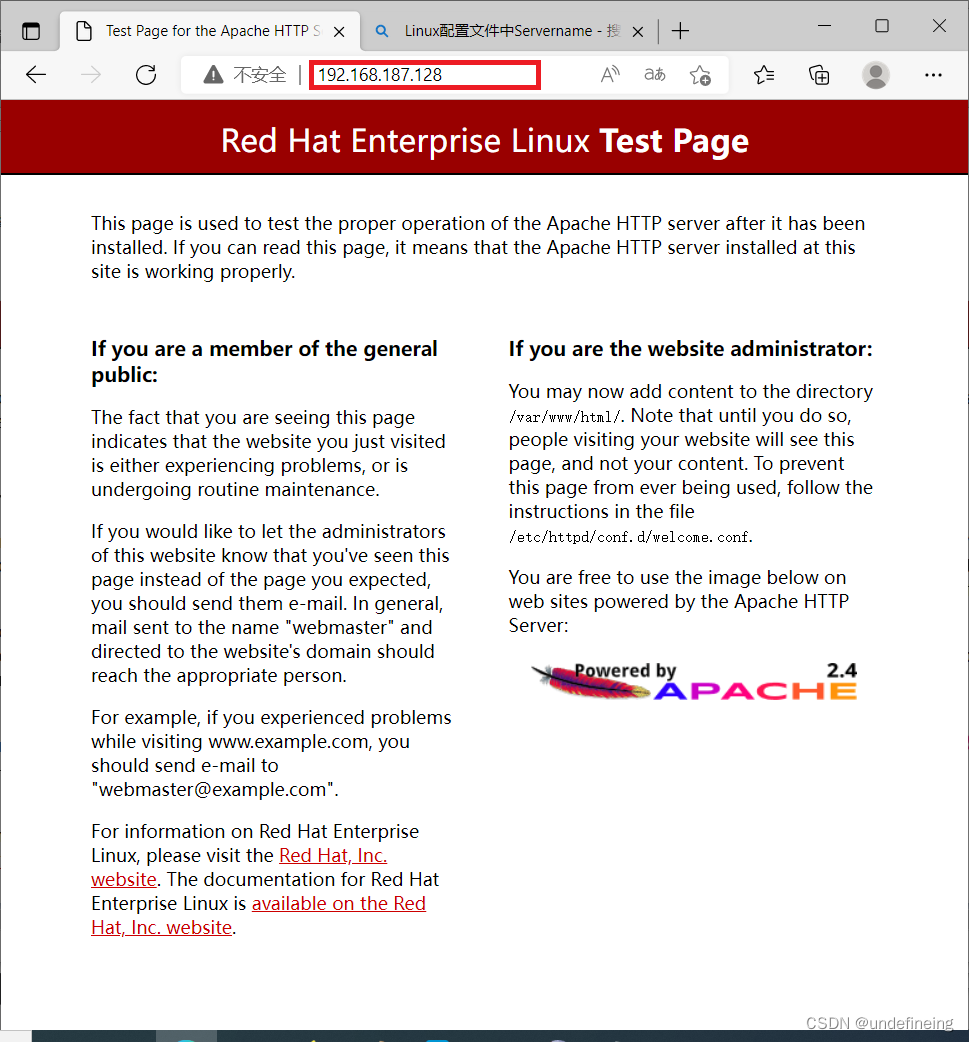
到此我们已经可以在网络中访问自己了,在浏览器中使用ip 地址进入web服务界面
4.5.自定义web页面
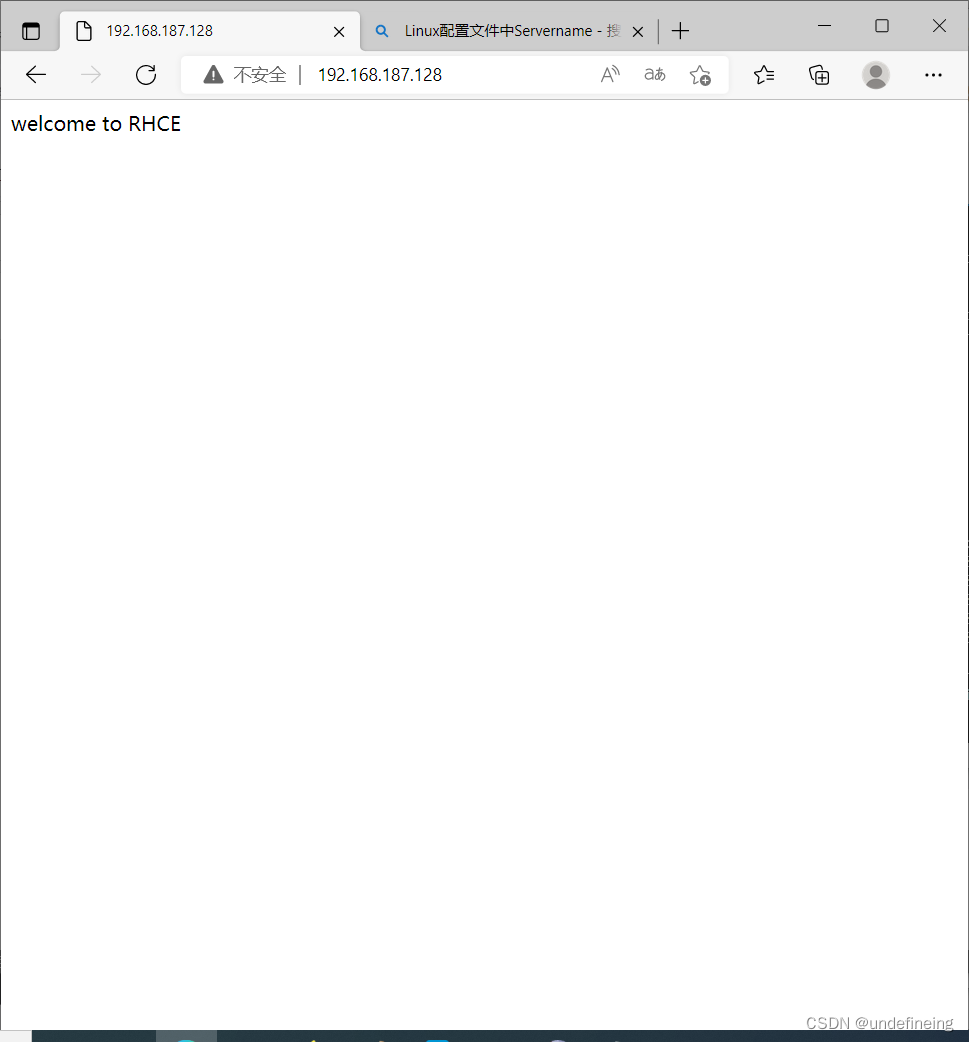
web界面保存在/var/www/html/中
编辑其下的index.html实现编辑web页面
例如
cd /var/www/html/
echo welcome to rhce > index.html

















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









