



目录
一、虚拟机基础搭建
此处跳过基础虚拟机安装流程,可自行查阅,参考:linux-Centos-7-64位:0、 虚拟机环境搭建
搭建三台虚拟机,IP如下
192.168.152.151 hadoop-master
192.168.152.152 hadoop-slave1
192.168.152.153 hadoop-slave2
并将其配置到hosts文件,包装三台能互相PING通
二、hadoop服务
| 192.168.152.151 | 192.168.152.152 | 192.168.152.153 | |
| HDFS | DataNode NameNode | DataNode | DataNode SecondaryNameNode |
| YARN | NodeManager | NodeManager ResourceManager | NodeManager |
1、服务器配置ssh免密码登录
在root用户下输入
# ssh-keygen -t rsa
一路回车
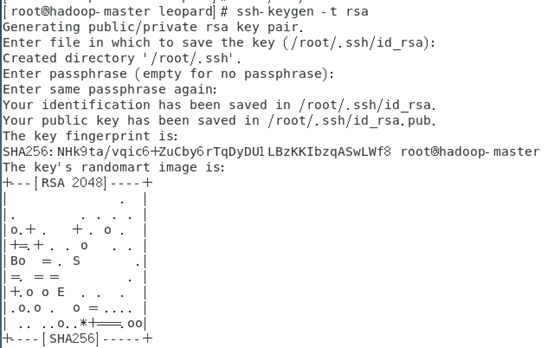
秘钥生成后在~/.ssh/目录下,有两个文件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# chmod 600 ~/.ssh/authorized_keys
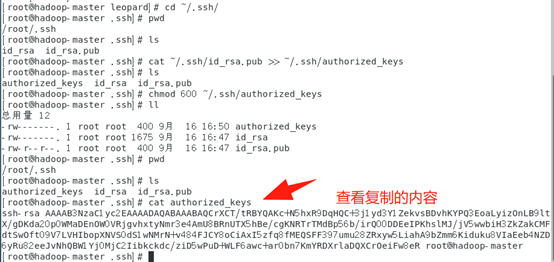 同理在slave1和slave2节点上进行相同的操作,然后将公钥复制到master节点上的authoized_keys
同理在slave1和slave2节点上进行相同的操作,然后将公钥复制到master节点上的authoized_keys

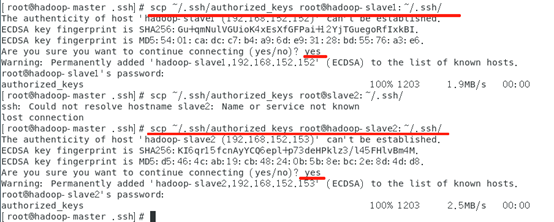
将master节点上的authoized_keys远程传输到slave1和slave2的~/.ssh/目录下
# scp ~/.ssh/authorized_keys root@hadoop-slave1:~/.ssh/
# scp ~/.ssh/authorized_keys root@hadoop-slave2:~/.ssh/
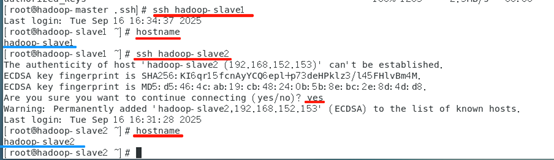
检查是否免密登录(第一次登录会有提示)
2、检查并关闭防火墙
详细可参考:linux-Centos-7-64位:3、 firewalld 配置
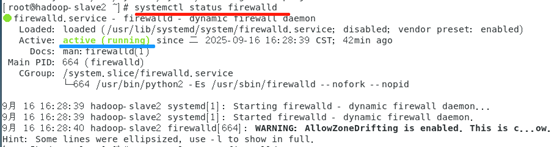
查看状态
# systemctl status firewalld
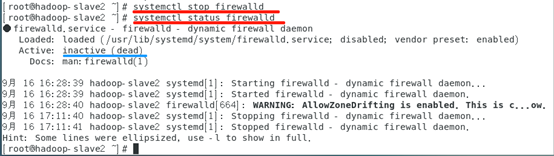
停止:
# systemctl stop firewalld
禁止防火墙开机启动:
# systemctl disable firewalld.service

3、安装JDK
可参考:linux-Centos-7-64位:1、 安装JAVA环境
4、安装MYSQL(不使用Hive元数据做存储,可不安装)
可参考:linux-Centos-7-64位:4、 mysql安装
5、下载安装hadoop
官网地址:https://dlcdn.apache.org/hadoop/common/
此处下载 hadoop-3.4.1.tar.gz
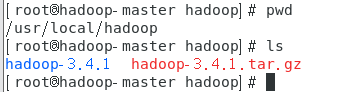
创建目录 hadoop,上传压缩包并解压
# mkdir /usr/local/hadoop
# cd /usr/local/hadoop
# tar -zxvf hadoop-3.4.1.tar.gz
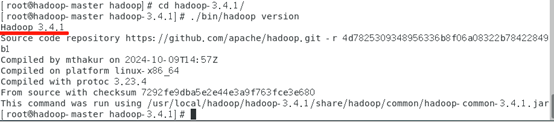
进入目录查看版本
# cd hadoop-3.4.1/
# ./bin/hadoop version
配置环境变量,新建脚本(也可以直接写在 /etc/profile 内 ,跟JAVA_HOME放一起)
# vim /etc/profile.d/hadoop.sh
#写入如下配置
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.4.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin#使配置生效
# source /etc/profile
#查看是否生效,有输出版本就生效了
# hadoop version
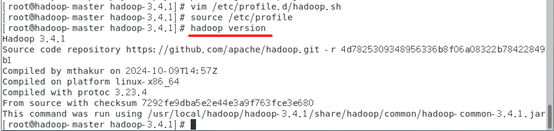
建立目录,在 /usr/local/hadoop/hadoop-3.4.目录下,建立 tmp、hdfs/name、hdfs/data 目录
# mkdir /usr/local/hadoop/hadoop-3.4.1/tmp
# mkdir /usr/local/hadoop/hadoop-3.4.1/dfs
# mkdir /usr/local/hadoop/hadoop-3.4.1/dfs/data
# mkdir /usr/local/hadoop/hadoop-3.4.1/dfs/name
进入hadoop配置目录
# cd /usr/local/hadoop/hadoop-3.4.1/etc/hadoop
修改以下文件的配置
slaves 把所有从节点的主机名写到这儿就可以,这是告诉hadoop进程哪些机器是从节点。每行写一个,如下:
hadoop-slave1
hadoop-slave2注:前提是你已经为每个节点进行了hostname的命名。而且每个节点的hosts文件你修改了本地dns的指向,让这些主机指向约定好的IP。然后每个节点的hosts文件保持同步。
workers 是指定HDFS上有哪些DataNode节点
hadoop-master
hadoop-slave1
hadoop-slave2hadoop-env.sh 启动参数和环境变量配置
# java_home若已配过,这里可以直接引用,否则应配置完整jdk路径
export JAVA_HOME=/usr/local/java/jdk-1.8
# 安装用的是root用户,所以这里都设置为root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/usr/local/hadoop/pids
export HADOOP_LOG_DIR=/usr/local/hadoop/logscore-site.xml 核心配置,主要用于设置与 HDFS 和 Hadoop 集群的其他服务进行交互的参数。
<configuration>
<!-- Hadoop核心配置 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:8020</value>
<description>指定 HDFS 的文件系统 URI。用于客户端访问 HDFS,所有的路径前缀都以此为基准。</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-3.4.1/tmp</value>
<description>Hadoop 临时目录,用于存储临时数据、日志等。</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>设置 HDFS 文件 I/O 缓冲区的大小(字节)。默认值是 131072 字节(128KB)。(使用默认可不配置)</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>可以使用通配符值“*”来实现从任何主机进行身份冒充的功能,名为“root”的用户从任何主机访问时都可以冒充属于任何IP的地址。</description>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
<description>可以使用通配符值“*”来实现从任何用户进行身份冒充的功能名为“root”的用户从任何主机访问时都可以冒充属于任何用户。</description>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>*</value>
<description>可以使用通配符值“*”来实现从任何组进行身份冒充的功能名为“root”的组从任何主机访问时都可以冒充属于任何组的组。</description>
</property>
</configuration>hdfs-site.xml 包含 HDFS(Hadoop Distributed FileSystem)的配置项,涉及文件系统的行为、数据存储、复制等参数。
<configuration>
<!-- HDFS 配置 -->
<property>
<name>dfs.replication</name>
<value>3</value>
<description>指定 HDFS 文件的默认副本数。默认值是 3。(使用默认可不配置)</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop-3.4.1/dfs/name</value>
<description>HDFS NameNode 的数据存储路径。必须是本地文件路径。</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop-3.4.1/dfs/data</value>
<description>HDFS DataNode 的数据存储路径。也必须是本地文件路径。</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>设置 HDFS 文件块大小,默认 128MB。调整此值有助于控制文件块大小。(使用默认可不配置)</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-master:9870</value>
<description>配置NameNode web 的 HTTP 访问地址。</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-slave2:9868</value>
<description>配置 NameNode Secondary 的 HTTP 访问地址,允许管理员访问 NameNode 状态。</description>
</property>
</configuration>yarn-site.xml 包含 YARN(Yet Another Resource Negotiator)配置,主要用于集群资源管理、调度、应用程序提交等相关设置。
<configuration>
<!-- YARN 配置 -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master:8030</value>
<description>yarn总管理器调度程序的IPC通讯地址。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address </name>
<value>hadoop-master:8031</value>
<description>yarn总管理器的IPC通讯地址。</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master:8032</value>
<description>RM 中应用程序管理器接口的地址,客户端通过此地址提交作业。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-master:8033</value>
<description>RM 管理界面地址</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-master:8088</value>
<description>yarn总管理器的web http通讯地址</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
<description>设置 YARN 使用的调度器类型,常见的有 CapacityScheduler、FairScheduler。</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
<description>每个 NodeManager 上可用的最大内存(单位:MB)。如果超出限制,YARN 不会调度新任务。</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop/hadoop-3.4.1/tmp/nm-local-dir</value>
<description>YARN NodeManager 本地存储目录,用于存储临时数据。</description>
</property>
</configuration>mapred-site.xml 用于配置 MapReduce 相关的设置,尤其是 MapReduce 任务的执行、调度和资源管理。
<configuration>
<!-- MapReduce 配置 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定 MapReduce 运行框架为 YARN。可以选择 "local"(本地模式)、"yarn"(集群模式)等。</description>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>为 Map 任务分配的内存大小,单位为 MB。(使用默认值可不配)</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
<description>为 Reduce 任务分配的内存大小,单位为 MB。(使用默认值可不配)</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:10020</value>
<description>MapReduce历史记录服务器IPC地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:19888</value>
<description>MapReduce历史记录服务器WEB-UI地址</description>
</property>
</configuration>capacity-scheduler.xml 用于配置 YARN 的容量调度器,尤其是在多租户(多集群)环境下,调整集群资源分配策略
(此配置一般有默认配置好的,不需要修改可以跳过)
<configuration>
<!-- YARN 容量调度器配置 -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>50</value>
<description>设置默认队列的资源容量百分比。</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>80</value>
<description>设置默认队列的最大资源容量百分比。</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>设置默认队列的状态。可以是 RUNNING、STOPPED 等。</description>
</property>
</configuration>将配置好的hadoop文件复制到其他节点上
# scp -r /usr/local/hadoop/ root@hadoop-slave1:/usr/local/
# scp -r /usr/local/hadoop/ root@hadoop-slave2:/usr/local/
如果集群第一次启动,需要在NameNode(192.168.152.151)机器上格式化NameNode,进入bin目录,执行格式化命令
# ./hdfs namenode -format
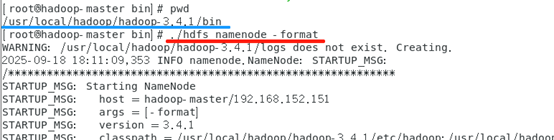
初始化成功如下:
进入sbin目录,执行启动
# ./start-all.sh
启动报错:ERROR: namenode can only be executed by root

说明hadoop被安装给root用户了, 需要使用 root 运行
# su –
再次执行,成功

访问页面: http://192.168.152.151:9870/
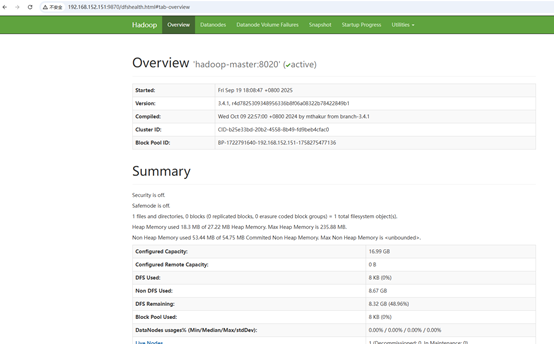
访问页面: http://192.168.152.151:8088/
参考文章:
hadoop集群搭建(超详细版)https://blog.youkuaiyun.com/m0_67391683/article/details/123935937

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









