




 本文是Java爬虫大型教程的第三部分,主要讲解如何使用Pipeline保存爬取结果,深入探讨Jsoup的选择器语法以及XSoup的XPath解析,包括配置Spider、启动和终止爬虫,以及Jsoup的DOM遍历和数据提取。
本文是Java爬虫大型教程的第三部分,主要讲解如何使用Pipeline保存爬取结果,深入探讨Jsoup的选择器语法以及XSoup的XPath解析,包括配置Spider、启动和终止爬虫,以及Jsoup的DOM遍历和数据提取。
java 爬虫大型教程(三)
基本爬虫进阶(一)
1. 使用Pipeline保存结果
好了,爬虫编写完成,现在我们可能还有一个问题:我如果想把抓取的结果保存下来,要怎么做呢?WebMagic用于保存结果的组件叫做Pipeline。例如我们通过“控制台输出结果”这件事也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。那么,我现在想要把结果用Json的格式保存下来,怎么做呢?我只需要将Pipeline的实现换成"JsonFilePipeline"就可以了。
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new CdnRepoPageProcessor())
//从https://www.cnblogs.com开始抓
.addUrl("https://www.cnblogs.com/")
//指定数据存储路径
.addPipeline(new JsonFilePipeline("/Users/duke/IdeaProjects/javaspider/data"))
//开启5个线程抓取
.thread(5)
//运行爬虫
.run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
}
这样下载下来的数据就会保存在指定的目录中了。通过定制Pipeline,我们还可以实现保存结果到文件、数据库等一系列功能,在后续教程中会讲到。
JsonFilePipeline:
将结果用Json的格式保存下来,每个URL保存一个json文件。
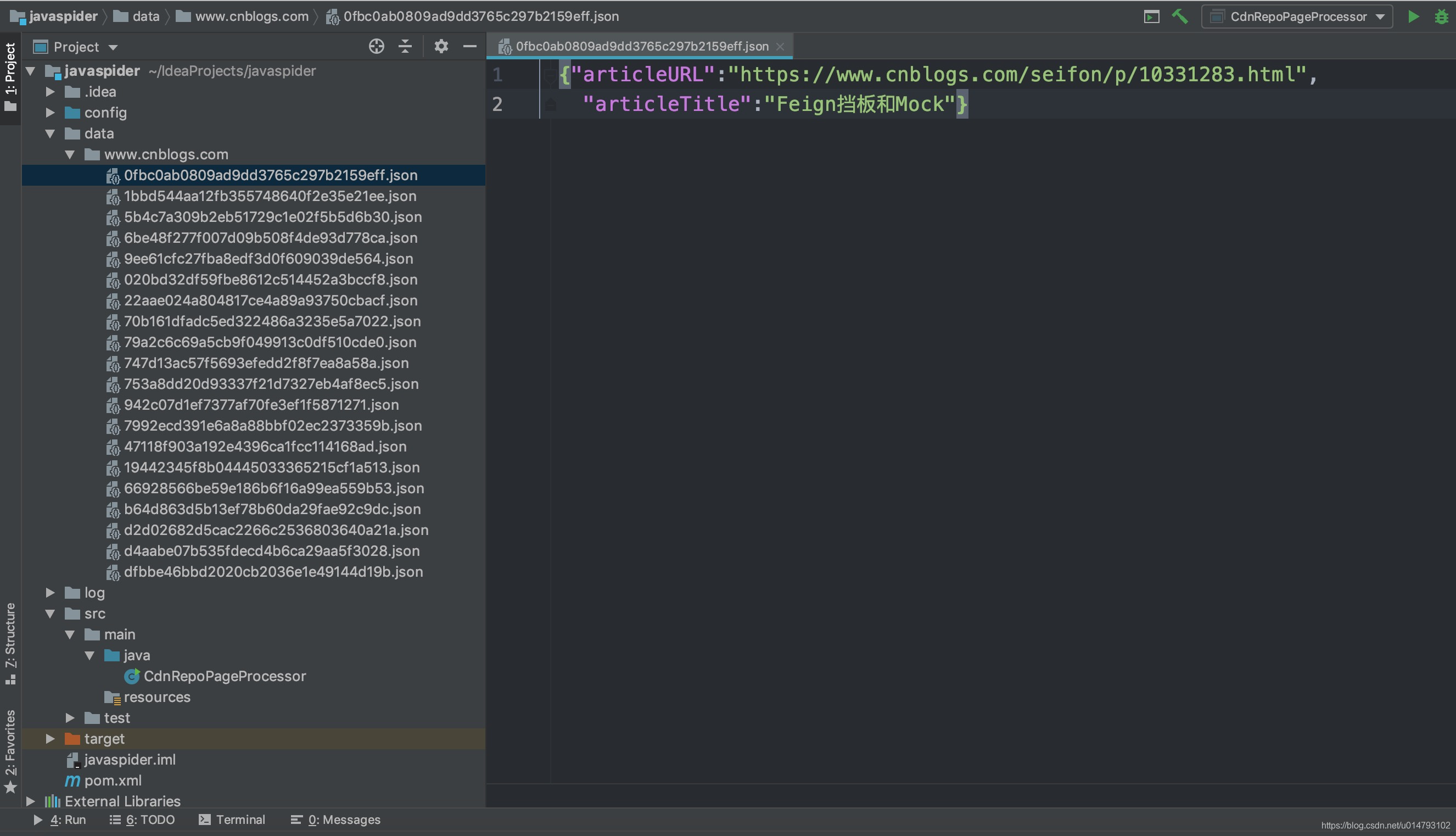
json文件中的键就是代码中的page.putField指定:
page.putField("articleURL",page.getUrl().toString());
page.putField("articleTitle",< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









