




原文:RocketMQ源码详解 | Broker篇 · 其三:CommitLog、索引、消费队列 - en_oc - 博客园
写一篇笔记吧,为了更好的理解消费者。
三个文件: CommitLog、IndexFile、ConsumerQueue
1、CommitLog(消息内容存储)
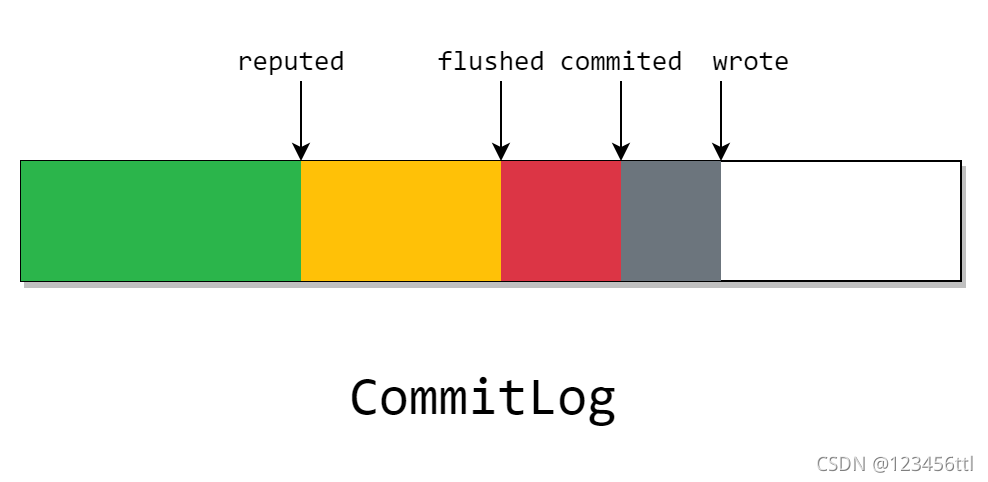
※ 这张图从左往右看
CommitLog 在开启 transientStorePool时,会有一块 writeBuffer,这块ByteBuffer是分配的一块堆外内存,也就是图上的灰色部分。我们在上图中看见的 wrote 指针,指向了当前已写入writeBuffer 但是没有 commit 的位置。
※ 大部分的写方式都是多个指针推进字节流的前进
这块灰色部分只存在 Java 进程中,也就是说程序崩了则会丢失。且如果关闭transientStorePool选择,该指针将不会存在。
然后当我们定期将 writeBuffer 刷入FileChannel后,就变成了图中的红色块。其中的 commited 指针代表在这之前的消息都刷入了 page cache。这部分的消息由于存放在 page cache 中,且 page cache 是操作系统内核中的一块内存,所以程序崩了不会丢失,但在宕机后依旧会丢失。
※ commited是向缓存中刷新,从而向磁盘映射,commited指针追赶wrote指针
不过 CommitLog 会根据具体的刷盘策略来异步或同步的进行刷盘,也就是说,在 flushed 指针之前的数据,已经完全的磁盘里了。且这块数据除非介质被破坏,否则一般不会丢失。
而在等待所有的CommitLogDispatcher处理完成后,reputed 指针就会前进。而这个 dispatcher 做的事,就是我们之前在消息提交时没有发现的两件事:构建 IndexFile 和 ConsumerQueue。
※ 需要注意的是,图中虽然画为 reputed 指针在 flushed 指针后面。但实际上 reputed 指针最快可以和 wrote 指针同步
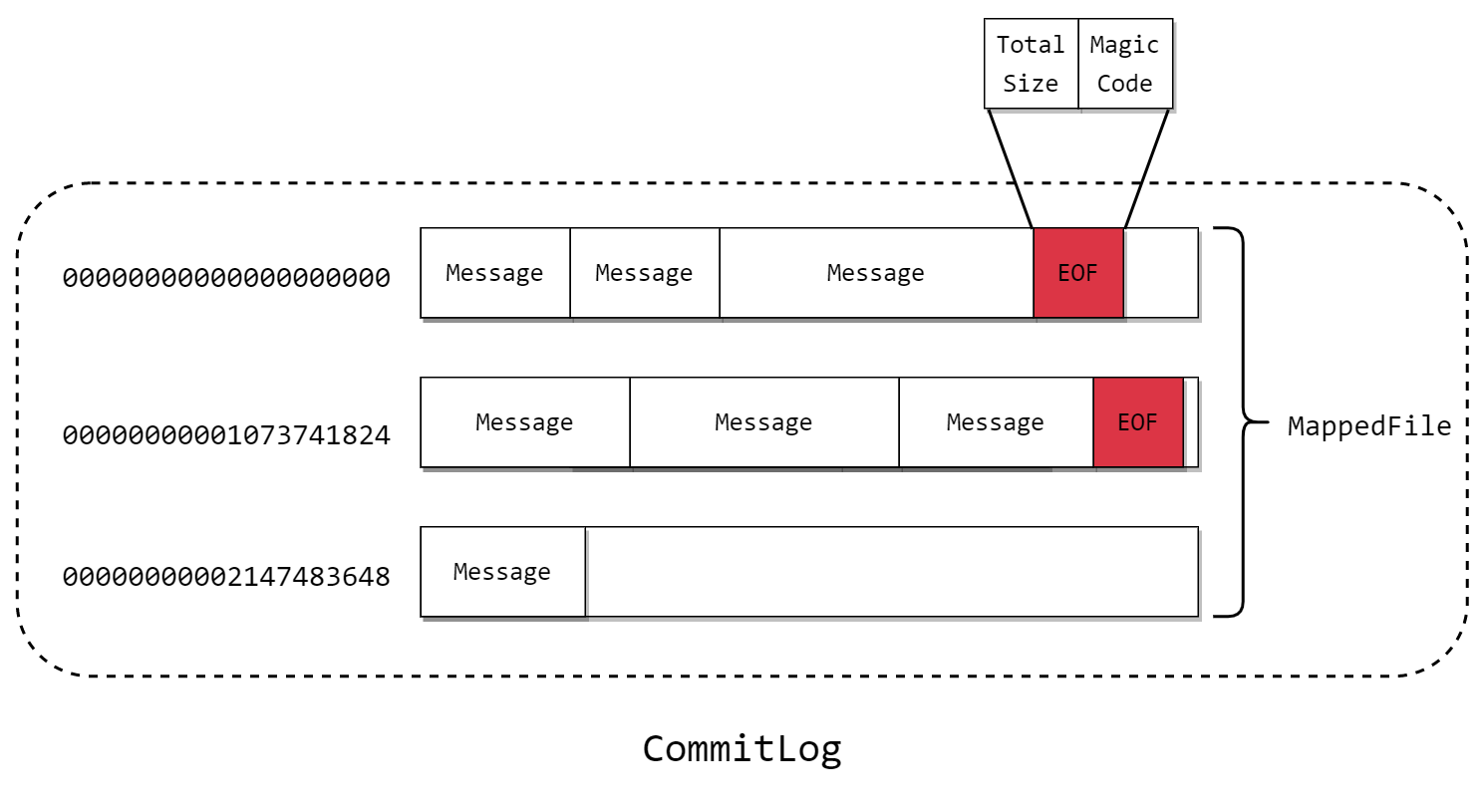
最后,commitlog的存储方式如上图,文件以offset命名,默认1G大小一个,在文件尾部追加Total Size总大小和Magic Code
2、IndexFile(消息内容存储)

ConsumerQueue 的文件结构较为简单,其由 30W 个的上图中的结构体组成。
查找一个CosumerQueue的过程:
(1)根据时间戳定位物理文件,就是从第一个文件开始找到第一个文件更新时间大于该时间戳的文件
(2)采用二分查找来加速检索(while中的部分)
public long getOffsetInQueueByTime(final long timestamp) {
// 通过时间戳获取刚好在这之前的 MappedFile
MappedFile mappedFile = this.mappedFileQueue.getMappedFileByTime(timestamp);
if (mappedFile != null) {
long offset = 0;
// 低位为 消息队列最小偏移量 与 该文件最小偏移量 中的最小值
int low = minLogicOffset > mappedFile.getFileFromOffset() ? (int) (minLogicOffset - mappedFile.getFileFromOffset()) : 0;
int high = 0;
int midOffset = -1, targetOffset = -1, leftOffset = -1, rightOffset = -1;
long leftIndexValue = -1L, rightIndexValue = -1L;
long minPhysicOffset = this.defaultMessageStore.getMinPhyOffset();
SelectMappedBufferResult sbr = mappedFile.selectMappedBuffer(0);
if (null != sbr) {
ByteBuffer byteBuffer = sbr.getByteBuffer();
high = byteBuffer.limit() - CQ_STORE_UNIT_SIZE;
try {
while (high >= low) {
// ? 奇怪的写法,先除以 CQ_STORE_UNIT_SIZE 再乘以 CQ_STORE_UNIT_SIZE
midOffset = (low + high) / (2 * CQ_STORE_UNIT_SIZE) * CQ_STORE_UNIT_SIZE;
byteBuffer.position(midOffset);
// 获取找到桶在 CommitLog 中的偏移量
long phyOffset = byteBuffer.getLong();
// 获取该消息大小
int size = byteBuffer.getInt();
if (phyOffset < minPhysicOffset) {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
continue;
}
long storeTime =
this.defaultMessageStore.getCommitLog().pickupStoreTimestamp(phyOffset, size);
// 根据持久化时间进行二分查找
if (storeTime < 0) {
return 0;
} else if (storeTime == timestamp) {
targetOffset = midOffset;
break;
} else if (storeTime > timestamp) {
high = midOffset - CQ_STORE_UNIT_SIZE;
rightOffset = midOffset;
rightIndexValue = storeTime;
} else {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
leftIndexValue = storeTime;
}
}
if (targetOffset != -1) {
offset = targetOffset;
} else {
if (leftIndexValue == -1) {
offset = rightOffset;
} else if (rightIndexValue == -1) {
offset = leftOffset;
} else {
offset =
Math.abs(timestamp - leftIndexValue) >
Math.abs(timestamp - rightIndexValue) ? rightOffset : leftOffset;
}
}
return (mappedFile.getFileFromOffset() + offset) / CQ_STORE_UNIT_SIZE;
} finally {
sbr.release();
}
}
}
return 0;
}但是我们发现,消息需要消费的时候,只靠 ComsumerQueue 是不够的,因为在这个结构中并没有记录每一个消费者组的消费进度。
这是因为 Broker 端是将消费进度维护在内存的一个 Map 中,同时会定时的将该 Map 转为 json 格式持久化到磁盘。
3、IndexFile
※ ConsumerQueue提供了一种通过offset查找Commitlog的方式,但是如果要根据MessageId或者时间范围来从CommitLog中查找消息,就无能为力。由此引出IndexFile
RocketMQ 通过建立 IndexFile 以提供一种能够通过 时间范围 或 Key 值 来查询 Message 的方法。
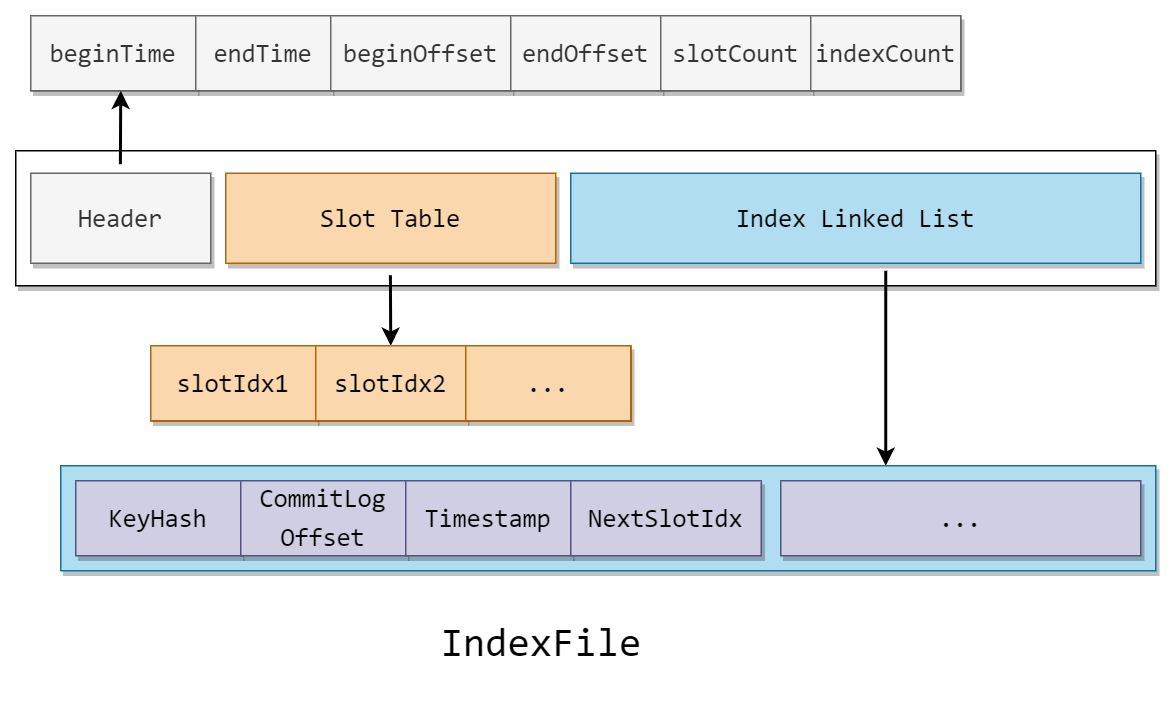
IndexFile 可以分为三部分
(1)Header
头部记录了记录消息的开始(最小)时间,结束(最大)时间,开始(最小)偏移量,结束(最大)偏移量,和槽的个数与节点个数
(2)Slot Table
table 的槽记录了指向当前槽中尾节点的指针
(3)Index Linked List
记录了所有节点的索引信息
由结构可以看出,IndexFile 是标准的 hash 索引,如果了解过 hash 索引的话,根据上文马上就能猜到到 IndexFile 的运行机制了。

















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









