






 本文通过一个实际案例,展示了如何使用MySQL的binlog来排查数据同步问题。具体介绍了binlog的导出与解析方法,并深入分析了开源项目otter在处理唯一索引更新时存在的问题。
本文通过一个实际案例,展示了如何使用MySQL的binlog来排查数据同步问题。具体介绍了binlog的导出与解析方法,并深入分析了开源项目otter在处理唯一索引更新时存在的问题。
MySQL的binlog相信大家都有所耳闻,但是可能没有真正日常使用过。
因此,本文结合一个otter小坑的排查案例,来分享下binlog的日常使用方式。
重点了解下:
- binlog的导出方式
- binlog的解析方式
- 结合案例分享下开源项目otter的一个小坑
1.案例背景
某个周末突然收到报警,发现线上多云数据库的数据同步任务挂起,显示日志写入数据失败。

错误原因非常明显:
唯一索引冲突。
查看了一下源库的数据内容,确实已经update完毕。而目标库的数据内容,确实存在冲突导致无法update。
2.排查过程
这个数据同步任务,使用了阿里开源的数据库同步项目otter。难道遇到了什么bug?
otter项目是阿里巴巴开源的数据库同步系统。
基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库的一个分布式数据库同步系统。
直接开始排查问题。
2.1 表结构是否一致
为什么源库没有冲突,目标库会有冲突呢?是不是表结构不一致?或者是源库发生了表结构变更没有同步到目标库?
确认了下源库的表结构和目标库表结构是一致的,且都有对应的唯一索引udx_position。
2.2 排查源库binlog
那源库到底是怎么更新成功的?只能捞一下binlog了。
首先导出线上正在使用的binlog文件。
在数据库上执行
flush logs
这个命令会关闭当前正在写入的binlog文件,然后生成一个序号加1的新的binlog文件让mysql server继续使用。
等待几分钟,让当前的binlog落盘为日志文件,本案例中为xxxx_binlog_mysqlbin.000005。
然后下载到本地。
通过mysqlbinlog命令解析,输出为指定文件xxx.binlog,如下:
mysqlbinlog --start-datetime='2020-11-20 18:17:00' --stop-datetime='2020-11-20 18:21:01' --base64-output=decode-rows -v -d db xxxx_binlog_mysqlbin.000005 > xxx.binlog
- binlog格式binlog_format采用row模式。仅保存记录被修改细节,不记录sql语句上下文相关信息优点:能非常清晰的记录下每行数据的修改细节,不需要记录上下文相关信息,因此不会发生某些特定情况下的procedure、function、及trigger的调用触发无法被正确复制的问题,任何情况都可以被复制,且能加快从库重放日志的效率,保证从库数据的一致性。
- 通过 --start-datatime和–stop-datetime指定解析的起止时间
- row模式生成的sql编码需要解码,不能用常规的办法去生成,需要加上相应的参数(–base64-output=decode-rows -v)才能显示出sql语句
binlog的内容解析后sql的过程如下(为了更好地看清过程,这里不展示binlog原文,而是一个逻辑过程):

我们能清楚地看到,源库通过一个事务中,交换position(唯一索引的列)的值,达到更新唯一索引而不造成冲突的目的。
那目标库为什么会冲突呢?
2.3 查看目标库的sql审计
由于数据同步失败挂起,所以目标库的同步数据暂时不会写入对应的binlog记录。
因此,我们需要通过sql审计来查看目标库的写入情况。
这里同样展示sql审计中捞出的相关过程:

Oh~ My~ God!
事务中间的update交换过程居然被合并了!!
所以造成了唯一索引冲突,更新失败。
3.求证
重新去翻了一遍otter的wiki,看到了关于《otter数据入库算法》说明。
https://github.com/alibaba/otter/wiki/Otter%E6%95%B0%E6%8D%AE%E5%85%A5%E5%BA%93%E7%AE%97%E6%B3%95
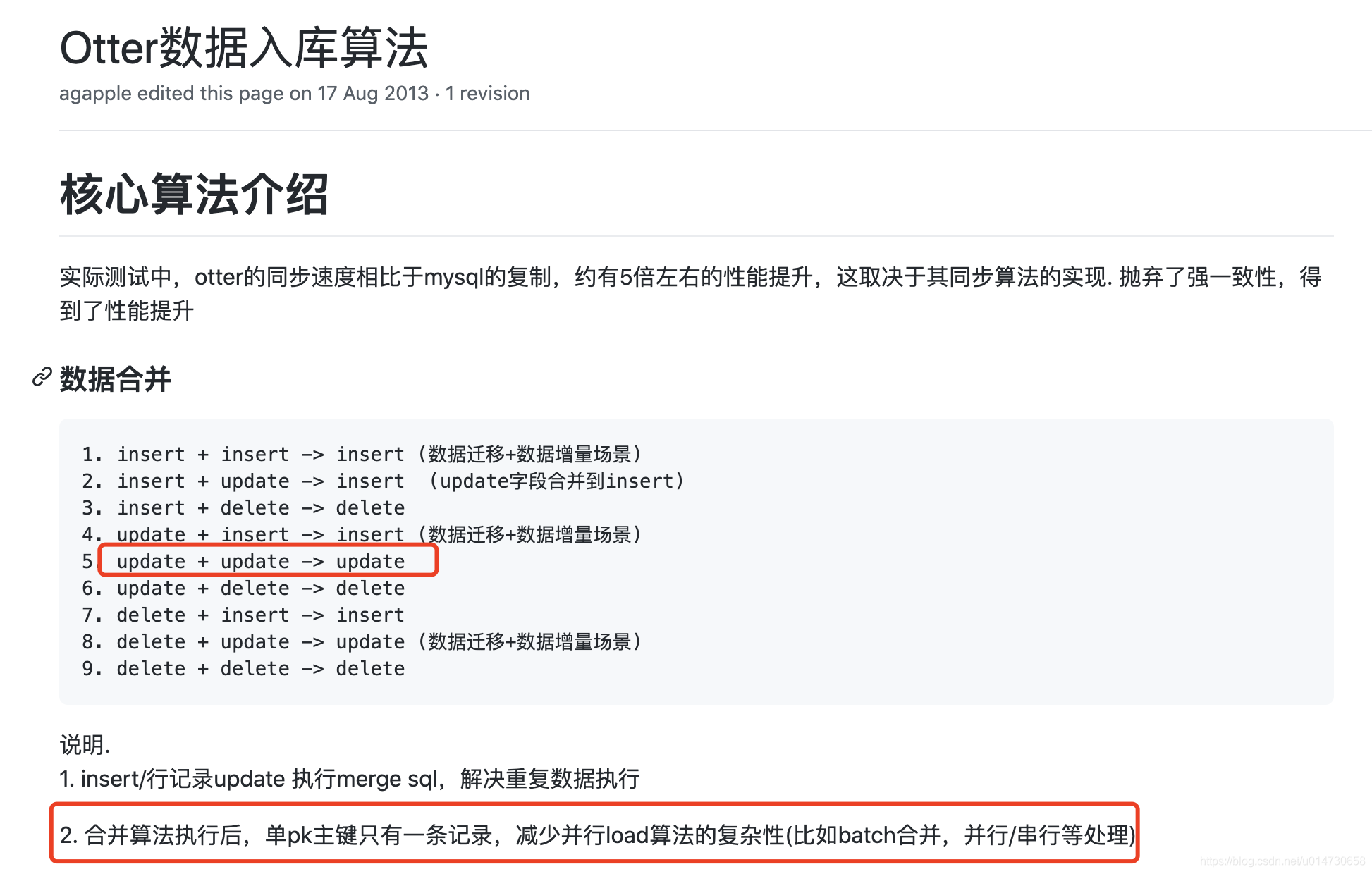
确实存在操作合并的情况。
这样做许多好处:
- insert/行记录update 执行merge sql,解决重复数据执行
- 合并算法执行后,单pk主键只有一条记录,减少并行load算法的复杂性(比如batch合并,并行/串行等处理)
- 同步速度相比于mysql的复制,抛弃了强一致性,约有5倍左右的性能提升
找了下源码,定位到DbLoadAction类
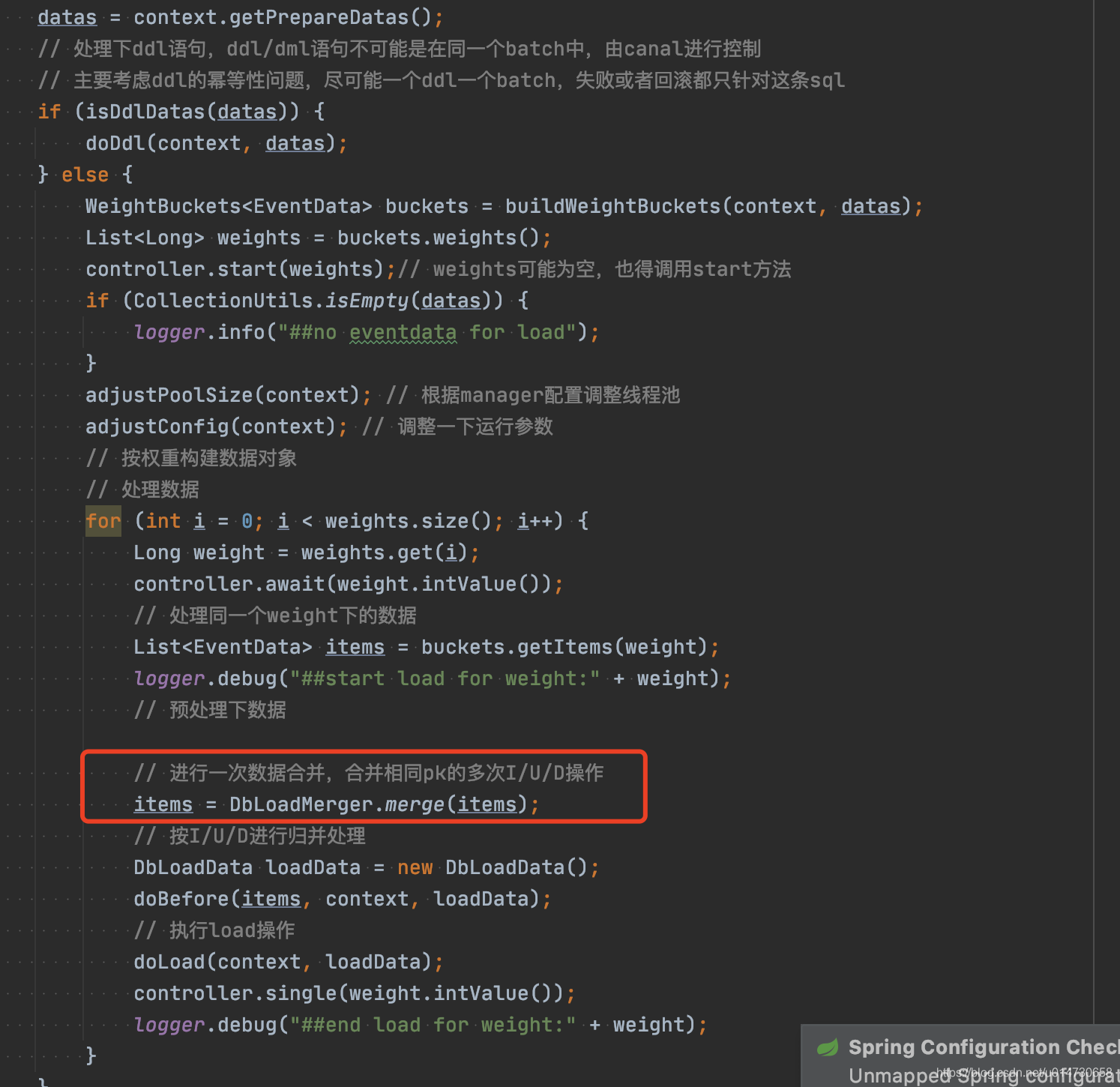
令人遗憾的是,我们发现竟然没有开关可以控制。
4.解决方案。
到上面基本已经水落石出,找到了问题的根本原因。由于otter对事务内的update操作进行了合并,导致了目标库唯一索引冲突。
那怎么解决呢?
看到文档上有这么一句话
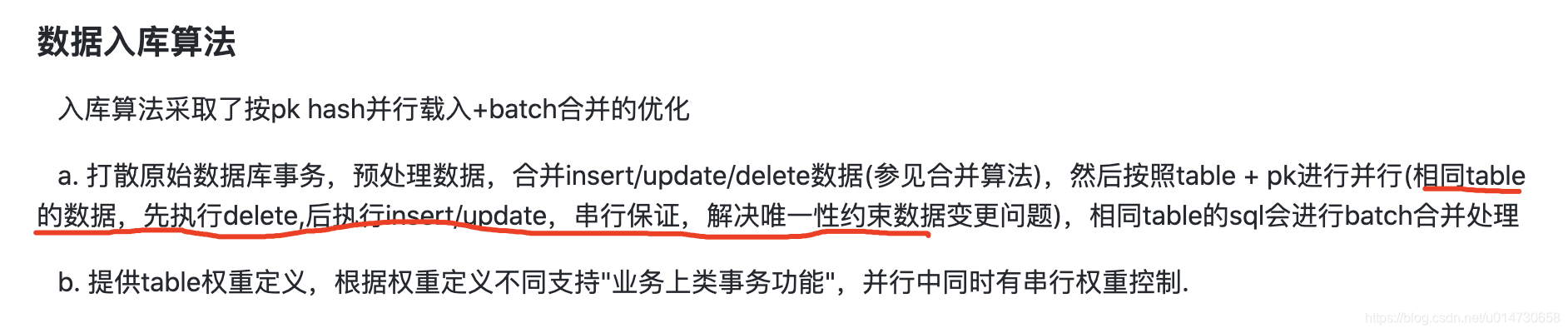
那么,对应到这个案例,或者说其他唯一索引的变更,只能通过 先删除,再插入,而不是通过update进行交换。
所以,如何使用binlog来排查问题,你学废了吗? :)
看到这里了,原创不易,来个三连吧!!!你最好看了~
知识碎片重新梳理,构建Java知识图谱:https://github.com/saigu/JavaKnowledgeGraph (历史文章查阅非常方便)

















 7366
7366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









