 Transformer模型详解:从GPT到BERT的演进与核心技术
Transformer模型详解:从GPT到BERT的演进与核心技术





 Transformer架构由谷歌提出,通过自注意力机制和多头注意力层处理序列数据。模型包括Encoder和Decoder,其中Encoder使用自注意力计算编码信息,Decoder结合编码信息预测序列。关键词如GPT、BERT、词嵌入和位置编码在模型中起关键作用,预训练模型的大小和数据量对性能有很大影响。
Transformer架构由谷歌提出,通过自注意力机制和多头注意力层处理序列数据。模型包括Encoder和Decoder,其中Encoder使用自注意力计算编码信息,Decoder结合编码信息预测序列。关键词如GPT、BERT、词嵌入和位置编码在模型中起关键作用,预训练模型的大小和数据量对性能有很大影响。
文章目录
1. 简介
- 现在ChatGPT可以说是AI界的当红炸子鸡,甚至都不局限于AI界了,各行各业都受到了ChatGPT的追捧和冲击,而ChatGPT背后的算法就是transformer。想要更好的使用和了解ChatGPT,那么我们首先应该对它背后的底层方法进行学习和复现。到这里便引出了我们今天要学习的结构:transformer。
- 首先介绍一下transformer的发展史
1.1. 发展史
-
Transformer 架构 于 2017 年 6 月推出。原本研究的重点是翻译任务。随后推出了几个有影响力的模型,包括
-
2018 年 6 月: GPT, 第一个预训练的 Transformer 模型,用于各种 NLP 任务并获得极好的结果
-
2018 年 10 月: BERT, 另一个大型预训练模型,该模型旨在生成更好的句子摘要
-
2019 年 2 月: GPT-2, GPT 的改进(并且更大)版本,由于道德问题没有立即公开发布
-
2019 年 10 月: DistilBERT, BERT 的提炼版本,速度提高 60%,内存减轻 40%,但仍保留 BERT 97% 的性能
-
2019 年 10 月: BART 和 T5, 两个使用与原始 Transformer 模型相同架构的大型预训练模型(第一个这样做)
-
2020 年 5 月: GPT-3, GPT-2 的更大版本,无需微调即可在各种任务上表现良好(称为零样本学习)
-
2022年11月30日,GPT3.5发布,也就是我们所熟知的ChatGPT,可以称之为人工智能历史上的里程碑事件
-
2023年4月3月15日凌晨,ChatGPT 4发布,AI的再次进化,堪称史上能力最强,而且短期内不会被超越。
-
从上面的时间表我们可以看出,NlP模型的研究速度越来越快,我们也得加快自己的学习脚步了,如果现在不进行追赶,可能以后就追赶不上了。
-
其实这个列表并不全面,只是为了突出一些不同类型的 Transformer 模型。大体上,它们可以分为三类:
-
GPT-like (也被称作**自回归 **Transformer 模型)
-
BERT-like (也被称作自动编码 Transformer 模型)
-
BART/T5-like (也被称作序列到序列的 Transformer 模型)
-
Transformer 是大模型,除了一些特例(如 DistilBERT)外,实现更好性能的一般策略是增加模型的大小以及预训练的数据量。其中,GPT-2 是使用「transformer 解码器模块」构建的,而 BERT 则是通过「transformer 编码器」模块构建的。这是两种不同的思路,OpenAI选用的是前者GPT解码模型,而谷歌则把宝压在了后者BERT编码模型上面,从现在的ChatGPT大红大紫上面可以看出,谷歌虽然是大语言模型的提出者,但是却因为当初选择错了道路,所以之前的优势复制东流,
-
万事开头难,那么先从最简单的基本概念开始吧。
2. Transformer 整体结构
-
transformer是由谷歌在同样大名鼎鼎的论文《Attention Is All You Need》提出的,最基础的结构就是先Enoder编码再Decoder解码
-
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:
-
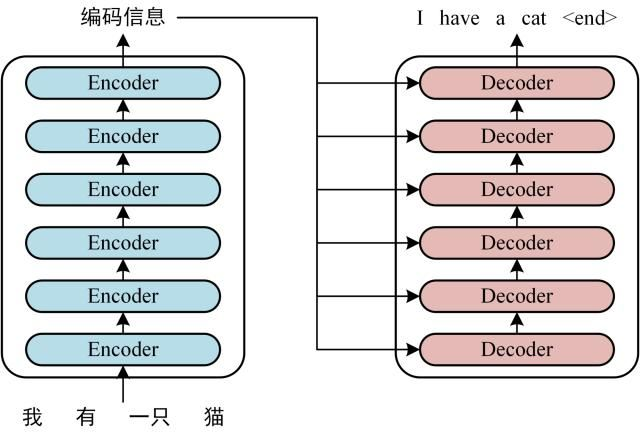
-
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
-
第一步:获取输入句子的每一个单词的表示向量 X
-
X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
-
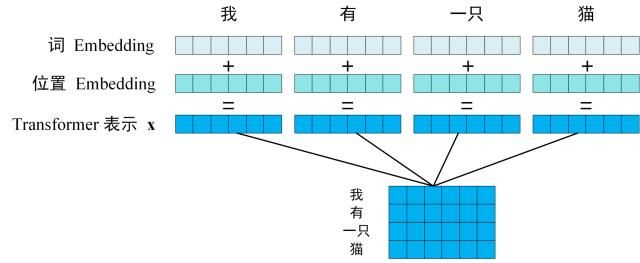
-
从上图可以看到,这个句子中是由单词组成的,每一个字都可以映射为一个内容Embedding以及一个位置Embedding,然后将这个内容Embedding和位置Embedding加起来,就可以得到这个词的综合Embedding了。
-
如上图所示,每一行是一个单词的表示 x
-
第二步:将得到的单词表示向量矩阵 传入 Encoder
-
每一行是一个单词的表示 x,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用X_nxd表示,n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入 完全一致。
-
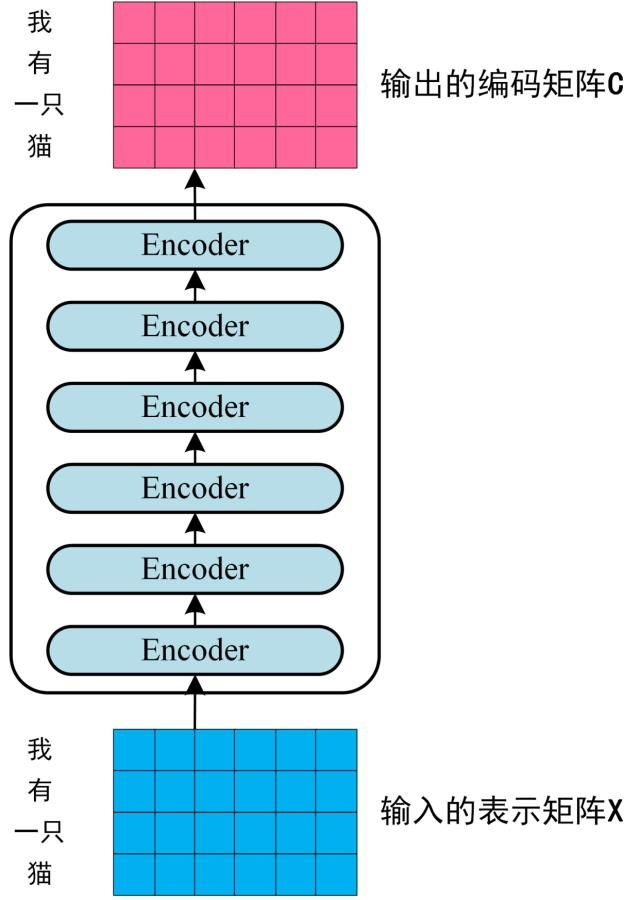
-
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中
-
Decoder 依次会根据当前已经翻译过的单词 i(I) 翻译下一个单词 i+1(have),如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
-
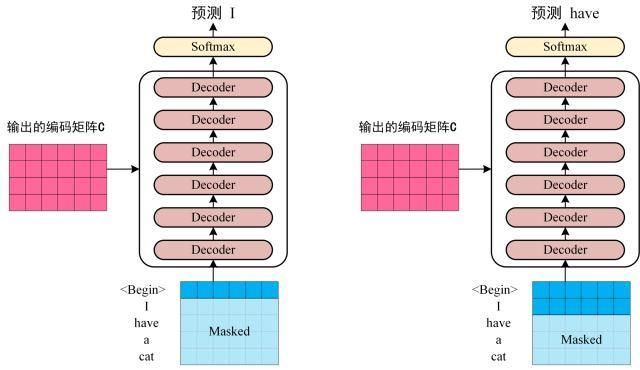
-
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,下一次预测的时候,用之前预测的结果作为输入,再得到对应的输出,以此类推。这是 **Transformer **使用时候的大致流程,无论再复杂的网络都是这个流程。
-
简单来理解的话,就是通过前I-1个词来预测第i个词,之后一直循环反复这个过程,直到预测出来了 结束符 截止。
3. 名词解释
3.1. token
- 在计算机科学中,token(符号)通常指代文本中的一组字符,它们被视为一个独立的单元,在进行文本分析和处理时被视为一个整体。
- 在自然语言处理中,token 通常指代单词、词组或其他文本中独立的语言单元。将文本分解为 token 的过程称为 tokenization(分词),是自然语言处理中的一个重要预处理步骤,为后续的文本分析和处理提供了基础。
- 一般情况下,对于英文来说,有几个单词就可以认为是有几个token
- 例如,对于英文句子 “I love natural language processing”,分词后得到的 token 序列为 [“I”, “love”, “natural”, “language”, “processing”]。
- 中文没有像英文那样明确的单词边界,因此需要对中文文本进行分词才能进行后续的文本分析和处理。
- 例如,对于中文句子 “我喜欢自然语言处理”,分词后得到的 token 序列为 [“我”, “喜欢”, “自然语言”, “处理”]。其中,“自然语言”是一个词组,在分词时被视为一个整体的 token。
- 在接下来的架构分析中, 我们将假设使用Transformer模型架构处理从一种语言文本到另一种语言文本的翻译工作, 因此很多命名方式遵循NLP中的规则. 比如: Embeddding层将称作文本嵌入层, Embedding层产生的张量称为词嵌入张量, 它的最后一维将称作词向量等.
4. transformer输入
- transformer这种网络其实并不能直接理解我们的自然语言,需要先对自然语言进行编码,编码成数字之后才可以大展身手。从这个角度来考虑,ChatGPT之类的模型,虽然神之又神,但其实上它背后进行的是一系列的数字数学运算,并不是真的理解了我们的自然语言。
- Transformer中单词的输入表示X是由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到,通常定义为 Transformer Embedding 层。
4.1. 单词 Embedding
- 单词的Embedding有很多方法可以获取,例如可以采用Word2Vec、Glove等算法预训练得到,也可以在Transformer中训练得到
- 输入:[N, seq_len]
[N,seq_len],即N个句子(batch size),每个句子包含seq_len个token(一般情况下,对于英文来说,有几个单词就可以认为是有几个token),由于每个句子长短不一,选择最长的句子作为base seq_len,剩下余部分可以用特殊字符(例如0、1)来填充,token用其在vocab中的序号表示。
也就是N条句子,以最长句子的长度最为基准,其他句子均进行长度补齐。
例如下面的代码,前面的[2, 2571, 57, 11, 48, 26, 733, 11, 46, 62, 11, 90, 297, 5, 3,]列表代表这个句子中对单词的编码,后面的全1矩阵[1,1,…1,1]就代表向最长句子的padding填充了
for i, batch in enumerate(iterator):
src = batch.src
print(src.shape) 128 ,40
print(src[0])
[ 2, 2571, 57, 11, 48, 26, 733, 11, 46, 62, 11, 90,
297, 5, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1]
- 输出:[N, seq_len, d_model]
d_model表示词向量的维度,它是 Transformer 模型中的一个重要参数。在 Transformer 模型中,输入序列的每个单词都会被转换成一个 d _ m o d e l d\_model d_model 维的向量表示(而非one_hot编码),这个向量表示包含了该单词的语义信息。
假设我们有一个词汇表,其中包含了 10,000 个单词。我们使用 one-hot 编码将每个单词转换成一个长度为 10,000 的向量表示,那么每个单词的向量是一个稀疏向量 ,其中只有一个元素是 1,其余元素都是 0。这种表示方式存在的问题是,向量维度非常高,而且向量之间的距离无法直接反映单词之间的语义关系。
为了解决这个问题,我们可以使用词嵌入将每个单词转换成一个低维稠密向量表示。假设我们使用的词嵌入模型是一个浅层的前馈神经网络,输入是一个 one-hot 向量,输出是一个 4 维的向量表示,那么每个单词的向量表示如下所示:
-
单词 “car”: [ 0.1 0.2 0.3 0.4 ] \begin{bmatrix} 0.1 & 0.2 & 0.3 & 0.4 \end{bmatrix} [0.10.20.30.4]
-
单词 “bus”: [ 0.2 0.3 0.4 0.5 ] \begin{bmatrix} 0.2 & 0.3 & 0.4 & 0.5 \end{bmatrix} [0.20.30.40.5]
-
单词 “train”: [ 0.3 0.4 0.5 0.6 ] \begin{bmatrix} 0.3 & 0.4 & 0.5 & 0.6 \end{bmatrix} [0.30.40.50.6]
在这个例子中, d _ m o d e l = 4 d\_model=4 d_model=4,这意味着每个单词的向量表示只有 4 个元素。这种低维稠密表示方式不仅可以减少向量维度,还可以保留一些单词之间的语义关系,比如 “car” 和 “bus” 的向量在某些维度上比较接近,而和 “train” 的向量比较远。这种语义关系可以帮助模型更好地理解文本数据,从而提高任务的性能。
d _ m o d e l d\_model d_model 的大小通常是根据任务的复杂度和计算资源来决定的。如果任务比较简单,或者计算资源有限,我们可以使用较小的 d _ m o d e l d\_model d_model 值;如果任务比较复杂,或者计算资源充足,我们可以考虑使用较大的 d _ m o d e l d\_model d_model 值。需要注意的是, d _ m o d e l d\_model d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









