




在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引分类:
从数据结构角度来分
btree 索引
hash索引
Btree索引:
当人们谈论索引,如果没有指明类型,多半是B-Tree索引,它使用B-Tree数据结构来存储数据。
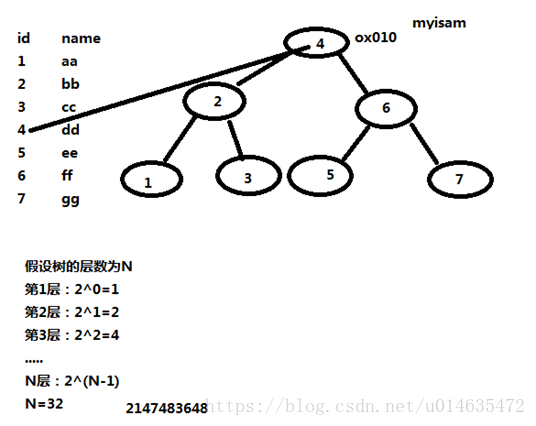
21亿数据只需要查找32次,相对于21亿次快了很多。
hash索引:
基于哈希表实现,对于每一行数据,存储引擎会计算一个哈希码,哈希码存储在索引中,哈希表保存指向每个数据行的指针。
速度快,一次计算 就可以取到数据
1.只能用于memory存储引擎
memory表存储引擎,是内存表存储引擎,他会把表的数据全部放到内存中。
mysql重启之后,会全部清空。
原理图:
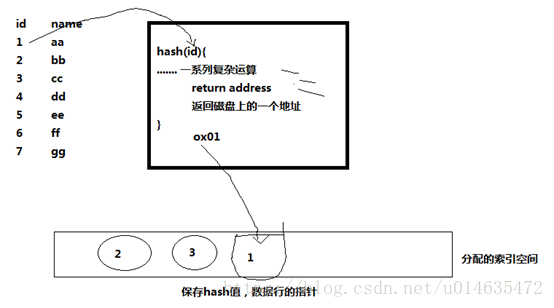
hash索引缺点:
1. 通过hash函数算出来的地址可能会产生冲突,此时mysql通过链表的方式来解决这种冲突数据,维护索引字段的值就比较麻烦,代价比较高
2. hash索引数据没有顺序的,因为hash函数算出来的值的排序不是顺序的,他会产生空间碎片
3. hash索引只支持等值比较(in , = , <=>)查询,不适合范围查找
4. 无法使用最左前缀原则,例如:hash索引(col1,col2,col3),如果where条件中,只包含col1字段,是无法用上索引的,因为两次计算的hash值都不一样,所以用不上hash索引
5. col like ‘abc%’ 在hash索引中用不上索引
自适应哈希索引:
InnoDB引擎有一个特殊的功能叫做自适应哈希索引。当InnoDB注意到某些索引值被使用得非常频繁时,它会在内存中基于B-Tree索引之上再创建一个哈希索引。
插入的时候,利用触发器生成哈希值。
查询的时候因为有哈希冲突的问题,必须包含常量。

CRC32是计算哈希值的。
索引的优点:
提高检索速度,降低磁盘读取IO
索引是排序好的,降低了数据排序的运算成本,也就是降低了CPU的消耗
索引的缺点:
索引也需要存储,所以也需要空间,实际上索引也是一张表,保存了索引字段的值和指向实体表的指针。
降低更新表的速度,更新不仅仅只是数据本身,如果数据正好是索引字段,同时需要更新索引信息。
哪些情况下适合建索引
1. 频繁作为where条件语句查询的字段
2. 关联字段需要建立索引,例如外键字段,student表中的classid, classes表中的schoolid 等
3. 排序字段可以建立索引
4. 分组字段可以建立索引,因为分组的前提是排序
5. 统计字段可以建立索引,例如count(),max()
哪些情况下不适合建索引
1.频繁更新的字段不适合建立索引,比如登录次数
2.where条件中用不到的字段不适合建立索引
3.表数据可以确定比较少的不需要建索引
4.数据重复且发布比较均匀的的字段不适合建索引(唯一性太差的字段不适合建立索引),例如性别,真假值
5. 参与列计算的列不适合建索引
参考
1.young
2.《MySQL高性能3》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









