




 本文详细介绍如何在SparkStandalone模式下使用Zookeeper实现SparkHA,通过配置SPARK_DAEMON_JAVA_OPTS参数,确保在Master故障时能快速切换,保持集群稳定运行。
本文详细介绍如何在SparkStandalone模式下使用Zookeeper实现SparkHA,通过配置SPARK_DAEMON_JAVA_OPTS参数,确保在Master故障时能快速切换,保持集群稳定运行。
Spark HA搭建
Spark Standalone和大部分Master/slave模式一样,都存储Master单点故障问题,解决方式可以基于Zookeeper实现两个Master无缝切换,类似HDFS的NameNode HA(High Availability,高可用)或者YARN的ResourceManager HA。
Spark可以在集群中启动多个Master,并使它们都向Zookeeper进行注册,Zookeeper利用自己的选举机制保证同一时间只有一个Master是活动状态(active)的,其他的都是备用状态(standby)。
当活动状态的Master出现故障时,Zookeeper会从其他备用状态的Master选出一台成为活动的Master,整个恢复过程大约在1分钟。对应恢复期间正在运行的程序,由于应用程序在运行前已经向Master申请了资源,运行是Driver负责与Excecutor进行通讯,管理整个应用程序,因此Master的故障对应用程序的运行不会产生影响,但是会影响新应用程序的提交。
以Spark Standalone模式的client运行方式为例,其HA的架构
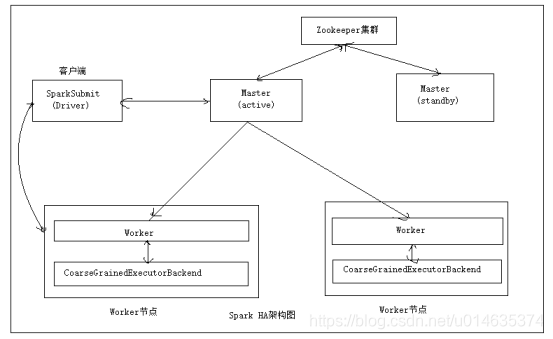
接下来我们安装已经搭建好的Spark Standalone集群进行Spark HA的搭建,搭建的角色分配如下 Spark HA集群角色分配
| 节点 |
角色 |
| centoshadoop1 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









