




 VGG网络在Alexnet基础上发展,采用3*3小卷积核,深度达16-19层,展示良好泛化能力。输入为224*224 RGB图像,预处理仅减去RGB均值。使用1*1卷积增强非线性度,不改变感受野。网络由五组卷积和池化层组成,后接三层全连接层。
VGG网络在Alexnet基础上发展,采用3*3小卷积核,深度达16-19层,展示良好泛化能力。输入为224*224 RGB图像,预处理仅减去RGB均值。使用1*1卷积增强非线性度,不改变感受野。网络由五组卷积和池化层组成,后接三层全连接层。
VGG总结
- 简介
VGG是在Alexnet基础上发展来的,主要贡献是,使用非常小的conv(3*3)进行网络设计。将深度增加到了16-19层。具有很好的泛化能力。
- 网络结构
训练时,输入是大小为224*224的RGB图像,预处理只有在训练集中的每个像素上减去RGB的均值。
在conv中使用了非常小的感受野(recrption field):3*3,下图中网络结构C中,使用了1*1的卷积大小,该结构(1*1卷积)可以被看做是对输入通道的线性变换,同时不改变输入通道和大小,以此来增加决策函数的非线性度。
相关参数设置:stride=1(步长);padding=1;pooling:5个max pooling,(放在部分conv后,vgg分5块conv,max pooling放在每块conv后,所以不是每个conv后都加pooling),size=2,stride=2。
最后接三层fc,前两个fc有4096个通道,第三个fc有1000个通道,用来分类。
所有隐藏层都是用了RELU。VGG不使用局部响应归一化(LRN),LRN虽然可以提升一些性能,但会导致过多的内存消耗和计算时间。现在基本使用BN。
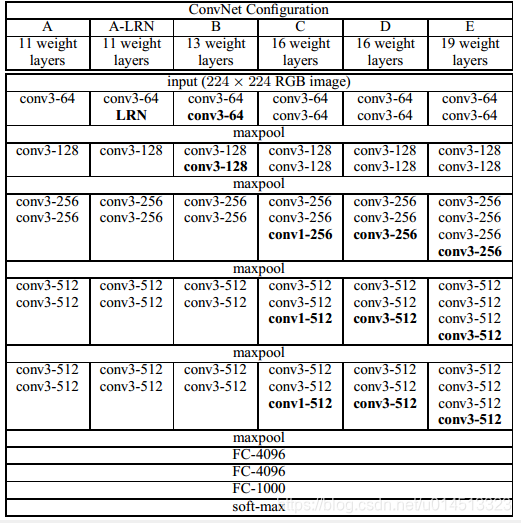
从图看出,网络A-E,卷积层通道数从64到512,每经过一次pooling操作扩大一倍。
- 讨论
与AlexNet和ZFNet不同,VGGNet在网络中使用很小的卷积。AlexNet和ZFNet在第一个卷积层的卷积分别是11*11 with stride 4和7*7 with stride 2。VGGNet则使用3*3的卷积。
两个连续的3*3卷积相当于原来5*5的感受野,三个3*3相当于一个7*7。使用三个3*3而不是一个7*7的优势:
- 包含三个RELU层而不是一个,使决策函数更有判别性;
- 减少参数。比如输入输出都是C个通道,使用3个3*3的conv需要(3*3*C*C)=27*C*C,使用7*7的1个conv则需要7*7*C*C=49*C*C。这可以看做是对7*7施加一个正则化,使它分解成3个3*3的卷积。
1*1卷积主要为了增加决策函数的非线性度,而不影响conv的感受野。虽然1*1的卷积操作是线性的,但是Relu增加了非线性。
- 其他
在测试阶段,将第一个fc转换成7*7conv,后两个fc转换成1*1的conv。结果就是一个类别分数图(class score map),为了获得固定尺寸的类别分数向量,对类别分数图进行空间平均化处理(sum-pooled)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









